 Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy
Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy





Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy


-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-
Categoria: Tutorials
Introduzione alla logica degli oggetti - Lezione 5
![]() Gino Visciano |
Gino Visciano |
 Skill Factory - 24/11/2018 14:02:07 | in Tutorials
Skill Factory - 24/11/2018 14:02:07 | in Tutorials
Nelle lezioni precedenti abbiamo parlato di Polimorfismo dei metodi, definendo l'Overload lezione 3 e l'Override lezione 4, in questa lezione parleremo di Polimorfismo degli oggetti.
Iniziamo intanto a dire che due oggetti si dicono Polimorfi se sono simili. Gli oggetti diventano simili quando si verifica uno dei seguenti casi:
1) una classe eredita un'altra classe;
2) più classi implementano la stessa interfaccia.
Nell'esempio seguente, le classi Persona, Dipendente, Manager e Dirigente, sono simili perché si ereditano tra loro:
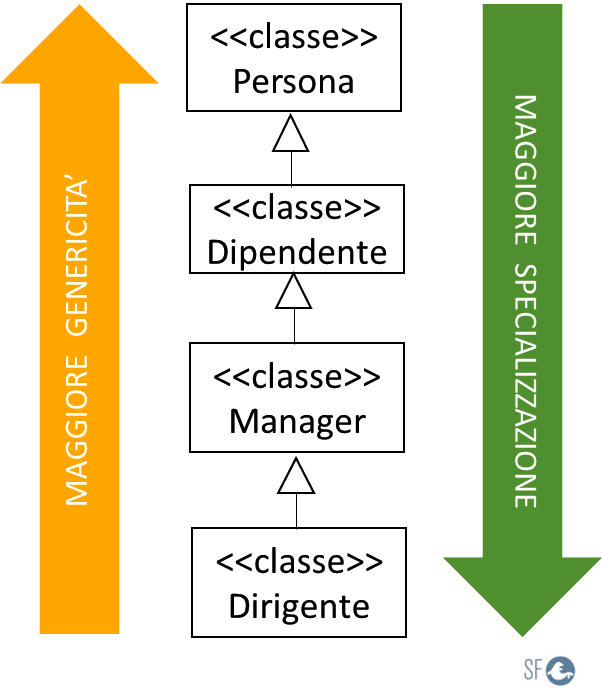
La classe Persona è la più generica, mentre la classe Dirigente è la più specializzata.
Nell'esempio seguente, le classi Rettangolo, Triangolo e Cerchio sono simili perché implementano la stessa interfaccia:
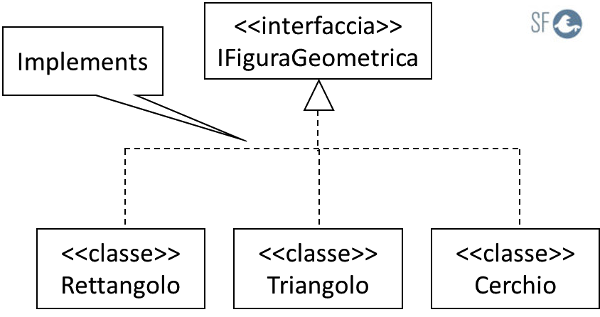
In C++ l'ereditarietà è multipla, quindi le interfacce non esistono, al loro posto si usano le classi astratte, il polimorfismo basto sulle intefacce esiste solo in linguaggi di programmazione come Java e C#, dove l'ereditarietà è singola e le interfacce si usano per superare questo limite.
Quando gli oggetti sono simili, diventano possibili operazioni di questo tipo:
Persona *dirigente=new Dirigente();
oppure
IFiguraGeometrica *triangolo=new Triangolo();
Nel primo esempio abbiamo istanziato un oggetto di tipo Dirigente, ma la variabile (puntatore) che contiene l'indirizzo dell'oggetto creato è di tipo Persona, un tipo molto più generico.
Nel secondo esempio abbiamo istanziato un oggetto di tipo Triangolo, ma la variabile (puntatore) che contiene l'indirizzo dell'oggetto creato è di tipo IFiguraGeometrica, che corrisponde ad una interfaccia oppure una classe astratta.
Questa proprietà degli oggetti simili è molto utile quando volete passare allo stesso metodo oggetti simili;
COME PASSARE OGGETTI SIMILI AD UN METODO
Il Polimorfismo degli oggetti permette di passare oggetti simili allo stesso metodo, per evitare di creare un metodo per ogni tipo di oggetto da gestire.
Immaginate di voler stampare gli attributi di più oggetti di tipo diverso: Dipendente, Manager e Dirigente.
Senza il polimorfismo dovremmo creare tre metodi diversi:
stampaDipendente(Dipendente dipendente);
stampaManager(Manager manager);
stampaDirigente(Dirigente dirigente);
Invece, sfruttando il polimorfismo, possiamo creare un unico metodo a cui passiamo tutti e tre i tipi di oggetti simili, basta indicare come argomento il tipo più generico, che in questo caso è il Dipendente:
stampa(Dipendente dipendente);
questa sarebbe una semplificazione importante per chi deve stampare, perché dovrebbe ricordare il nome di un solo metodo anzicché tre nomi diversi.
Naturalmente il metodo stampa dovrà essere implementato in modo che riconosca quali sono i tipi di oggetti passati come argomenti e stamaprli in modo corretto.
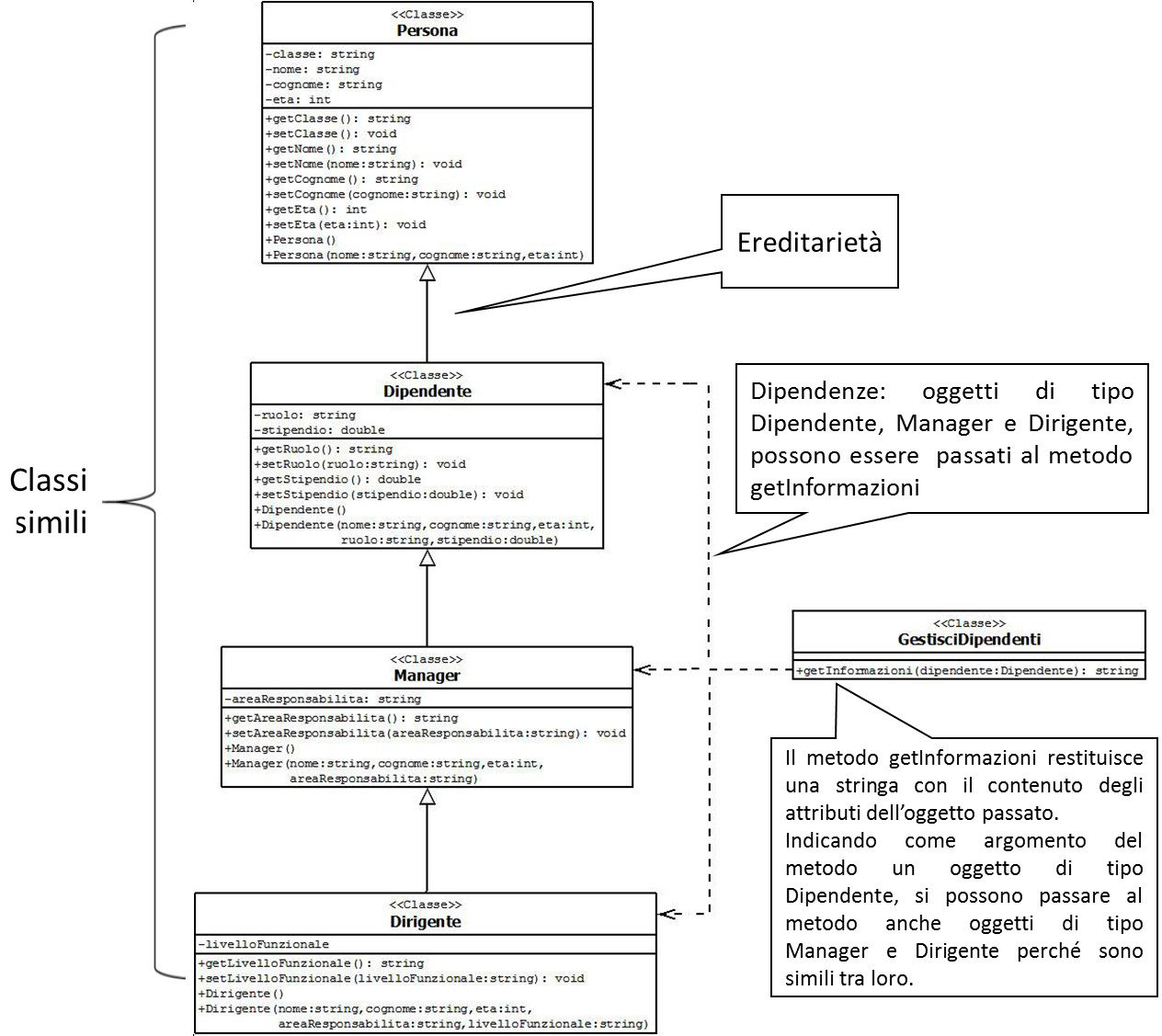
L'esempio seguente mostra come creare il metodo getInformazioni con C++:
#include <string>
#include <iostream>
#include <sstream>
#include <typeinfo>
using namespace std;
class Persona {
private:
string classe;
string nome;
string cognome;
int eta;
public:
void setNome(string nome){
this->nome=nome;
};
void setCognome(string cognome){
this->cognome=cognome;
};
void setEta(int eta){
this->eta=eta;
};
string getNome(){
return nome;
}
string getCognome(){
return cognome;
}
int getEta(){
return eta;
}
// getClasse() restituisce il tipo di classe dell'oggetto corrente
string getClasse(){
return this->classe;
}
/******
setClasse() imposta l'attributo classe uguale al tipo di classe corrente, usando la funzione typeid(*this).name().
*this è il puntatore che identifica l'oggetto corrente, setClasse() deve essere virtuale perchè se viene
ereditato ,quando è invocato dalla classe derivata, deve comportarsi come se appartenesse ad essa, altrimenti
il tipo restituito da setClasse() è sempre quello della classe più generica in cui è stato implementato.
******/
virtual void setClasse(){
this->classe=typeid(*this).name();
}
Persona(){
setClasse();
};
Persona(string nome, string cognome, int eta){
this->nome=nome;
this->cognome=cognome;
this->eta=eta;
setClasse();
}
};
// La classe Dipendente eredita la classe Persona e diventano simili
class Dipendente : public Persona {
private:
string ruolo;
double stipendio;
public:
void setRuolo(string ruolo){
this->ruolo=ruolo;
};
string getRuolo(){
return ruolo;
}
void setStipendio(double stipendio){
this->stipendio=stipendio;
};
double getStipendio(){
return stipendio;
}
Dipendente(){
setClasse(); // Ereditato dalla classe Persona, assegna all'attributo classe il tipo Dipendente
};
Dipendente(string nome, string cognome, int eta, string ruolo, double stipendio):Persona(nome, cognome, eta){
this->ruolo=ruolo;
this->stipendio=stipendio;
setClasse(); // Ereditato dalla classe Persona, assegna all'attributo classe il tipo Dipendente
}
};
// La classe Manager eredita la classe Dipendente e diventano simili, quindi per la proprietà transitiva Manager e simile anche a Persona
class Manager : public Dipendente {
private:
string areaResponsabilita;
public:
void setAreaResponsabilita(string areaResponsabilita){
this->areaResponsabilita=areaResponsabilita;
};
string getAreaResponsabilita(){
return areaResponsabilita;
}
Manager(){
setClasse();
};
Manager(string nome, string cognome, int eta, string ruolo, double stipendio, string areaResponsabilita):
Dipendente(nome, cognome, eta, ruolo, stipendio){
this->areaResponsabilita=areaResponsabilita;
setClasse();
}
};
// La classe Dirigente eredita la classe Manager e diventano simili, quindi per la proprietà transitiva Dirigente e simile anche a Dipendente e Persona
class Dirigente : public Manager {
private:
string livelloFunzionale;
public:
void setLivelloFunzionale(string livelloFunzionale){
this->livelloFunzionale=livelloFunzionale;
};
string getLivelloFunzionale(){
return livelloFunzionale;
}
Dirigente(){
setClasse(); // Ereditato dalla classe Persona, assegna all'attributo classe il tipo Manager
};
Dirigente(string nome, string cognome, int eta, string ruolo, double stipendio, string areaResponsabilita,string livelloFunzionale):
Manager(nome, cognome, eta, ruolo, stipendio,areaResponsabilita){
this->livelloFunzionale=livelloFunzionale;
setClasse(); // Ereditato dalla classe Persona, assegna all'attributo classe il tipo Manager
}
};
class GestisciDipendenti {
public:
// Il Metodo getInformazioni può ricevere come argomento oggetti di tipo Dipendente oppure oggetti simili di tipo Manager o Dirigente
string getInformazioni(Dipendente *dipendente){
string infoPersona="";
stringstream sEta;
stringstream sStipendio;
string strEta,strStipendio;
sEta << dipendente->getEta();
sStipendio << dipendente->getStipendio();
strEta=sEta.str();
strStipendio=sStipendio.str();
// Se il puntatore *dipendente è di tipo Dirigente esegue uno static_cast a Dirigente e assegna all'attributo infoPersona le informazioni del Dirigente
if(dipendente->getClasse()==typeid(Dirigente).name()){
Dirigente *dirigente;
dirigente=static_cast<Dirigente *>(dipendente);
infoPersona = dirigente->getNome()+","+dirigente->getCognome()+","+strEta+","+dirigente->getRuolo()+","+strStipendio+","+
dirigente->getAreaResponsabilita()+","+dirigente->getLivelloFunzionale();
// Se il puntatore *dipendente è di tipo Manager esegue uno static_cast a Manager e assegna all'attributo infoPersona le informazioni del Manager
} else if(dipendente->getClasse()==typeid(Manager).name()){
Manager *manager;
manager=static_cast<Manager *>(dipendente);
infoPersona = manager->getNome()+","+manager->getCognome()+","+strEta+","+manager->getRuolo()+","+strStipendio+","+
manager->getAreaResponsabilita();
// Se il puntatore *dipendente è di tipo Dipendente assegna all'attributo infoPersona le informazioni del Dipendente
} else{
infoPersona = dipendente->getNome()+","+dipendente->getCognome()+","+strEta+","+dipendente->getRuolo()+","+strStipendio;
}
return infoPersona;
}
};
int main(){
// Istanzio oggetto di tipo Dipendente
Dipendente *dipendente=new Dipendente("Marco","Rossi",30,"Programmatore",100.58);
// Istanzio oggetto di tipo Manager
Manager *manager=new Manager("Franco","Verdi",50,"Direttore Generale",200.58,"CED");
// Istanzio oggetto di tipo Dirigente
Dirigente *dirigente=new Dirigente("Carlo","Bianchi",50,"Direttore Generale",200.58,"CED","F3");
// Istanzio oggetto di tipo GestisciDipendenti che contiene il metodo getInformazioni
GestisciDipendenti *gd=new GestisciDipendenti();
// Dato che gli oggetti di tipo Dipendente, Manger e Dirigente sono Polimorfi (simili), possono essere passati al metodo getInformazioni impostando come
// argomento del metodo il tipo più generico dei tre, il Dipendente: getInformazioni(Dipendente *dipendente)
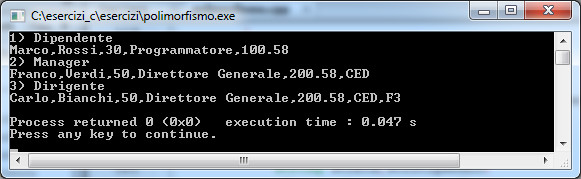
cout << "1) Dipendente" <<endl;
cout << gd->getInformazioni(dipendente) << endl;
cout << "2) Manager" <<endl;
cout << gd->getInformazioni(manager) << endl;
cout << "3) Dirigente" << endl;
cout << gd->getInformazioni(dirigente) << endl;
}
COME CREARE OGGETTI SIMILI ATTRAVERSO L'UTILIZZO D'INTERFACCE O CLASSI ASTRATTE
Le interfacce e le classi astratte sono strutture di programmazione simili, perché entrambe contengono metodi astratti (non impelmentati) e non possono istanziare oggetti.
Le differenze principali tra loro sono due:
1) le classi astratte possono contenere anche metodi già implementati, come le normali classi, le interfacce no, a meno che non state usando Java 8 che permette d'implementare nelle interfacce anche metodi statici o di default;
2) le classi astratte si ereditano, mentre le interfacce s'implementano.
L'uso delle interfacce in alcuni linguaggi di programmazione ad oggetti come Java e C#, è necessario per superare il limite dell'ereditarietà è singola, che non permette di ereditare più classi contemporaneamente, mentre non è necessario in linguaggi di programmazione ad oggetti dove l'ereditarietà è multipla, come in C++.
In realtà le classi astratte sono pattern (soluzioni applicative), che permettono di creare metodi che usano il risultato di altri metodi, detti astratti, la cui logica (comportamento) verrà implementata in futuro in una classe derivata.
Oggetti che ereditano la stessa classe astratta oppure implementano la stessa interfaccia diventano polimorfi, cioè simili.
Immaginate di voler creare un'applicazione specializzata per calcolare il perimetro e l'area delle seguenti figure geometriche:

Le quattro figure geometriche sono simili perché hanno in comune le seguenti caratteristiche:
1) corrispondono tutte ad un tipo di figura geometrica;
2) hanno tutte due coordinate x ed y che identificano la posizione in un piano bidimensionale;
3) hanno tutte un colore;
4) hanno tutte un perimetro ed un'area, che vengono calcolati diversamente per ogni tipo di figura geometrica, quindi devono essere implementati nelle classi di riferimento.
Tutte queste caratteristiche comuni possono essere raggruppate in una classe astratta come mostra il Diagramma di Classe seguente:

Successivamente la classe astratta FiguraGeometrica può essere ereditata dalle classi derivate Quadrato, Rettangolo, Triangolo e Cerchio che diventano simili tra loro.
In queste classi dovranno essere implementati i metodi astratti perimetro ed area, come mostra il Diagramma di Classe seguente:
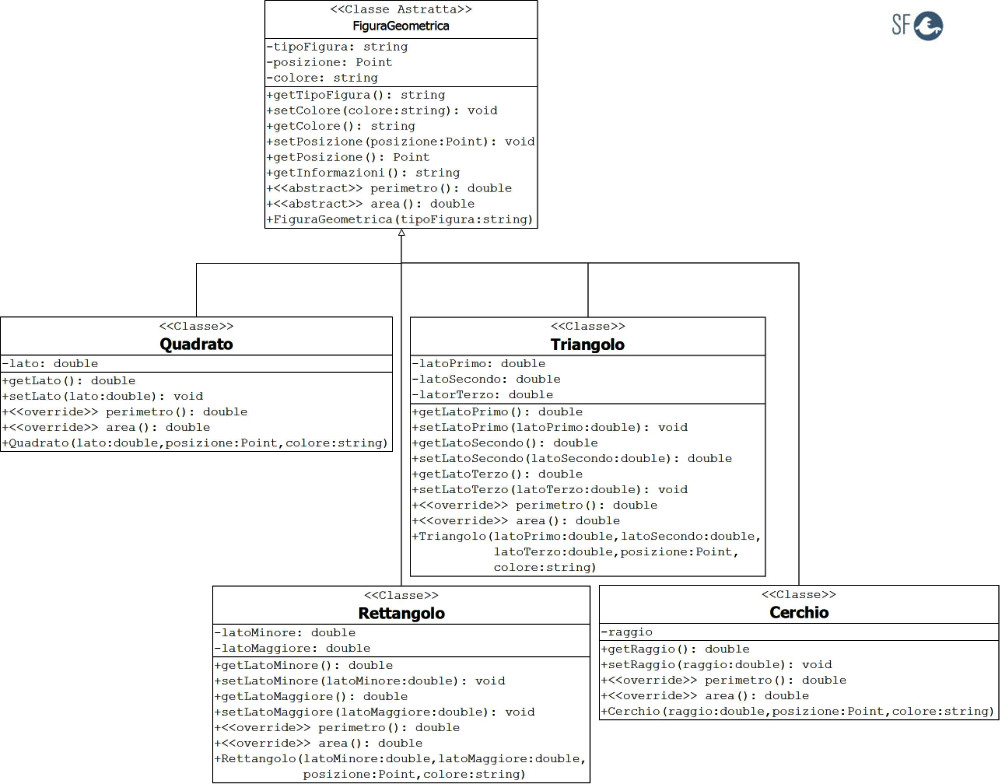
L'esempio seguente mostra come creare l'applicazione Geometria con C++, la classe FiguraGeometrica è una classe astratta che utilizza il metodo getInformazioni per restituire il perimetro e l'area delle figure geometriche istanziate.
Il metodo getInformazioni può usare i metodi perimetro ed area anche se non sono stati implementati perché sono astratti. Quando i due metodi verranno implementati nelle classi di riferimento forniranno il perimetro e l'area della figura geometrica corrente.
In C++ i metodi astrattti si dichiarano nel modo seguente:
virtual double perimetro()=0;
virtual double area()=0;
/*****************************
Applicazione Geometria.cpp
****************************/
#include <string>
#include <iostream>
#include <sstream>
#include <math.h>
using namespace std;
// Classe che permette di definire la posizione nel piano delle figure geometriche in base alle coordinate x ed y
class Point {
private:
int x,y;
public:
Point(int x, int y){
this->x=x;
this->y=y;
}
getX(){
return x;}
getY(){
return y;}
};
// Classe astratta che raggruppa la informazioni comuni a tutte le figure geometriche
class FiguraGeometrica {
private:
string tipoFigura;
Point *posizione;
string colore;
public:
string getTipoFigura(){
return tipoFigura;
}
Point * getPosizione(){
return posizione;
}
void setPosizione(Point *posizione){
this->posizione=posizione;}
string getColore(){
return colore;}
void setColore(string colore){
this->colore=colore;
}
string getInformazioni(){
stringstream sperimetro;
stringstream sarea;
stringstream sx;
stringstream sy;
sperimetro << perimetro(); // Utilizzo metodo astratto che verrà implementato successivamente nelle classi derivate
sarea << area(); // Utilizzo metodo astratto che verrà implementato successivamente nelle classi derivate
sx << posizione->getX();
sy << posizione->getY();
return tipoFigura+", posizione:"+sx.str()+", "+sy.str()+", "+colore+", perimetro:"+sperimetro.str()+", area:"+sarea.str();
}
virtual double perimetro()=0; // Metodo astratto
virtual double area()=0; // Metodo astratto
FiguraGeometrica(string tipoFigura,Point *posizione,string colore){
this->tipoFigura=tipoFigura;
this->posizione=posizione;
this->colore=colore;
}
};
// La classe Quadrato eredita la classe astratta FiguraGeometrica e diventa simile a tutte le altre classi che erediteranno questa classe.
class Quadrato: public FiguraGeometrica {
private:
double lato;
public:
double getLato(){
return lato;
}
void setLato(double lato){
this->lato=lato;
}
// Sovrascrittura del metodo perimetro richiamato dal metodo getInformazioni ereditato dalla classe FiguraGeometrica per ottenere il preimetro del Quadrato
double perimetro(){
return lato*4;}
// Sovrascrittura del metodo area richiamato dal metodo getInformazioni ereditato dalla classe FiguraGeometrica per ottenere l'area del Quadrato
double area(){
return pow(lato,2); // pow = potenza(base,esponete)
}
Quadrato(double lato,Point *posizione,string colore):FiguraGeometrica("Quadrato", posizione, colore){
this->lato=lato;
}
};
// La classe Rettangolo eredita la classe astratta FiguraGeometrica e diventa simile a tutte le altre classi che erediteranno questa classe.
class Rettangolo: public FiguraGeometrica {
private:
double latoMinore;
double latoMaggiore;
public:
double getLatoMinore(){
return latoMinore;
}
void setLatoMinire(double latoMinore){
this->latoMinore=latoMinore;
}
double getLatoMaggiore(){
return latoMaggiore;
}
void setLatoMaggiore(double latoMaggiore){
this->latoMaggiore=latoMaggiore;
}
// Sovrascrittura del metodo perimetro richiamato dal metodo getInformazioni ereditato dalla classe FiguraGeometrica per ottenere il preimetro del Rettangolo
double perimetro(){
return (latoMinore+latoMaggiore)*2;}
// Sovrascrittura del metodo area richiamato dal metodo getInformazioni ereditato dalla classe FiguraGeometrica per ottenere l'area del Rettangolo
double area(){
return latoMinore*latoMaggiore;
}
Rettangolo(double latoMinore,double latoMaggiore, Point *posizione,string colore):FiguraGeometrica("Rettangolo", posizione, colore){
this->latoMinore=latoMinore;
this->latoMaggiore=latoMaggiore;
}
};
// La classe Triangolo eredita la classe astratta FiguraGeometrica e diventa simile a tutte le altre classi che erediteranno questa classe.
class Triangolo: public FiguraGeometrica {
private:
double latoPrimo;
double latoSecondo;
double latoTerzo;
public:
double getLatoPrimo(){
return latoPrimo;
}
void setLatoPrimo(double latoPrimo){
this->latoPrimo=latoPrimo;
}
double getLatoSecondo(){
return latoSecondo;
}
void setLatoSecondo(double latoSecondo){
this->latoSecondo=latoSecondo;
}
double getLatoTerzo(){
return latoTerzo;
}
void setLatoTerzo(double latoTerzo){
this->latoTerzo=latoTerzo;
}
// Sovrascrittura del metodo perimetro richiamato dal metodo getInformazioni ereditato dalla classe FiguraGeometrica per ottenere il preimetro del Triangolo
double perimetro(){
return latoPrimo+latoSecondo+latoTerzo;
}
// Sovrascrittura del metodo area richiamato dal metodo getInformazioni ereditato dalla classe FiguraGeometrica per ottenere l'area del Triangolo
double area(){
// Formula di Erone
double semiPerimetro=perimetro()/2;
return sqrt(semiPerimetro*(semiPerimetro-latoPrimo)*(semiPerimetro-latoSecondo)*(semiPerimetro-latoTerzo));
}
Triangolo(double latoPrimo,double latoSecondo,double latoTerzo, Point *posizione,string colore):FiguraGeometrica("Triangolo", posizione, colore){
this->latoPrimo=latoPrimo;
this->latoSecondo=latoSecondo;
this->latoTerzo=latoTerzo;
}
};
// La classe Cerchio eredita la classe astratta FiguraGeometrica e diventa simile a tutte le altre classi che erediteranno questa classe.
class Cerchio: public FiguraGeometrica {
private:
double raggio;
public:
double getRaggio(){
return raggio;
}
void setRaggio(double raggio){
this->raggio=raggio;
}
// Sovrascrittura del metodo perimetro richiamato dal metodo getInformazioni ereditato dalla classe FiguraGeometrica per ottenere il preimetro del Cerchio
double perimetro(){
return raggio*M_PI*2;} // M_PI = PI GRECO
// Sovrascrittura del metodo area richiamato dal metodo getInformazioni ereditato dalla classe FiguraGeometrica per ottenere l'area del Cerchio
double area(){
return pow(raggio,2)*M_PI; // M_PI = PI GRECO, pow = potenza(base,esponete)
}
Cerchio(double raggio,Point *posizione,string colore):FiguraGeometrica("Cerchio", posizione, colore){
this->raggio=raggio;
}
};
int main() {
// Posizione Quadrato
Point *pointQuadrato=new Point(10,20);
// Quadrato(lato, posizione, colore)
Quadrato *quadrato=new Quadrato(25,pointQuadrato,"verde");
// Posizione Rettangolo
Point *pointRettangolo=new Point(60,80);
// Rettangolo(latoMinore, latoMaggiore, posizione, colore)
Rettangolo *rettangolo=new Rettangolo(25,40,pointRettangolo,"Blu");
// Posizione Trianangolo
Point *pointTriangolo=new Point(100,150);
// Triangolo(latoPrimo, latoSecondo, latoTerzo, posizione, colore)
Triangolo *triangolo=new Triangolo(40,30,20,pointTriangolo,"Rosso");
// Posizione Cerchio
Point *pointCerchio=new Point(100,150);
// Cerchio(lraggio, posizione, colore)
Cerchio *cerchio=new Cerchio(40,pointCerchio,"Grigio");
cout << quadrato->getInformazioni() << endl;
cout << rettangolo->getInformazioni() << endl;
cout << triangolo->getInformazioni() << endl;
cout << cerchio->getInformazioni() << endl;
}
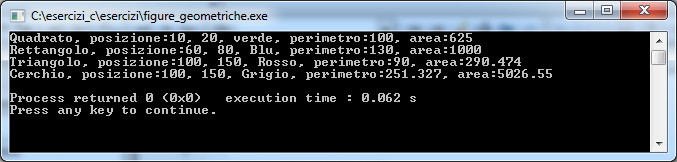
Nella prossima lezione parleremo di Collection.
<< Lezione precedente Lezione successiva >>
 Clicca qui per scaricare i laboratori di questa lezione (Per eseguire i laboratori installate Code Block sul vostro computer)
Clicca qui per scaricare i laboratori di questa lezione (Per eseguire i laboratori installate Code Block sul vostro computer)

Introduzione alla logica degli oggetti - Lezione 4
![]() Gino Visciano |
Skill Factory - 05/10/2018 22:44:13 | in Tutorials
Gino Visciano |
Skill Factory - 05/10/2018 22:44:13 | in Tutorials
In questa lezione parliamo di Ereditarietà, che insieme all'incapsulamento ed il polimorfismo, è uno dei più importanti paradigmi dell'Object Oriented.
CHE COS'E' L'EREDITARIETA'
L'ereditarietà è una tecnica di riuso del codice che permette di specializzare una classe già esistente, per crearne una nuova.
La nuova classe si chiama classe derivata, mentre la classe ereditata si chiama classe superiore, come mostra il diagramma UML seguente:
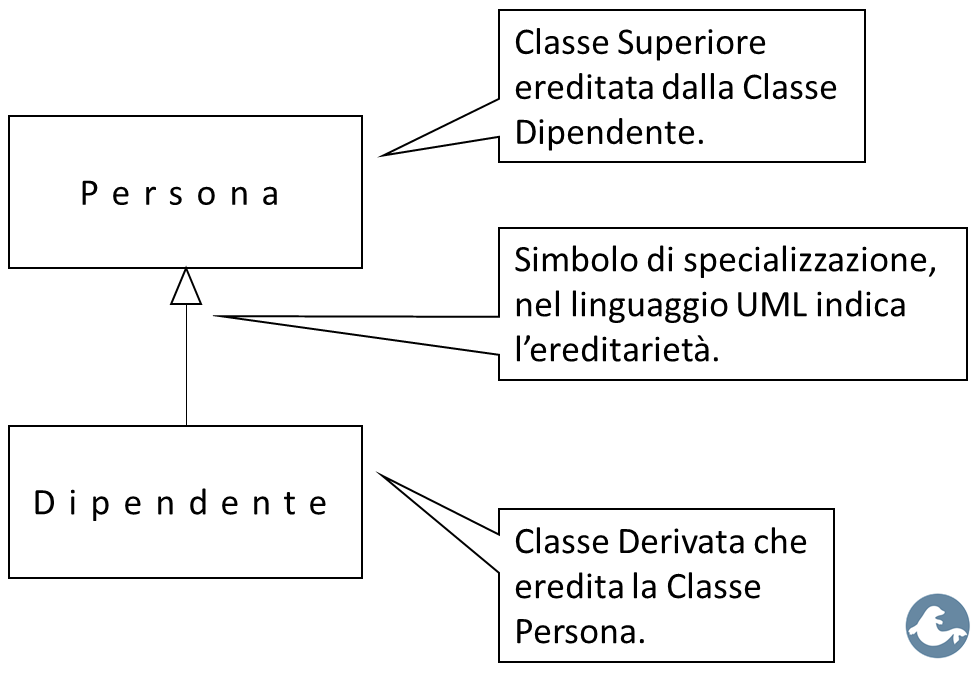
L'ereditarietà si dice singola se la classe derivata può ereditare una sola classe, mentre si dice multipla se la classe derivata può ereditare più classi contemporaneamente. Ad esempio il linguaggio C++ permette anche l'ereditarietà è multipla, mentre Java e C# permettono solo l'ereditarietà singola, il diagramma UML seguente mostra un esempio di ereditarietà è multipla:
Un classe Persona che contiene gli attributi seguenti: id, nome, cognome, dataDiNascita, luogoDiNascita e sesso, può essere specializzata in una classe Dipendente che, oltre agli altributi della classe Persona contiene anche gli attributi seguenti: stipendio e ruolo, come mostra il diagramma UML seguente:

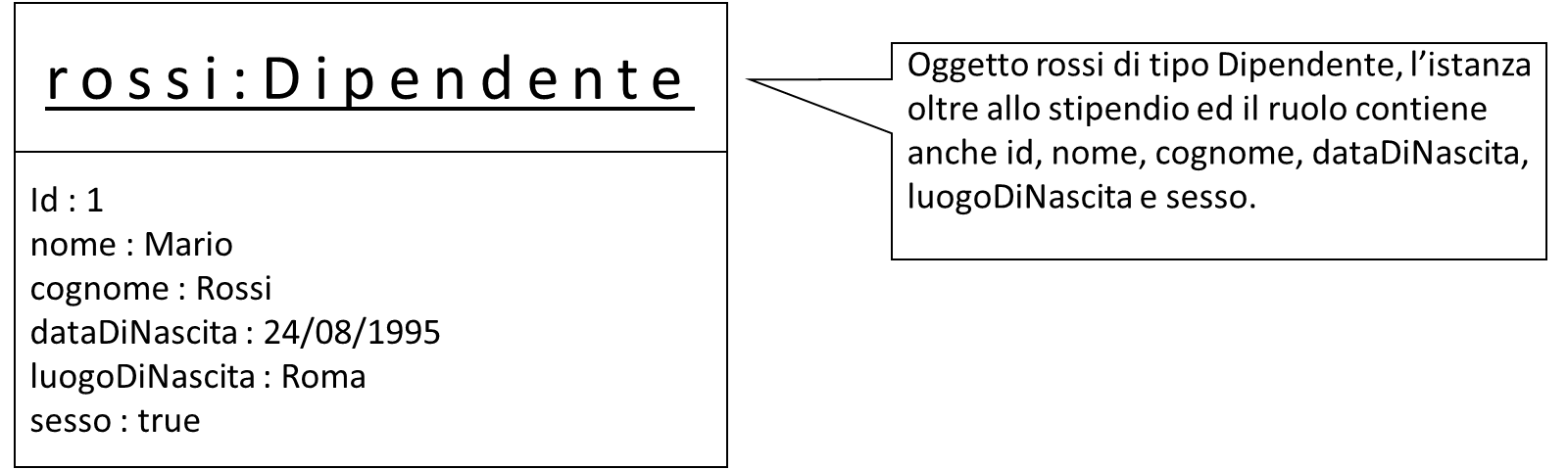
Con la classe Dipendete adesso si possono istanziare oggetti che oltre a contenere il ruolo e lo stipendio, contengono anche id, nome, cognome, dataDiNascita, luogoDiNascita e sesso, come mostra il diagramma UML seguente:
Di seguito implementiamo l'esempio appena visto con il linguaggio c++.
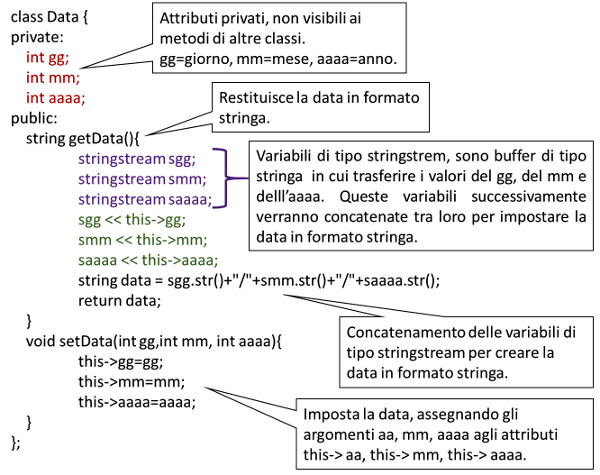
Prima di tutto creiamo una classe Data per gestire oggetti di tipo data, servirà in seguito per assegnare la data di nascita alla persona:
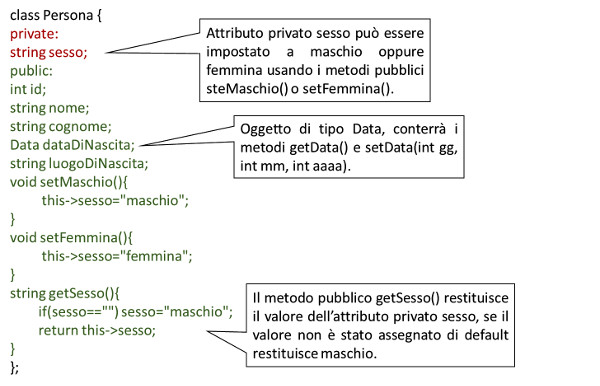
Adesso creiamo la classe Persona, che specializzaremo successivamente in Dipendente:
Infine creaiamo la classe Dipendente, che eredita la classe superiore Persona:

GESTIONE DEI COSTRUTTORI PARAMETRIZZATI
Se la classe superiore ha un costruttore parametrizzato, usato per inizializzare gli attributi, la classe derivata lo deve eseguire altrimenti non può funzionare correttamente.
Il diagramma UML seguente, mostra in che modo il costruttore della classe derivata esegue il costruttore parametrizzato della classe superiore:
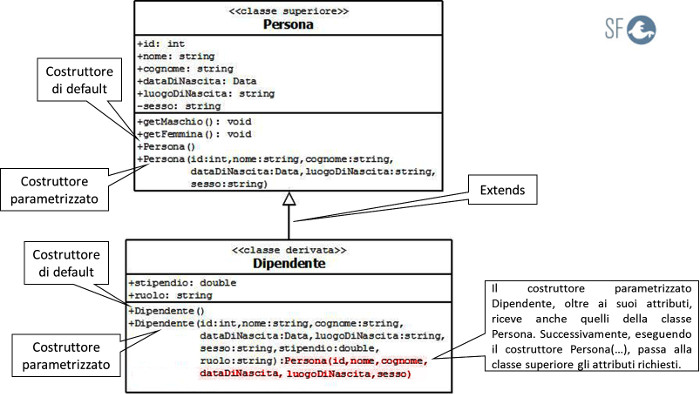
Vediamo lo stesso esempio scritto in linguaggio C++:
class Persona {
private:
string sesso;
public:
int id;
string nome;
string cognome;
Data *dataDiNascita;
string luogoDiNascita;
void setMaschio(){
this->sesso="maschio";
}
void setFemmina(){
this->sesso="femmina";
}
string getSesso(){
if(sesso=="") sesso="maschio";
return this->sesso;
}
Persona(){
this->dataDiNascita=new Data();
}
Persona(int id,string nome,string cognome, Data *dataDiNascita,string luogoDiNascita, string sesso){
if(sesso=="maschio")setMaschio();
else setFemmina();
this->dataDiNascita=new Data();
this->id=id;
this->nome=nome;
this->cognome=cognome;
this->dataDiNascita=dataDiNascita;
this->luogoDiNascita=luogoDiNascita;
}
};
class Dipendente : public Persona {
public:
double stipendio;
string ruolo;
Dipendente(){}
Dipendente(int id, string nome,string cognome, Data *dataDiNascita,string luogoDiNascita, string sesso, double stipendio, string ruolo):Persona(nome, cognome, dataDiNascita, luogoDiNascita, sesso){
this->stipendio=stipendio;
this->ruolo=ruolo;}
}
};
OVERRIDE (SOVRASCRITTURA) DI METODI EREDITATI DALLA CLASSE SUPERIORE
L'override è la tecnica che permette di sovrascrivere un metodo ereditato da una classe superiore per modificarne il comportamento all'interno della classe derivata. L'override, insieme all'overload può essere definito plimorfismo dei metodi.
Immaginiate di avere nella classe Persona il metodo getInformazioni() che restituisce i valori di tutti gli attributi della classe separti da una virgola. Se la classe Persona viene ereditata dalla classe Dipendente, questo metodo dovrà essere necessariamete sovrascritto altrimenti nell'elenco di attributi restituito mancherà lo stipendio ed il ruolo del Dipendente.
In C++ un metodo della della classe superiore per essere sovrascritto nella classe derivata, deve essere virtuale, come mostra l'esempio seguente:
class Persona {
private:
string sesso;
public:
int id;
string nome;
string cognome;
Data dataDiNascita;
string luogoDiNascita;
void setMaschio(){
this->sesso="maschio";
}
void setFemmina(){
this->sesso="femmina";
}
string getSesso(){
if(sesso=="") sesso="maschio";
return this->sesso;
}
// Metodo virtuale che verrà sovrascritto nella classe Dipendente
virtual string getInformazioni(){
return nome + ", "+cognome+", "+dataDiNascita.getData()+", "+luogoDiNascita+", "+sesso;
}
Persona(){
this->dataDiNascita=new Data();
}
Persona(int id,string nome,string cognome, Data *dataDiNascita,string luogoDiNascita, string sesso){
if(sesso=="maschio")setMaschio();
else setFemmina();
this->dataDiNascita=new Data();
this->id=id;
this->nome=nome;
this->cognome=cognome;
this->dataDiNascita=dataDiNascita;
this->luogoDiNascita=luogoDiNascita;
}
};
class Dipendente : public Persona {
public:
double stipendio;
string ruolo;
// Sovrascrittura del Metodo getInformazioni ereditato dalla classe Persona
string getInformazioni(){
// Conversione double in stringa
stringstream strStipendio;
strStipendio << this->stipendio;
return nome + ", "+cognome+", "+dataDiNascita.getData()+", "+luogoDiNascita+", "+getSesso()+", "+strStipendio.str()+", "+ruolo;
}
Dipendente(){}
Dipendente(int id,string nome,string cognome, Data *dataDiNascita,string luogoDiNascita, string sesso, double stipendio, string ruolo):
Persona(id, nome, cognome, dataDiNascita, luogoDiNascita, sesso){
this->stipendio=stipendio;
this->ruolo=ruolo;}
};
INCAPSULAMENTO DEGLI ATTRIBUTI E DEI METODI DI UNA CLASSE IN CASO DI EREDITARIETA'
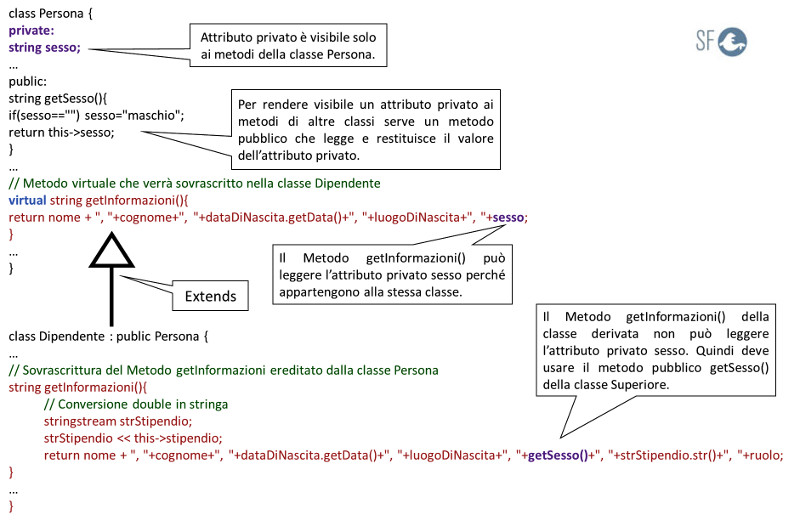
Nell'esempio precedente, quando viene sovrascritto il metodo getInformazioni() della classe Dipendente, l'attributo sesso è stato sostituito dal metodo getSesso().
Questa operazione è necessaria perché l'attributo sesso della classe Persona è privato. Gli elementi privati di una classe sono visibili solo ai metodi della stessa classe, mentre non sono visibili in alcun caso ai metodi di altre classi.
In questo caso, sovrascrivendo il metodo getInformazioni() nella classe Dipendente, diventa un metodo esterno alla classe superiore e non può più vedere l'attributo sesso.
Il metodo getInformazioni() della classe Dipendente, per leggere il valore dell'attributo sesso, lo può fare solo attraverso il metodo getSesso() della classe Persona perchè è pubblico, come mostra l'immagine seguente:
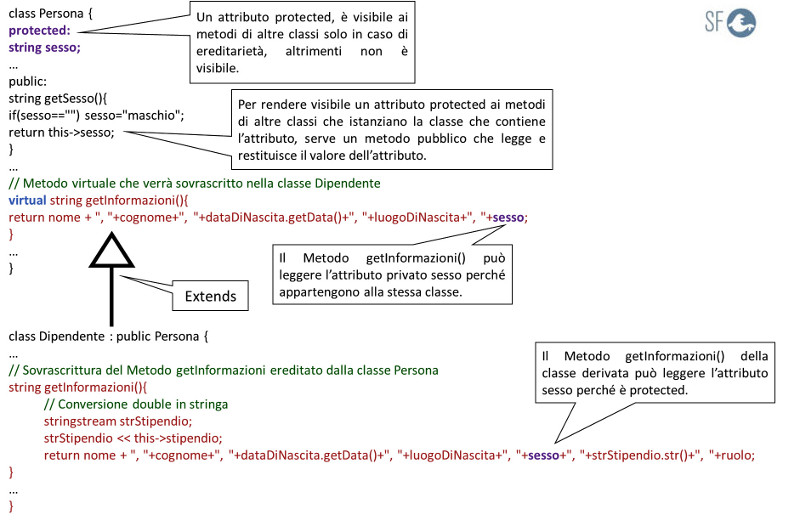
Per poter usare direttamente l'attributo sesso nel metodo getInformazioni() della classe Dipendente, bisogna impostarlo protected, come mostra l'immagine seguente:
Per chiarire meglio il ruolo dei modificatori di accesso approfondiamo insieme il diagramma UML seguente:
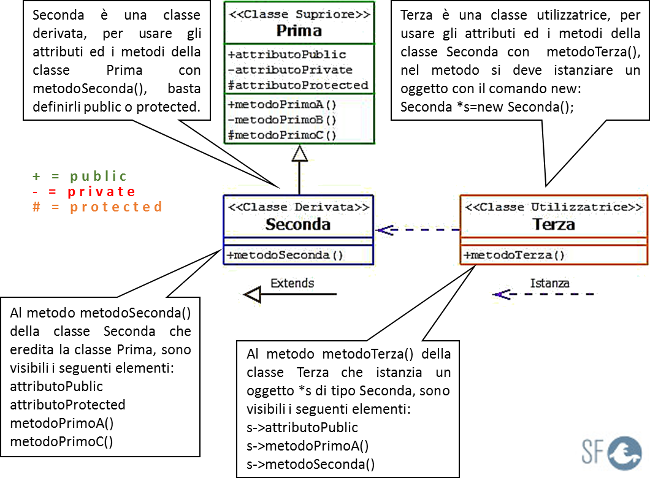
Osservando il diagramma si capisce che una classe derivata che eredita una classe superiore, può usare attraverso un metodo, senza istanziare, tutti i suoi elementi pubblici e protetti.
Infatti il metodo metodotSeconda() della classe Seconda vede:
attributoPublic;
attributoProtected;
metodoPrimoA();
metodoPrimoC().
Mentre non vede l'attributoPrivate perché è privato. Se fosse necessario accedere a questo attributo lo potrebbe fare solo attraverso l'uso dei metodi:
metodoPrimoA();
metodoPrimoC().
Invece una classe utilizzatrice, per usare attraverso un suo metodo, gli elementi di un'altra classe, le deve prima istanziare e attraverso l'oggetto creato può vedere solo gli elementi pubblici della classe istanziata.
Infatti il metodo metodotTerza() della classe Terza, attraverso l'oggetto s vede:
s->attributoPublic;
s->metodoPrimoA();
s->metodoSeconda().
Mentre non vede:
attributoPrivate
attributoProtected;
metodoPrimoC().
Se fosse necessario accedere agli attributi oppure ai metodi non visibili lo potrebbe fare solo attraverso l'uso dei metodi:
s->metodoPrimoA();
s->metodoSeconda().
Per rendere efficace questo argomento, vi suggerisco di implementare con il linguaggio C++ le classi Prima, Seconda e Terza ed analizzarne attentamente il comportamento.
EREDITARIETA' MULTIPLA
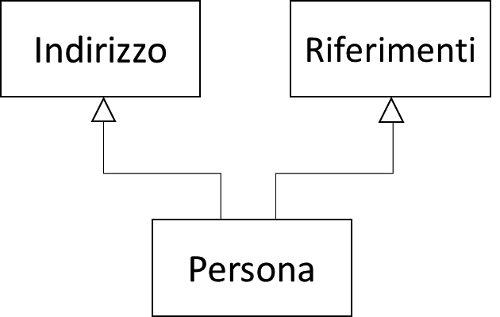
Il linguaggio C++ permette di ereditare più classi contemporaneamente in questo caso si parla di ereditarietà multipla, vediamo un esempio:
Immaginate di avere una classe Persona a cui volete aggiungere le informazioni dell'indirizzo ed i riferimenti principali. In questo caso la classe Persona potrebbe ereditare una classe Indirizzo ed una classe Riferimenti, come mostra il diagramma UML seguente:
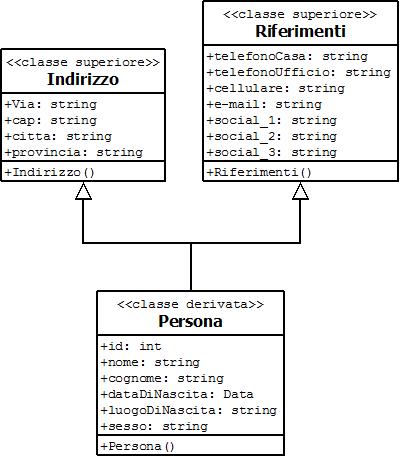
class Indirizzo{
public:
string via;
string cap;
string citta;
string provincia;
Indirizzo(){}
};
class Riferimenti{
public:
string telefonoCasa;
string telefonoUfficio;
string cellulare;
string email;
string social_1;
string social_2;
string social_3;
Riferimenti(){}
};
class Persona : public Indirizzo, public Riferimenti{
private:
string sesso;
public:
int id;
string nome;
string cognome;
Data *dataDiNascita;
string luogoDiNascita;
void setMaschio(){
this->sesso="maschio";
}
void setFemmina(){
this->sesso="femmina";
}
string getSesso(){
if(sesso=="") sesso="maschio";
return this->sesso;
}
Persona(){
this->dataDiNascita=new Data();
}
Persona(int id,string nome,string cognome, Data *dataDiNascita,string luogoDiNascita, string sesso,
string via, string cap, string citta, string provincia, string telefonoCasa, string telefonoUfficio,
string email,string facebook, string linkedin, string skillbook){
if(sesso=="maschio")setMaschio();
else setFemmina();
this->dataDiNascita=new Data();
this->id=id;
this->nome=nome;
this->cognome=cognome;
this->dataDiNascita=dataDiNascita;
this->luogoDiNascita=luogoDiNascita;
this->via=via;
this->cap=cap;
this->citta=citta;
this->provincia=provincia;
this->telefonoCasa=telefonoCasa;
this->telefonoUfficio=telefonoUfficio;
this->email=email;
this->social_1=facebook;
this->social_2=linkedin;
this->social_3=skillbook;
}
};
Nella prossima lezione parleremo di Polimorfismo degli oggetti.
<< Lezione precedente Lezione successiva >>
Clicca qui per scaricare i laboratori di questa lezione (Per eseguire i laboratori installate Code Block sul vostro computer)
Laboratori di Logica di Programmazione in C
Impariamo a programmare con JavaScript - Lezione 16
![]() Gino Visciano |
Skill Factory - 01/07/2018 18:11:25 | in Tutorials
Gino Visciano |
Skill Factory - 01/07/2018 18:11:25 | in Tutorials
Benvenuti alla sedicesima lezione, in questa lezione impareremo a gestire un databese con JavaScript ed useremo per lo scambio dei dati il formato JSON (JavaScript Object Notation).
 Che cos'è JSON
Che cos'è JSON
La struttura di JSON (JavaScript Object Notation) è semplicissima e permette di rappresentare il contenuto di oggetti da usare per lo scambio di dati, soprattutto all'interno di applicazioni JavaScript/Ajax.
E' simile all' XML (eXtensible Markup Language), anche se questo linguaggio viene maggiormente usato per la descrizione di documenti oppure per fornire informazioni di configurazione.
Attenzione, non ponetivi la domanda meglio XML o JSON, perché il loro utilizzo dipende principalmente dalle esigenze che avete oppure dagli strumenti che state usando.
Nell'esempio seguente vediamo come si può usare JSON in JavaScript per memorizzare i dati di un prodotto:
var prodotto = {
"id" : '1',
"nome":"Penna",
"prezzo":'0.5',
"descrizione":"Penna colore rosso",
"id_categoria":'3'
}
Per visualizzare il contenuto dell'oggetto prodotto dovete usare la sintassi seguente:
console.log(prodotto.id);
console.log(prodotto.nome);
console.log(prodotto.prezzo);
console.log(prodotto.descrizione);
console.log(prodotto.id_categoria);
Tipi di dati in JSON
JSON supporta i seguenti tipi di dati:
Boolean ( true e false )
"pagata" : true
Numeri
"eta" : '34'
Stringhe
"nome" : "Mario"
Array
"contatti" : ["08112428", "rossi.alba@gmail.com", "skp.rossi.alba"]
Array di oggetti
var prodotti=[ {
"id" : '1',
"nome":"Penna",
"prezzo":'0.5',
"descrizione":"Penna colore rosso",
"id_categoria":'3'
}, {
"id" : '2',
"nome":"Matita",
"prezzo":'0.2',
"descrizione":"Matita a righe gialle",
"id_categoria":'3'
} ]
Per visualizzare il contenuto dell'Array di oggetti prodotti dovete usare la sintassi seguente:
for(var x=0;x<2;x++){
console.log(prodotti[x].id);
console.log(prodotti[x].nome);
console.log(prodotti[x].prezzo);
console.log(prodotti[x].descrizione);
console.log(prodotti[x].id_categoria);
}
Oggetti nidificati
var dipendente= {
"nome":"Mario",
"cognome":"Rossi",
"dataDiNascita":"20/05/1985",
"luogoDiNascita":"Roma",
"indirizzoResidenza":{"strada":"Piazza Fiume, 30","cap":"00100","provincia":"RM"},
"indirizzoDomicilio":{"strada":"Via Montenapoleone, 20","cap":"20100","provincia":"MI"},
"ruolo":"Programmatore",
"titoloDiStudio":"Laurea Triennale",
"stipendio":1.586}
Per visualizzare il contenuto dell'Oggetto nidificato dipendente dovete usare la sintassi seguente:
console.log(dipendente.nome);
console.log(dipendente.cognome);
console.log(dipendente.dataDiNascita);
console.log(dipendente.luogoDiNascita);
console.log(dipendente.indirizzoResidenza.strada);
console.log(dipendente.indirizzoResidenza.cap);
console.log(dipendente.indirizzoResidenza.provincia);
console.log(dipendente.indirizzoDomicilio.strada);
console.log(dipendente.indirizzoDomicilio.cap);
console.log(dipendente.indirizzoDomicilio.provincia);
console.log(dipendente.ruolo);
console.log(dipendente.titoloDiStudio);
console.log(dipendente.stipendio);
Come convertire un oggetto JSON in un oggetto JavaScript
Se i dati organizzati in formato JSON sono in formato testo oppure stringa, per trasformarli in oggetti JavaScript potete usare il metodo JSON.parse(testo) oppure eval("("+testo+")"), come mostrano gli esempi seguenti:
Esempio 1
var strProdotto='{"id":1,'+'"nome":"Penna","prezzo":0.5,"descrizione":"Penna colore rosso","id_categoria":3}'
var objProdotto=JSON.parse(strProdotto);
console.log(objProdotto.id);
console.log(objProdotto.nome);
console.log(objProdotto.prezzo);
console.log(objProdotto.descrizione);
console.log(objProdotto.id_categoria);
Esempio 2
var strProdotto='{"id":1,'+'"nome":"Penna","prezzo":0.5,"descrizione":"Penna colore rosso","id_categoria":3}'
var objProdotto=eval("("+strProdotto+")");
console.log(objProdotto.id);
console.log(objProdotto.nome);
console.log(objProdotto.prezzo);
console.log(objProdotto.descrizione);
console.log(objProdotto.id_categoria);
Che cos'è il CRUD
Il CRUD è l'insieme delle operazioni che servono per Inserire, Leggere, Modificare e Cancellare i dati di una tabella di un databese.

CRUD è l'acronimo di:
- Create [Inserimento]
- Read [Lettura]
- Update [Modifica]
- Delete [Cancellazione]
Per creare un'applicazione che vi permette di gestire il CRUD servono gli strumenti seguenti:
- Visual Studio Code
- MySQL
- Express.js
Visual Studio Code
Visual Studio Code è un IDE (Integrated development environment), un ambiente di sviluppo integrato che serve per scrivere applicazioni.
Per scaricare questo programma clicca qui.
Dopo il download del file, dovete lanciarlo per installare il programma.

MySQL
MySQL è il nostro DBMS (Database Management System).
Per installare questo programma dovete scaricare XAMPP, cliccate qui per avviare il download.
Per ricevere maggiori informazioni su MySQL cliccate qui.

Express.js
Express è un framework per creare applicazioni web Node.JS.
Per Installare il framework create la cartella app-prodotti, attivatela ed eseguite il comando:
npm install express

Laboratorio
In questo Laboratorio creiamo una semplice applicazione per gestire Prodotti.
Per iniziare create la cartella app-prodotti, spostatevi nella cartella ed installate i moduli seguenti:
npm install mysql
npm install body-parser
Dopo l'installazione dei due moduli, lanciate Visual Studio Code, selezionate apri cartella, aprite la cartella app-prodotti e successivamente selezionate nuovo file (ctrl n).
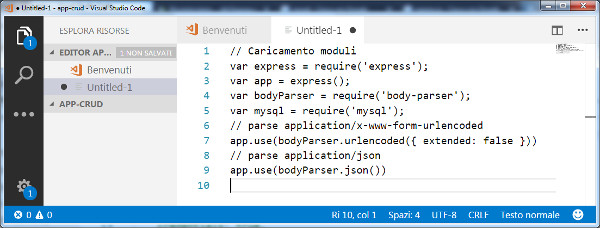
Prima di tutto, con il comando require caricate tutti i moduli che servono per creare l'applicazione, come mostra l'immagine seguente:
Per salvare il file, premete alt f, cliccate sulla voce salva, inserite il nome AppProdotti.js e cliccate sul pulsante salva.
(La stessa cosa la potete fare premendo ctrl s)
Come creare il Server Web
Con il framework Express la creazione di un Server Web è un'operazione molto semplice, il codice JavaScript seguente vi permette di creare i metodi GET e POST ed avviare il server sulla porta 8090.
app.get('*', function (request, response) {
...
});
app.post('*' , function (request, response, next ) {
...
});
app.listen(8090, function () {
console.log('listening on port 8090.');
});
I metodi app.get ed app.post si attivano ogni volta che arriva una richiesta di tipo GET oppure POST ed eseguono la funzione function (request , response) {...}.
L'argomento request è la request, l'oggetto che contiene i parametri inviati dal server, l'argomento response è la response l'oggetto usato per inviare le risposte al client.
Con Express per leggere i parametri da una request di tipo GET dovete usare la proprietà query, come mostra l'esempio seguente:
req.query.nomeparametro;
Se la request è di tipo POST dovete usare la proprietà body, come mostra l'esempio seguente:
req.body.nomeparametro;
La funzione app.listen è una funzione di callback, serve ad attivare il server web che restrà in ascolto sull'indirizzo ip di default 127.0.0.1 (localhost), utilizzando la porta 8090.
I metodi app.get ed app.post verranno implementati dopo.
Come creare il Database dbprodotti
Per utilizzare la nostra applicazione dobbiamo creare il database dbprodotti, per farlo seguite le operazioni seguenti:
cliccate sull'icona di XAMPP 
Quando appare la maschera seguente, avviate prima Apache e poi MySQL come indicato:
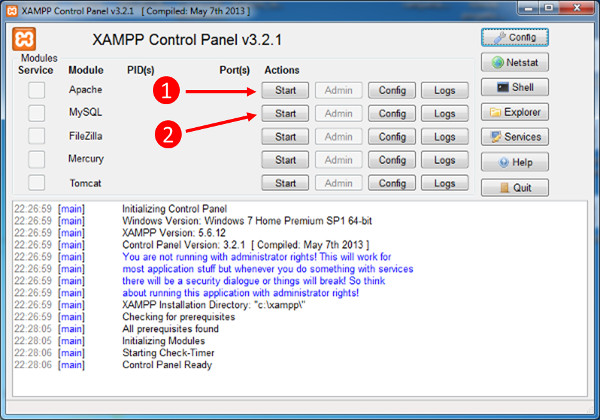
Successivamente per lanciare MySQL, dovete cliccare sul pulsante ADMIN.
La maschera seguente mostra come appare il Pannello di Controllo di MySQL, con a sinistra i Database creati e in alto le schede di gestione.
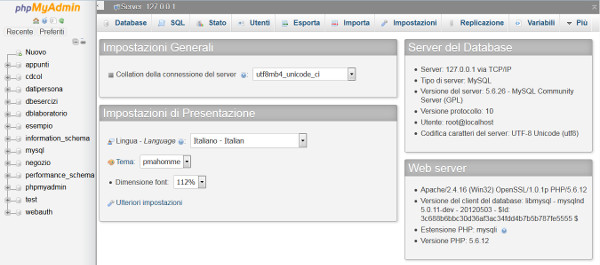
A questo punto, selezionando la scheda SQL, potete creare il Database eseguendo uno alla volta i comandi SQL seguenti:
1) create database dbprodotti;
Ognuno dei comandi seguenti devono essere eseguiti insieme al comando:
use dbprodotti;
2) create table prodotti(id int primary key auto_increment, prodotto varchar(50) not null, id_categoria int not null);
3) create table categorie(id int primary key auto_increment, categoria varchar(50) not null);
4)
Come connettersi al Database MySQL
Per connettersi al database dbprodotti dovete creare l'oggetto connection utilizzando la funzione mysql.createConnection({ .. }), come mostra l'esempio seguente:
var connection = mysql.createConnection({
host : 'localhost',
user : 'nomeutente',
password : 'password',
database : 'nomedatabase'
});
Nel nostro caso:
var connection = mysql.createConnection({
host : 'localhost',
user : 'root',
password : ''
database : 'dbprodotti'
});
La password non è stata indicata perché l'utente root non ha una password.
Successivamente per attivare la connessione usate il comando seguete:
connection.connect(function(err){
if(!err) {
console.log('Connessione eseguita con successo!!!');
} else {
console.log('Errore di connessione!!!');
}
});
Per chiudere la connessione dovete usare il comando:
connection.end();
Come eseguire le operazioni di CRUD
Per eseguire le operazioni di CRUD dovete conoscere il linguaggio SQL, per chi ne avesse bisogno, può apprendere velocemente l'SQL cliccando sul link seguente:
Ricominciamo .. dal linguaggio SQL
Con JavaScript possiamo eseguire comandi SQL con la funzione query, dell'oggetto connection.
Vediamo gli esempi principali:
- Create (Inserimento)
connection.query("INSERT INTO prodotii (prodotto, id_categoria) VALUES (?, ?)"), ['Camicia', 1'], function(err, result) { ... }
- connection.query -> funzione JavaScript;
- INSERT INTO prodotii (prodotto, id_categoria) VALUES (?, ?) -> comando SQL;
- ?, ? -> parametri ;
- ['camicia', 1] -> valori dei parametri;
- function(err, result) { ... } -> funzione eseguita dopo l'esecuzione del comando SQL;
- err -> si usa nel caso in cui l'esecuzione del comando SQL non va a buon fine;
- result -> si usa nel caso in cui l'esecuzione del comando SQL va a buon fine.
- Update (Modifica)
connection.query("UPDATE prodotti set id_categoria=? where id=?"), [2,1], function(err, result) { ... }
- Delete (Cancellazione)
connection.query("DELETE FROM prodotti where id=?"), [1], function(err, result) { ... }
- Read (Lettura e Visualizzazione)
connection.query("SELECT * FROM prodotti", function (err, result, fields) {
if (err) throw err;
for (var i in result) {
console.log(result[i]);
}
});
Laboratori di Logica di Programmazione in C- Lezione 5
![]() Gino Visciano |
Skill Factory - 26/05/2018 17:17:57 | in Tutorials
Gino Visciano |
Skill Factory - 26/05/2018 17:17:57 | in Tutorials
Benvenuti, in questa lezione, attraverso i laboratori proposti, vedrete le principali tecniche di programmazione.
S O M M A R I O
LAB01: COME SOSTITUIRE IL COMANDO GOTO
LAB02: COME SI CREA UN MENU DI SCELTA UTILIZZANDO UN FLAG
LAB03: COME SI RIPETE UN PROGRAMMA
LAB04: TECNICHE DI SORT
LAB05: RICERCA SEQUENZIALE O LINEARE
LAB06: RICERCA DICOTOMICA O BINARIA
LAB07: ROTTURA DI CODICE
LAB 8: IMPAGINAZIONE DI UNA SEQUENZA DI DATI
ELENCO DELLE LEZIONI
DOWNLOAD LABORATORI
LAB01: COME SOSTITUIRE IL COMANDO GOTO
L'istruzione GOTO permette di saltare ad una particolare riga di programma oppure in una posizione del programma dove è presente un'etichetta.
L'uso del GOTO non è consigliato perchè rende i programmi poco leggibili, creando il famoso spaghetti huose, ovvero percorsi logici difficili da seguire e spesso incomprensibili.

Per evitare i problemi creati dall'istruzione GOTO la possiamo sostituire con un ciclo do - while. Il do deve essere posizionato nel punto dove saltare, perché sostituisce l'etichetta, mentre il while va messo al posto del GOTO, come mostra l'esempio seguente:

LAB02: COME SI CREA UN MENU DI SCELTA UTILIZZANDO UN FLAG
Per creare un menu di scelta vi servono le seguenti strutture di programmazione:
1) Ciclo do - while, per ripetere la visualizzazione del menu;
2) Struttura condizionale switch - case - default, per gestire la scelta fatta.
Un flag è una variabile numerica oppure booleana usata per ripetere un ciclo oppure per attivare o meno una scelta condizionale.
In C un flag corrispnde a vero se contiene un valore diverso da 0, altrimenti è falso.
In questo laboratorio usiamo un flag vero per visualizzare di nuovo il menu di scelta.
Impostando il flag a falso (scelta 5), il programma termina.

LAB03: COME SI RIPETE UN PROGRAMMA
Per creare un menu di scelta vi servono le seguenti strutture di programmazione:

1) Ciclo do - while esterno, permette di ripetere il programma;
2) Ciclo do - while interno, permette di inserire di nuovo la risposta se non si risponde con s oppure n;
3) Struttura condizionale if - else, viene usata per conrollare se la risposta fornita è s oppure n. Nel caso che i caratteri sono diversi da s oppure n viene stampato un messaggio d'errore e viene richiesta la risposta, altrimenti viene impostato il flag a false ed il controllo passa al do - while esterno.
La funzione tolower trasforma in minuscolo il valore della risposta.
LAB04: TECNICHE DI SORT
Per ordinare una collezione di dati, esistono diverse tecniche di sort, le più usate sono le seguenti:
- Selection Sort
- Bubble Sort
- Insertion Sort
- Merge Sort
- Quick Sort
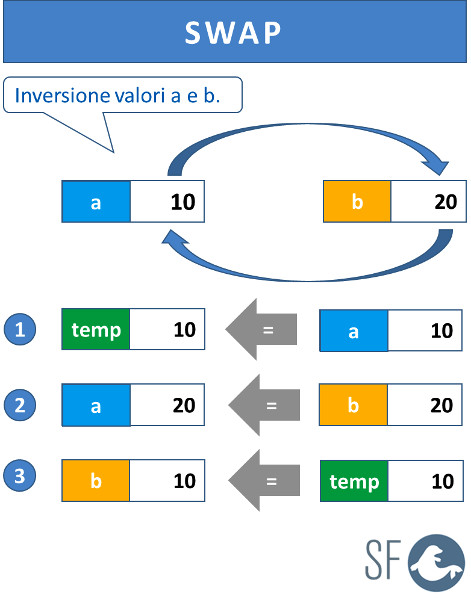
Per poter eseguire il sort di una collezione di dati è importate confrontare tutti gli elementi da ordinare in modo crescente o decrescente e scambiarli (SWAP) se le loro posizioni non corrisponde al tipo di ordinamento scelto.
Lo SWAP è la tecnica che serve per invertire il contenuto di due variabili, questa tecnica richiede l'uso di una variable temporanea usata per conservare provvisoriamente il valore di un delle due variabili da invertire. L'immagine seguente mostra come si applica lo SWAP:
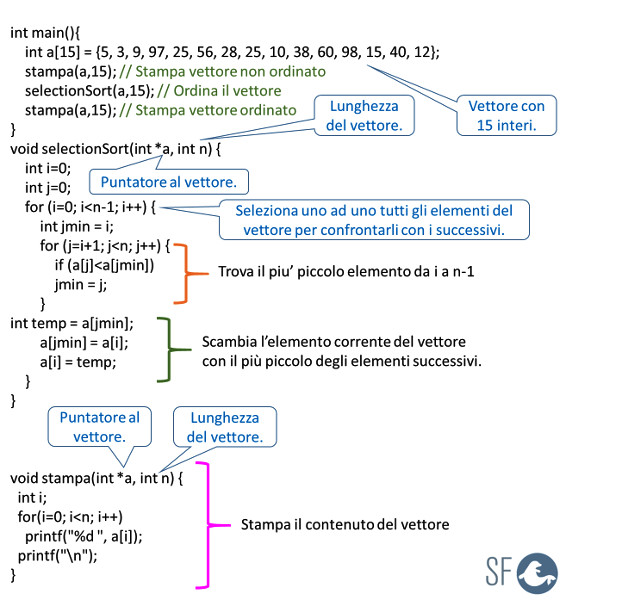
Negli esempi seguenti vediamo un selection sort ed bubble sort applicati ad array numerici.
SELECTION SORT
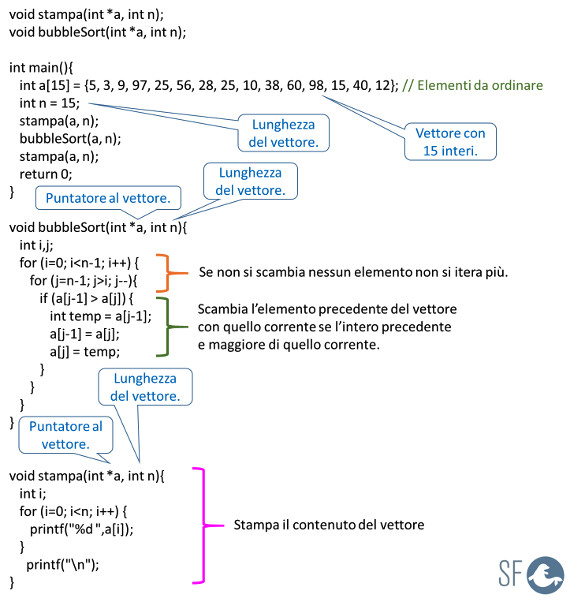
BUBBLE SORT
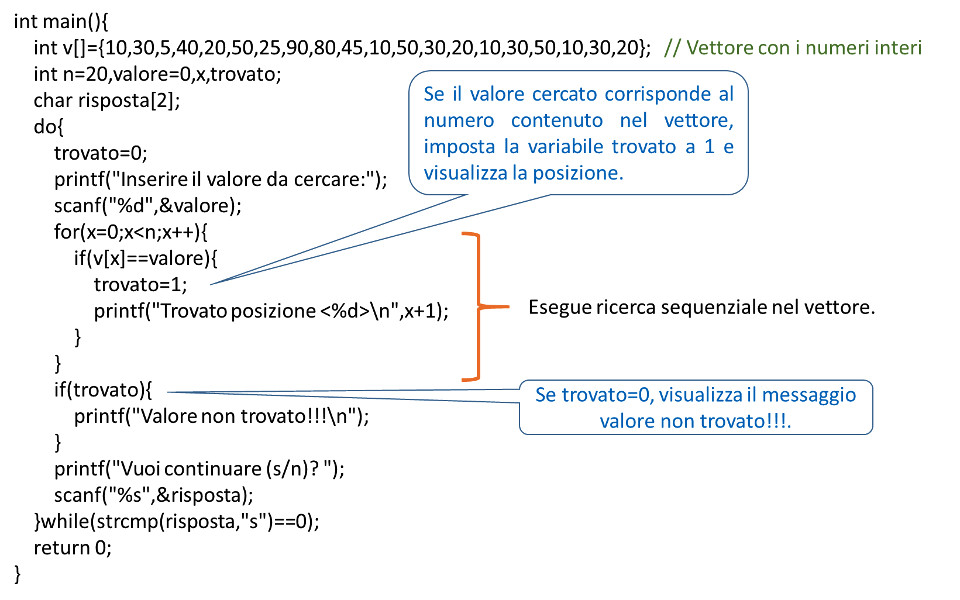
LAB05: RICERCA SEQUENZIALE O LINEARE
Per ricercare un valore in una collezione di dati, come ad esempio un vettore d'interi, serve un ciclo for che permette di scorrere tutti i valori della collezione e confrontarli con il valore cercato, come mostra l'esempio seguente:
LAB06: RICERCA DICOTOMICA O BINARIA
Per ricercare un valore in una collezione di dati, come ad esempio un vettore d'interi, oltre alla ricerca sequenziale potete usare anche la ricerca dicotomica molto più performante.
Per esegure questo tipo di ricerca detta anche binaria la collezione di dati deve essere ordinata.
L'esempio seguente mostra come usare questa tecnica per ricercare un valore in un vettore d'interi ordinato in modo crescente:

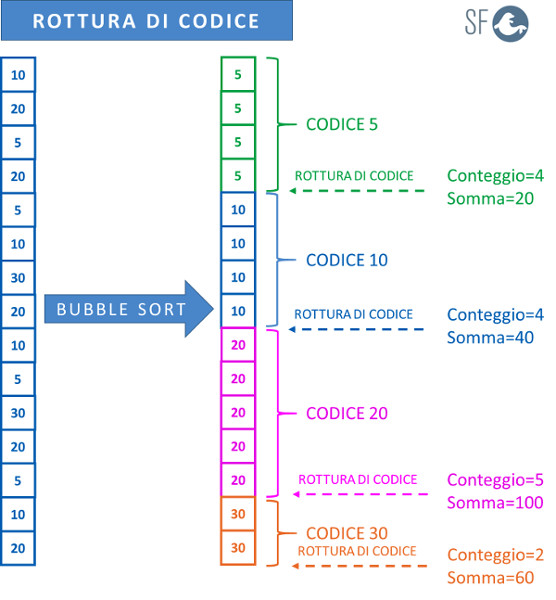
LAB07: ROTTURA DI CODICE
La rottura di codice è una tecnica applicata per analizzare sequenze di dati organizzate in base ad una chiave comune chiamata codice. Tutte le volte che la chiave scelta cambia, si verifca una rottura di codice.
Ad ogni cambiamento di codice vengono visualizzate le statistiche della chiave corrente (conteggio, somma, media, max e min) e si ricominciano a calcolare quelle della nuova chiave.
L'immagine seguente mostra la tecnica della rottura di codice applicata ad un vettore d'interi, in questo caso alla chiave corrisponde il valore del numero.
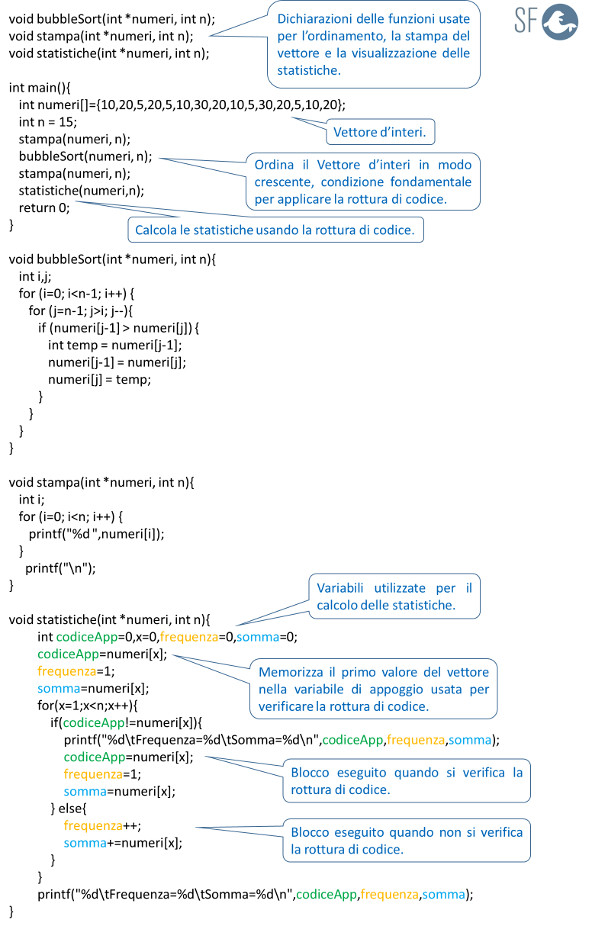
L'esempio seguente mostra come calcolare la frequenza e la somma dei numeri interi uguali presenti in un vettore, utilizzando la rottura di codice:
LAB 8: IMPAGINAZIONE DI UNA SEQUENZA DI DATI
L'impaginazione è una tecnica di programmazione fondamentale per visualizzare sequenze di dati memorizzati in array oppure tabelle.
L'impaginazione deve permettere l'organizzazione dei dati da visualizzare in pagine di lunghezza predefinita e consentire la navigazione tra le pagine con la seguente modalità:
- Vai alla prima pagina;
- Vai all'ultima pagina;
- Vai alla pagina precedente;
- Vai alla pagina successiva.
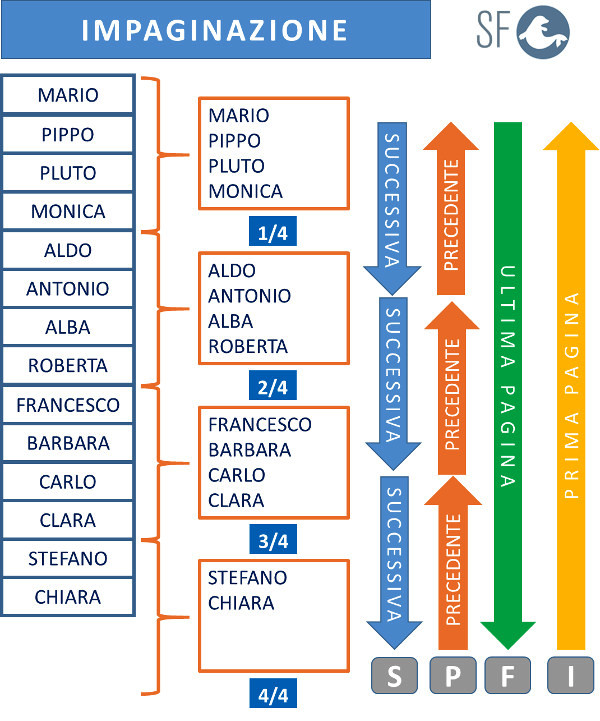
Per gestire la navigazione sono importanti le informazioni seguenti:
1) Numero di righe per pagina;
2) Numero totale di pagine;
3) Pagina corrente;
4) Offset, valore che corrisponde alla posizione della prossima riga da leggere.
Per calcolare il numero totale di pagine dobbiamo dividere il numero totale di righe, della serie di dati da visualizzare, per la lunghezza della pagina e arrotondare per eccesso, come mostra la formula seguente:
totalePagine=ceil(totaleRighe/lunghezzaPagina);
L'Offset lo possiamo calcolare con la formula seguente:
offset=(paginaCorrente-1)*lunghezzaPagina;
L'esempio seguente mostra come impaginare un vettore di nomi:

LABORATORI DI LOGICA DI PROGRAMMAZIONE IN C
LEZIONE 1
LEZIONE 2
LEZIONE 3
LEZIONE 4
LEZIONE 5
D O W N L O A D L A B O R A T O R I
Clicca qui per il download dei laboratori.
Introduzione alla logica degli Oggetti (Per imparare a programmare ad oggetti)
Introduzione alla logica degli oggetti - Lezione 3
![]() Gino Visciano |
Skill Factory - 06/04/2018 00:17:32 | in Tutorials
Gino Visciano |
Skill Factory - 06/04/2018 00:17:32 | in Tutorials
In questa lezione iniziamo a descrive in modo più dettagliato l'architettura delle applicazioni software ad oggetti.
Nella lezione precedente abbiamo visto che oggi le applicazioni software sono insiemi di componenti che collaborano tra loro per per soddisfare le specifiche funzionali richieste.
Gli oggetti che compongono le applicazioni sono di tre tipi:
1) MODEL - Contengono dati (sono entità).
2) VIEW - Hanno il compito di permettere la visualizzazione oppure l'inserimento dei dati negli oggetti di tipo MODE, ad esempio in un'applicazione Web corrispondono alle Pagine HTML, mentre in un'applicazione Desktop corrispondono alle interfacce grafiche (GUI).
3) CONTROLLER, che hanno il compito di gestire il flusso logico applicativo. Un controller può svolgere anche il ruolo di servizio, mettendo a disposizione dell'applicazioni in cui è presente, funzionalità oppure azioni specifiche, che si possono richiamare attraverso i metodi dell'interfaccia esposta.
I simboli UML (Unified Modeling Language) che si usano per indicare i tre tipi di oggetti utilizzati per creare le applicazioni software, sono i seguenti:
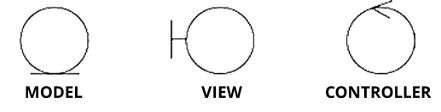
Il diagramma UML che descrive l'architettura di un'applicazione software si chiama "Diagramma dei Componeti".
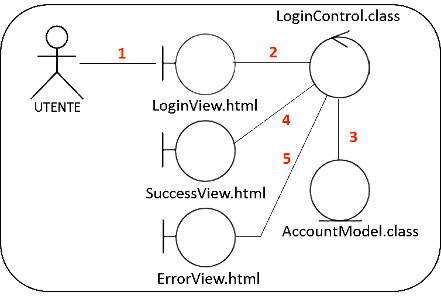
Diagramma dei componenti che descrive il processo di login di un'applicazione.
COME SI CREANO I COMPONENTI DELLE APPLICAZIONI
I componenti delle applicazione software si creano con i linguaggi di programmazione ad oggetti, questi linguaggi si differenziano da quelli procedurali o funzionali perché si basano prevalentemente sull'uso di classi ed oggetti e permettono d'implemetare i seguenti paradigmi di programmazione:
1) Incapsulamento;
2) Polimorfismo di metodi ed oggetti;
3) Ereditarietà.
I principali linguaggi di programmazione ad oggetti sono:
1) C++ (pronuncia: c plus plus);
2) Java (pronuncia: giava);
3) C# (pronuncia: c sharp);
4) Python (pronuncia: paiton).
Per i nostri esempi useremo il C++ il linguaggio di programmazione ad oggetti più insegnato nelle scuole superiori.
CLASSI ED OGGETTI
Le Classi sono template creati dai programmatori, con i linguaggi di programmazione ad oggetti, servono per creare gli oggetti.
L'esempio seguente mostra una classe scritta in C++, che definisce il template di un oggetto di tipo Persona:
class Persona {
private:
string nome;
string cognome;
int eta;
public:
void setNome(string nome){
this->nome=nome;
};
void setCognome(string cognome){
this->cognome=cognome;
};
void setEta(int eta){
this->eta=eta;
};
string getNome(){
return this->nome;
}
string getCognome(){
return this->cognome;
}
int getEta(){
return this->eta;
}
Persona(){};
Persona(string nome, string cognome, int eta){
this->nome=nome;
this->cognome=cognome;
this->eta=eta;
}
};
<Per approfondire la conoscenza del linguaggio C clicca qui.>
Gli Oggeti sono istanze delle Classi, istanziare significa creare un oggetto in memoria utlizzando la classe corrispondente.
Con la stessa classe si possono creare tanti oggetti dello stesso tipo.
L'esempio seguente mostra come s'istanzia l'oggetto persona di tipo Persona:
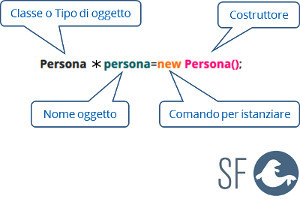
Attenzione *persona diventerà il puntatore che conterrà l'indirizzo dove è stato allocato l'oggetto costruito con il comando new.
I metodi e gli attributi degli oggetti istanziati possono essere usati associando il nome dell'oggetto all'elemento che si vuole usare con il simbolo ->, come mostra l'esempio seguente:
persona->setNome("Mario");
persona->setCognome("Rossi");
persona->setEta(35);
Le Classi definiscono il tipo di oggetto che state usando nell'applicazione, in fase di progettazione per disegnare una classe con il linguaggio UML (Unified Modeling Language) dovete usare un "Diagramma di Classe".
L'esempio seguente mostra il diagramma di classe dell'oggetto persona:

Per convenzione i nomi delle Classi iniziano sempre con la lettera maiuscola, se sono composti da più parole, devono iniziare tutte con la lettera maiuscola.
I nomi degli Oggetti sono sempre scritti in minuscolo, se sono composti da più parole, le altre parole devono iniziare con la lettera maiuscola.
Gli Oggetti sono Componenti che contengono i seguenti elementi:
- attributi
- metodi
- costruttori
I programmatori per capire come sono fatti i componenti di un'applicazione e qual è il loro stato, devono leggere rispettivamente il "Diagrammi di Classe" e il "Diagrammi degli Oggetti".
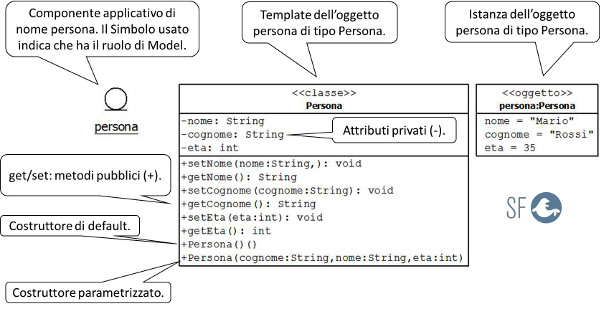
Nell'esempio seguente, il "Diagramma di componete" a sinistra, indica che il componete applicativo persona è un MODEL.
Il "Diagramma di Classe" al centro ne descrive la struttura ed il tipo, infatti corrisponde alla classe Persona.
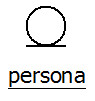
Il "Diagramma di Oggetto" a destra ne descrive lo stato in memoria dopo che è stato istanziato (creato), il Titolo del diagramma: persona:Persona indica rispettivamente il nome dell'oggetto e la classe corrispondente, cioè il tipo.
INCAPSULAMENTO
L'Incapsulamento è una proprietà dei linguaggi di programmazione ad oggetti, permette di utilizzare dei modificatori di accesso per regolare la visibilità degli elementi di una classe (attributi, metodi e costruttori), verso i metodi di altre classi che vogliono usarli.
I modificatori di accesso più usati sono:
1) public (in un diagramma UML corrisponde al segno +);
2) private (in un diagramma UML corrisponde al segno -);
3) prrotected (in un diagramma UML corrisponde al segno #), si comporta come private in caso d'istanza, come public in caso di ereditarietà, come vedremo nelle prossime lezioni;
ATTRIBUTI
Gli Attributi sono variabili che contengono informazioni, si possono definire le proprietà dell'oggetto. Ad esempio nei MODEL, gli attributi si usano per memorizzare i dati delle entità corrispondenti, come mostra l'esempio seguente:
persona->nome="Mario";
persona->cognome="Rossi";
persona->eta=30;
persona contiene l'indirizzo dell'oggetto a cui facciamo riferimento;
nome è un attributo dell'oggetto.
Gli Attributi possono essere usati direttamente, come nell'esempio, da metodi di altre classi, solo se sono pubblici (+), se gli Attributi in una classe sono privati (-) sono visibili solo ai metodi della stessa classe.
Quindi l'unico modo per gestire gli Attributi privati di una classe è quello di usare i Metodi ed i Costruttori pubblici presenti nella stessa classe.
METODI
I Metodi sono funzioni che eseguono operazioni, le azioni dei Metodi determinano il comportamento ed il ruolo dell'oggetto.
I linguaggi di programmazione ad oggetti, permettono di scrivere le istruzioni necessarie per implementare la logica delle applicazioni, unicamente all'interno dei Metodi.

I Metodi che hanno il nome che inizia con i prefissi get e set si usano per assegnare o leggere i valori degli Attributi privati dell'oggetto a cui appartengono.
Ad esempio, dato che gli Attributi della clappe Persona sono privati, per gestirli sono stati creati i seguenti Metodi pubblici:
- setNome
- getNome
- setCognome
- getCognome
- setEta
- getEta
Nell'esempio seguente vediamo come si possono assegnare i valori agli Attributi privati dell'oggetto persona usando i Metodi set corrispondenti:
persona->setNome("Mario");
persona->setCognome("Rossi");
persona->setEta(30);
Mentre nel prossimo esempio vediamo come si possono leggere i valori degli Attributi privati dell'oggetto persona usando i Metodi get corrispondenti:
String nome = persona->getNome();
String cognome = persona->getCognome();
int eta = persona->getEta();
I Metodi se sono pubblici possono essere eseguiti anche dai Metodi di altri oggetti, se sono privati possono essere eseguiti solo dai Metodi dello stesso oggetto, perché non sono visibili a metodi di altre classi.
OVERLOAD
I'Overload insieme all'Override può essere definito polimorfismo dei metodi, è una prorpietà dei linguaggi di programmazione ad oggetti che permette di usare metodi con lo stesso nome, ma firma diversa, all'interno della stessa classe.
La firma di un metodo è composta dal nome del metodo più i tipi degli argomenti passati al metodo, come mostra l'immagine seguente:

Vediamo un esempio di Overload in C++:
Immaginate di voler colorare una figura geometrica, dando la possibilità al programmatore di usare le seguenti modalità d'impostazione del colore:
1) fornire direttamente il nome del colore da assegnare alla figura geometrica sotto forma di stringa;
2) indicare il colore da assegnare alla figura geometrica con un numero intero;
3) fornire i codici RGB del colore da assegnare alla figura geometrica.
Per evitare di assegnare nomi diversi ai metodi per colorare la figura geometrica, dato che per ogni modalità d'impostazione del colore si usano tipi sono diversi, possiamo usare l'Overload.
class ColoraFiguraGeometrica{
// Attributi privati non visibli a metodi di altre classi classi
private:
string tipoFigura;
string coloreFigura;
// Metodi pubblici visibli a metodi di altre classi classi
public:
// Restituisce il tipo di figura geometrica
string getTipoFigura(){
return this->tipoFigura;
}
// Restituisce il colore della figura geometrica
string getColoreFigura(){
return this->coloreFigura;
}
// 1-Overload Firma = setColore string
void setColore(string colore){
this->coloreFigura=colore;
}
// 2-Overload Firma = setColore int
void setColore(int colore){
switch(colore){
case 1:
this->coloreFigura="Rosso";
break;
case 2:
this->coloreFigura="Verde";
break;
case 3:
this->coloreFigura="Giallo";
break;
default:
this->coloreFigura="Nero";
break;
}
}
// 3-Overload Firma = setColore int int int
void setColore(int r,int g, int b){
stringstream sr;
stringstream sg;
stringstream sb;
sr << r;
sg << g;
sb << b;
this->coloreFigura="R="+sr.str()+", G="+sg.str()+"B="+sb.str();
}
// Costruttore parametrizzato usato per indicare il tipo di figura geometrica
ColoraFiguraGeometrica(string tipoFigura){
this->tipoFigura=tipoFigura;
}
};
<Per approfondire la conoscenza del linguaggio C clicca qui.>
COSTRUTTORI
I Costruttori sono Metodi che si usano per istanziare gli oggetti, vanno sempre indicati dopo il comando new usato per creare un oggetto, come mostra l'esempio seguente:

I Costruttori servono per inizializzare gli Attributi degli oggetti istanziati.
Ci sono due tipi costruttori, quello di base, senza parametri e quello parametrizzato, usato per inizializzare gli Attributi dell'oggetto con valori esterni, si riconoscono perché hanno lo stesso nome della Calsse e nella loro dichiarazione non è indicato il tipo restituito,
I Costruttori sono sempre pubblici, solo gli oggetti di tipo Singletone, particolari oggetti che possono essere istanziati una sola volta, hanno il costruttore privato.
COMUNICAZIONE E COLLABORAZIONE TRA COMPONENTI
Gli elementi pubblici di un oggetto rappresentano la sua Interfaccia. Come avviene anche per i componenti elettronici, l'Interfaccia viene usata per permettere la comunicazione con gli altri componenti.

Ad esempio l'Interfaccia dell'oggetto persona è la seguente:
- setNome
- getNome
- setCognome
- getCognome
- setEta
- getEta
Gli attributi dell'oggetto persona non sono visibili, perche sono privati, quindi non appartengono all'interfaccia.
I Metodi degli oggetti che devono gestire l'oggetto persona lo fanno attraverso la sua interfaccia, come mostra Il "Diagramma dei Componeti" seguente:
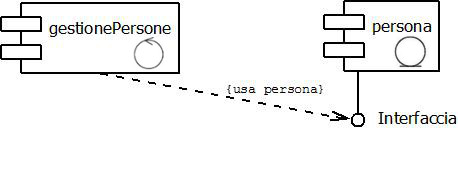
Il simbolo usato in UML per rappresentare un'interfaccia è il lecca lecca (lollipop).
Quindi il metodo di un componente applicativo (oggetto), per comunicare e collaborare con un altro componente, usando i metodi e gli attributi pubblici della sua interfaccia, lo deve prima istanziare con il comando new, successivamente usando il riferimento del componente creato, può usare tutti gli elementi della sua interfaccia.
In pratica il riferimento contiene l'indirizzo dell'oggetto che espone l'interfaccia, come mostra l'immagine seguente:

L'APPLICAZIONE GESTIONE PERSONE
Adesso vediamo quali sono i passaggi fondamentali per creare un'applicazione che permette di gestire persone.
Prima di tutto disegniamo il diagramma UML che mostra i principali componenti applicativi e in che modo collaborano tra loro:
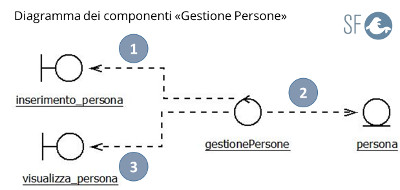
Figura 1
Analizzado i componenti del diagramma in Figura 1, vediamo che il componente gestionePersone, ha il ruolo di controller. Questo oggetto attraverso l'uso di due view: inserimeto_persona e visualizza_persona, permette di gestire i componenti persona, che hanno il ruolo di model.
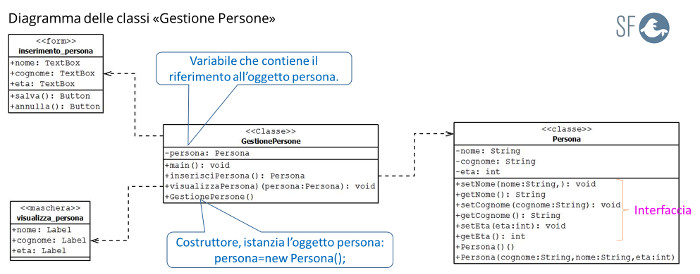
Il Diagramma di Classi seguente, mostra la struttura degli oggetti che compongono l'applicazione Gestione Persone.
COME SI GESTISCE IL FLISSO LOGICO (PROCESSO) DELL'APPLICAZIONE GESTIONE PERSONE
Il metodo main() della classe GestionePersone , il controller, permette d'implementare il flusso logico dell'applicazione per gestire le persone.
Per fare questo lavoro, il metodo main() esegue le seguenti operazioni:
1) usa il metodo inserimentoPersona() per permette l'inserimento dei dati attraverso la maschera "Inserimento Persona" (Figura 2);
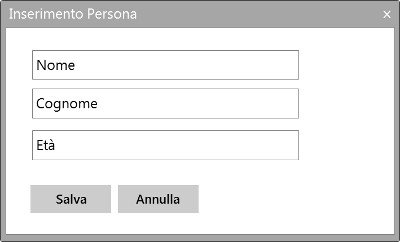
Figura 2
2) usa i metodi set dell'intercaccia dell'oggetto persona:
persona->setNome(nome);
persona>setCognome(cognome);
persona->setEta(eta);
per memorizza i dati inseriti della maschera all'interno dell'oggetto persona;
3) usa Il metdo visualizzaPersona(persona:Persona) per visualizzare attraverso la maschera "Visualizza Persona" (Figura 3) il contenuto dell'oggeto persona.
Questo metodo usa i metodi get dell'intercaccia dell'oggetto persona:
persona->getNome();
persona>getCognome();
persona->getEta();
per leggere i dati memorizzati negli attributi dell'oggetto persona e visualizzarli nella maschera.
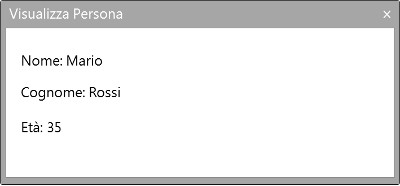
Figura 3
Il Diagramme delle Attività in Figura 4, mostra il flusso delle attività svolte dal metodo inserimentoPersona() per gestire l'inserimento dei dati nell'oggetto persona:
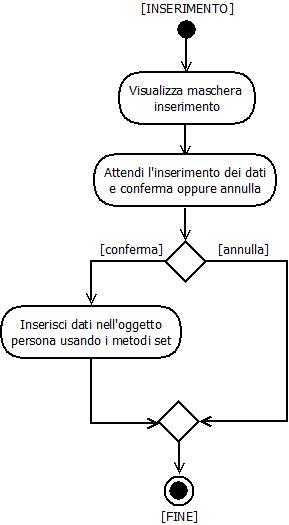
Figura 4
Nella prossima lezione parleremo di Ereditarietà, per riusare e specializzare classi già esistenti.
<< Lezione precedente Lezione successiva >>
 Eventi Formativi
Eventi Formativi

-

TECNICO DELLA PROGRAMMAZIONE
Napoli 22/04/2026
-

TonyBuzan Mind Mapping Practitioner for Business
Napoli 05/07/2018
-

IoT e criptovalute, la nuova frontiera del lavoro giovanile, partecipa al Webinar gratuito
27/04/2018
-
PRINCE2® 2017 Practitioner
Napoli 21/06/2018
-
PRINCE2® 2017 Foundation
Napoli 16/07/2018
-
GTD® I&I Sessions
Roma, Milano 01/01/2018
-

Automazione dell'ufficio con SharePoint
Roma 17/04/2017
-

Automazione dell'ufficio con SharePoint
Napoli 03/04/2017
-
Getting Things Done ® Mastering Workflow 1
Napoli 05/07/2018
-
Mind Mapping Practitioner for Students
Napoli 05/07/2018
 Offerte di Lavoro
Offerte di Lavoro
 Post più recenti
Post più recenti
-

Full Stack Developer
07/05/2026
-
1° MAGGIO: FESTA DEL LAVORO E DELLA FORMAZIONE
01/05/2026
-
Operatore Amministrativo Contabile
09/04/2026
-
Tecnico Programmatore: Il Profilo più richiesto dai giovani che frequentano la nostra Academy
17/03/2026
-
6.L'Assicurazione della Qualità nell'IFP
24/01/2026
-
Skill Factory 2025: Un anno di formazione tra "Innovazione (AI), Qualità (EQAVET) e Politiche Attive del Lavoro (PAR GOL)"
30/12/2025
-
10.Intelligenza Artificiale: cosa cambia nel mondo del lavoro
21/12/2025
-
5.L’etica della formazione come responsabilità professionale
13/12/2025
-
4.Buona Formazione: "Come assicurare la Qualità della Formazione"
06/12/2025
-
Corso gratuito di 60 ore per creare le competenze digitali fondamentali (DIGCOMP2.2)
25/09/2025