 Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy
Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy





Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy


-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-




 Scheda Azienda
Scheda Azienda Blog
Blog Eventi formazione
Eventi formazione Offerta formativa
Offerta formativa Offerte di lavoro
Offerte di lavoro Lavora con noi
Lavora con noi
 Richiedi informazioni
Richiedi informazioni
Skill Factory
Lista post > 4.Intelligenza Artificiale: tipi di reti neurali artificiali
4.Intelligenza Artificiale: tipi di reti neurali artificiali
![]() Gino Visciano |
Skill Factory - 25/10/2024 13:07:24 | in Home
Gino Visciano |
Skill Factory - 25/10/2024 13:07:24 | in Home
Come abbiamo visto nell'articolo precedente il primo tipo di rete neurale artificiale è stato il Percettrone costituito da un singolo strato di neuroni, ognuno dei quali riceve un input, calcola una somma ponderata e applica una funzione di attivazione.
Il Percettrone anche se non può risolvere problemi complessi ha gettato le basi per lo sviluppo delle reti neurali moderne, introducendo concetti fondamentali come pesi, bias, soglie e funzioni di attivazione.
Dovete immaginare le reti neurali artificiali come modelli matematici che simulano il funzionamento del cervello umano. I neuroni artificiali, che compongono le reti neurali, non sono altro che mini-processori che svolgono le seguenti attività:
1) Ricevono l'input: il neurone riceve diversi input, ciascuno moltiplicato per un peso specifico;
2) Calcolano la somma ponderata: gli input moltiplicati per i pesi vengono sommati tra loro, spesso aggiungendo un bias;
3) Applicano la funzione di attivazione: il risultato della somma ponderata viene passato attraverso una funzione di attivazione, che introduce non linearità e determina l'output del neurone.
I neuroni sono connessi tra loro da sinapsi artificiali. Queste sinapsi rappresentano il flusso di informazioni da un neurone all'altro. I pesi associati a ciascuna sinapsi determinano l'importanza dell'informazione che passa da un neurone all'altro. Un peso alto indica una connessione forte, mentre un peso basso o negativo indica una connessione debole o inibitoria.
Dovete pensare a una rete neurale come a una rete di tubi. I neuroni sono i nodi della rete, i tubi sono le connessioni (sinapsi) e i parametri (pesi e bias) sono come delle valvole che regolano il flusso d'acqua nei tubi. Le valvole non sono i tubi stessi, ma determinano quanto acqua può passare da un tubo all'altro.
I neuroni artificiali collaborano tra loro per risolvere problemi complessi; l'area del machine learning che si occupa delle reti neurali è il deep learning.
Questi modelli matematici possono essere pre-addestrati attraverso grandi quantità di dati, detti dataset. Dopo il pre-addestramento possono anche essere specializzati con una ulteriore fase di addestramento chiamata fine-tuning.
Oggi le reti neurali vengono utilizzate per identificare pattern, per riconoscere e creare immagini, video e musica, comprendere il linguaggio naturale, generare e sintetizzare testi e molto altro ancora. Con l'evoluzione sono emersi diversi tipi di architetture, ognuna con caratteristiche specifiche che le rendono adatte a compiti diversi.

TIPI DI RETI NEURALI ARTIFICIALI
I principali tipi di reti neurali artificiali sono:
1) Feed-forward
2) Ricorrenti
3) Convoluzionali
4) Generative Adversariali
5) Trasformatori
1. Reti Neurali Feed-forward
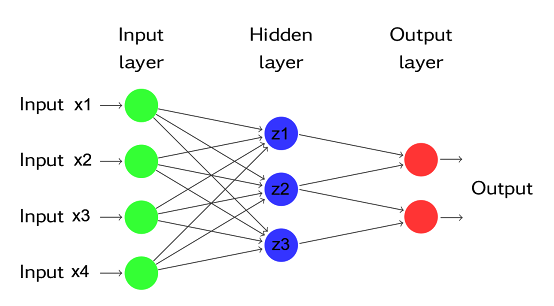
Sono le reti più semplici, con un flusso di informazioni che va solo in avanti, da uno strato all'altro. Può contenere anche molti strati interni.
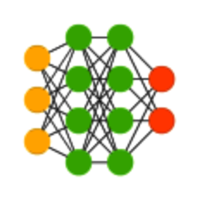
Apprendimento: supervisionato.
Queste reti vengono addestrate su un dataset di esempi, ognuno dei quali è composto da un input e dal corrispondente output corretto (etichetta). La rete cerca quindi di "imparare" la relazione tra gli input e gli output, in modo da poter prevedere l'output corretto per nuovi input mai visti prima.
Come avviene l'apprendimento in una rete feed-forward?
Inizializzazione: i pesi delle connessioni tra i neuroni vengono inizializzati casualmente.
Propagazione in avanti: l'input viene propagato attraverso la rete, strato per strato, fino a raggiungere l'output.
Calcolo dell'errore: si calcola la differenza tra l'output previsto dalla rete e l'output corretto (indicato nel dataset).
Backpropagation: l'errore viene propagato all'indietro attraverso la rete, aggiornando i pesi delle connessioni in modo da ridurre l'errore complessivo.
Ripetizione: i passi 2, 3 e 4 vengono ripetuti per molte iterazioni (epiche), fino a quando l'errore si riduce al di sotto di una soglia prefissata.
Perché l'apprendimento supervisionato è adatto alle reti feed-forward?
La struttura feedforward, con il flusso di informazioni che va in una sola direzione, si adatta bene all'apprendimento supervisionato, dove si vuole mappare un input a un output specifico. Gli algoritmi di apprendimento supervisionato, come la retropropagazione dell'errore, sono relativamente semplici da implementare.
2. Reti Neurali Ricorrenti (RNN)
Queste reti neurali hanno connessioni cicliche che permettono di mantenere uno stato interno, rendendole adatte a sequenze di dati. La caratteristica distintiva delle RNN è la presenza di connessioni ricorrenti, che consentono alla rete di "ricordare" informazioni passate, creando una sorta di memoria a breve termine. Questo le rende particolarmente adatte a lavorare con dati sequenziali, dove l'ordine degli elementi è importante.
Le loro caratteristiche le rendono adatte all'elaborazione del linguaggio naturale (NLP), alla generazione di testo e alle previsioni di serie temporali.


Le RNN di base presentano alcune limitazioni, come il vanishing/exploding gradient problem. Per ovviare a questi problemi, sono state sviluppate diverse varianti:
LSTM (Long Short-Term Memory): Reti Neurali Ricorrenti a Lungo Termine. Le LSTM sono dotate di porte che controllano il flusso di informazioni, consentendo di apprendere dipendenze a lungo termine. Sono ampiamente utilizzate per compiti come la traduzione automatica e il riconoscimento vocale.
GRU (Gated Recurrent Unit): Unità Ricorrente Recintata. Sono simili alle LSTM, ma con una struttura più semplice, le GRU sono altrettanto efficaci nel catturare dipendenze a lungo termine.
Bidirectional RNN: Le BRNN elaborano le sequenze in entrambe le direzioni (da sinistra a destra e da destra a sinistra), consentendo di sfruttare informazioni sia dal passato che dal futuro.
Encoder-Decoder: Questa architettura è composta da due parti: un encoder che mappa la sequenza di input in uno spazio vettoriale e un decoder che genera la sequenza di output a partire da questo spazio. È comunemente utilizzata per la traduzione automatica e la generazione di testo.
Gli Encoder-Decoder sono stati precursori dei Transformer.
Struttura: Sono varianti delle RNN, progettate per affrontare il problema del vanishing gradient, che limita la capacità delle RNN di apprendere dipendenze a lungo termine.
Utilizzo: Simile alle RNN, ma più efficaci per sequenze lunghe.


Apprendimento: gli RNN possono utilizzare tutti e tre i tipi di apprendimento: supervisionato, non supervisionato e per rinforzo, a seconda dell'obiettivo specifico dell'applicazione.
Apprendimento supervisionato
In questo caso, le RNN vengono addestrate su sequenze di dati per le quali è nota la sequenza di output corretta (Etichette).
Ad esempio, in un sistema di riconoscimento vocale, l'input potrebbe essere un'onda sonora e l'output corrispondente la trascrizione testuale.
Esempi:
Traduzione automatica: Tradurre una frase da una lingua all'altra.
Riconoscimento del parlato: Trascrivere un'onda sonora in testo.
Analisi del sentiment: Determinare se un testo esprime un'opinione positiva, negativa o neutrale.
Apprendimento non supervisionato
Le RNN vengono addestrate su grandi quantità di dati senza etichette, cercando di trovare pattern e strutture nascoste nelle sequenze.
Esempi:
Generazione di testo: Creare testi nuovi e coerenti, come poesie o script.
Compressione di sequenze: Ridurre la dimensione delle sequenze mantenendone le informazioni più importanti.
Anomaly detection: Identificare anomalie o eventi insoliti in sequenze di dati.
Apprendimento per rinforzo
Le RNN apprendono interagendo con un ambiente, ricevendo feedback positivi o negativi a seconda delle azioni intraprese.
Esempi:
Giochi: Imparare a giocare a giochi come il Go o gli scacchi.
Robotica: Controllare robot per eseguire compiti complessi.
Sistemi di raccomandazione: Suggerire prodotti o contenuti agli utenti in base alle loro interazioni.
Durante l'addestramento di reti neurali profonde, specialmente quelle ricorrenti, si può verificare un fenomeno noto come vanishing/exploding gradient. Questo problema si verifica durante la retropropagazione dell'errore, quando i gradienti (ovvero le misure di quanto i pesi della rete debbano essere aggiornati) diventano troppo piccoli (vanishing) o troppo grandi (exploding).
Vanishing gradient: I gradienti si avvicinano a zero, rendendo difficile l'aggiornamento dei pesi degli strati iniziali della rete. Di conseguenza, questi strati apprendono molto lentamente o addirittura non apprendono affatto.
Exploding gradient: I gradienti diventano estremamente grandi, rendendo instabile l'addestramento e causando oscillazioni nei pesi.
Perché le RNN sono particolarmente adatte alle sequenze?
La caratteristica distintiva delle RNN è la presenza di connessioni ricorrenti, che consentono alla rete di "ricordare" informazioni passate. Questo le rende particolarmente adatte a lavorare con dati sequenziali, dove l'ordine degli elementi è importante.
3. Reti Neurali Convoluzionali (CNN)
Le reti neurali Convoluzionali utilizzano filtri per estrarre caratteristiche locali dai dati, rendendole ideali per l'elaborazione di immagini e segnali audio. A differenza delle RNN, che sono più adatte per sequenze temporali, le CNN sfruttano una struttura particolare per estrarre caratteristiche rilevanti dalle immagini.
Riconoscimento di immagini, segmentazione di immagini, elaborazione del linguaggio naturale (NLP).
Esempi: LeNet, AlexNet, VGG.
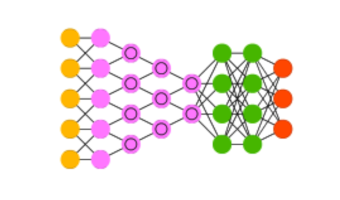

Kernel: Matrice di numeri che agisce come un filtro per estrarre caratteristiche.
Convoluzione: Operazione che applica un kernel all'immagine di input.
Pooling: Operazione che riduce la dimensione spaziale delle feature map.
Esempi:
Riconoscimento di immagini: Sono particolarmente adatte per l'analisi di immagini, come il riconoscimento facciale, la segmentazione di immagini e la classificazione di oggetti.
Elaborazione del linguaggio naturale: Possono essere utilizzate per l'analisi del sentimento, la classificazione di testi e la generazione di didascalie per immagini.
Medicina: Vengono impiegate per l'analisi di immagini mediche, come radiografie e risonanze magnetiche, per la diagnosi di malattie.
Apprendimento: le CNN utilizzano principalmente l'apprendimento supervisionato. Questo significa che vengono addestrate su un ampio dataset di immagini etichettate, dove ogni immagine è associata a una classe (es. gatto, cane, automobile).
Come funziona l'apprendimento in una CNN?
Convoluzione: Il primo passo è la convoluzione. Un filtro (o kernel) viene applicato sull'immagine, scorrendo pixel per pixel. Questo processo crea una feature map, che evidenzia determinate caratteristiche dell'immagine (es. bordi, texture).
Pooling: Successivamente, viene applicata una funzione di pooling, come il max pooling o il average pooling, per ridurre la dimensionalità della feature map e estrarre le caratteristiche più importanti.
Appiattimento: La feature map viene appiattita in un vettore, che viene poi inserito in uno o più livelli completamente connessi (fully connected layers).
Classificazione: I livelli completamente connessi utilizzano l'apprendimento supervisionato per classificare l'immagine in base alle caratteristiche estratte.
Perché l'apprendimento supervisionato è ideale per le CNN?
Estrazione di feature: Le CNN sono eccellenti nell'estrarre automaticamente feature gerarchiche dalle immagini, senza la necessità di ingegnerizzare manualmente i descrittori.
Invarianza alle trasformazioni: Grazie alle operazioni di convoluzione e pooling, le CNN sono in grado di riconoscere oggetti indipendentemente dalla loro posizione, scala o rotazione nell'immagine.
Grandi dataset: L'apprendimento supervisionato richiede grandi quantità di dati etichettati, che sono disponibili in abbondanza nel campo della visione artificiale.
4. Reti Neurali Generative Adversariali (GAN)
Le GAN rappresentano un importante passo avanti nell'evoluzione dell'IA generativa, sono composte da due reti neurali che competono tra loro: un generatore e un discriminatore, vengono utilizzate per generare dati sintetici (immagini, musica) e manipolare immagini, come mostrano gli esempi seguenti:
Generazione di immagini: sono utilizzate per creare immagini fotorealistiche di oggetti o persone che non esistono.
Generazione di dati sintetici: possono essere utilizzate per generare dati sintetici per l'addestramento di altri modelli, come immagini mediche o dati finanziari.
Trasferimento dello stile: possono essere utilizzate per trasferire lo stile di un'immagine ad un'altra, come trasformare una foto in un dipinto.
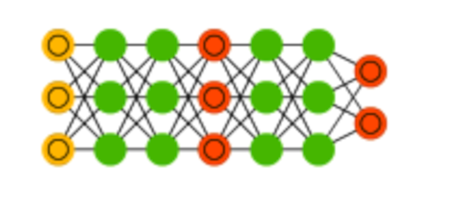
Esitono molte varianti delle GAN tra queste le più conosciute sono le architetture: DCGAN e StyleGAN.
DCGAN (Deep Convolutional GAN)
Utilizza principalmente convoluzioni e deconvoluzioni (o trasposte convoluzionali) per estrarre e generare caratteristiche dalle immagini. È un modello più generico, adatto a una vasta gamma di applicazioni di generazione di immagini. Può essere utilizzato per generare immagini di oggetti, scene, volti, ecc.
Ha una struttura semplice, facile da implementare e addestrare, ma non può produrre immagini con artefatti e meno dettagliate rispetto a modelli più avanzati.
StyleGAN
L'architettura è basata su DCGAN, ma introduce una serie di modifiche per migliorare la qualità delle immagini generate. Utilizza un'architettura a più livelli che permette di controllare in modo più preciso le caratteristiche delle immagini. Specializzata nella generazione di immagini fotorealistiche, in particolare di volti umani; le immagini generate sono di altissima qualità, con un controllo preciso sulle caratteristiche stilistiche e di identità.
E' più complessa da implementare e addestrare rispetto a DCGAN e richiede maggiori risorse computazionali.
In sintesi:
Le architetture DCGAN offrono un modello generico per generare immagini di diverse tipologie e non hai bisogno di una qualità estrema, mentre quelle StyleGAN permettono di generare immagini di altissima qualità, in particolare volti umani, se hai a disposizione risorse computazionali sufficienti.
DCGAN è un punto di partenza solido per chi si avvicina alle GAN, StyleGAN rappresenta lo stato dell'arte nella generazione di immagini fotorealistiche.
Apprendimento: non supervisionato, ma con una dinamica competitiva molto particolare.
A differenza dell'apprendimento supervisionato, dove ogni esempio di addestramento ha un'etichetta che indica la classe corretta, nelle GAN non ci sono etichette. Il generatore crea nuovi dati da solo, e il discriminatore deve solo determinare se un dato è reale o falso.
Le GAN imparano a generare nuovi dati plausibili osservando la distribuzione dei dati di addestramento, attraverso una dinamica competitiva.
Le GAN sono composte da due reti neurali: un generatore e un discriminatore; la prima creare nuovi dati (es. immagini, testi) che siano il più possibile indistinguibili dai dati reali, la seconda distinguere tra i dati reali e quelli generati dal generatore cercando di classificarle correttamente. Entrambi i modelli vengono aggiornati attraverso la retropropagazione dell'errore. Il generatore cerca di ingannare il discriminatore, mentre il discriminatore cerca di diventare sempre più bravo a distinguere i dati reali da quelli falsi. L'addestramento continua fino a raggiungere un equilibrio, dove il generatore è in grado di creare dati così realistici che il discriminatore non riesce più a distinguerli dai dati reali.
Perché è così speciali le reti neurali GAN?
Le GAN sono in grado di generare dati nuovi e originali, aprendo la porta a numerose applicazioni creative, come la generazione di immagini artistiche, la creazione di video realistici e la sintesi vocale. Trovano applicazione in molti campi, dalla visione artificiale al trattamento del linguaggio naturale, dalla generazione di dati sintetici alla modellazione di sistemi complessi.
5. Transformer
L'ultima forntiera delle reti neurali artificiali, sono i transformer, reti basate su un meccanismo di attenzione che permettono di pesare l'importanza di diverse parti dell'input, sono particolarmente efficaci per l'elaborazione del linguaggio naturale.
I modelli di questo tipo più conosciuti sono: GPT, BERT, T5.
GPT (Generative Pre-trained Transformer)
La famiglia di modelli GPT, sviluppata da OpenAI, è nota per la sua capacità di generare testo di alta qualità e coerente. GPT-3, ad esempio, è uno dei modelli linguistici più grandi e potenti al mondo.
BERT (Bidirectional Encoder Representations from Transformers)
Sviluppato da Google, BERT è un modello bidirezionale pre-addestrato che ha ottenuto risultati eccellenti in numerosi compiti di NLP.
T5 (Text-to-Text Transfer Transformer)
Un altro modello sviluppato da Google, T5 unifica diversi compiti di NLP in un unico framework di trasformazione testo-testo.
L'immagine seguente rappresenta l'architettura di base di un modello transformer. Si focalizza sulla struttura encoder-decoder che è tipica per compiti come la traduzione automatica neurale (NMT).
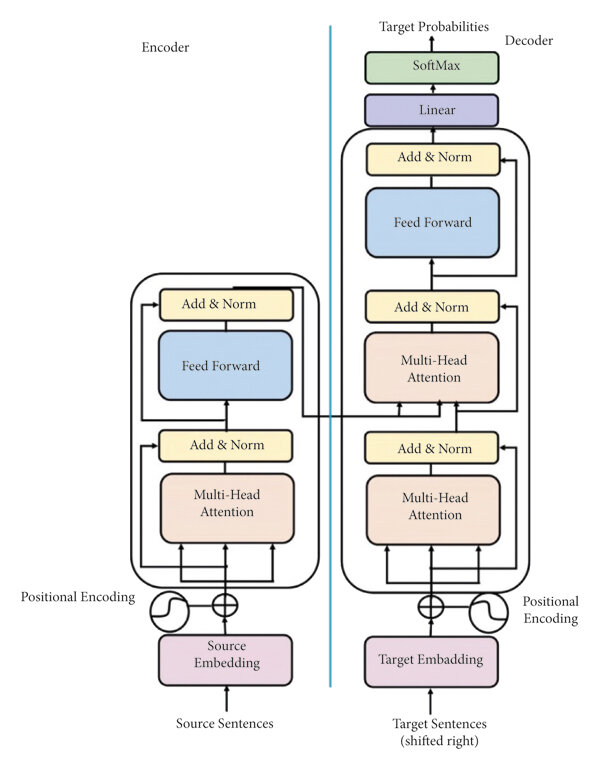
Encoder
Embedding: la sequenza di input (es. una frase in una lingua sorgente) viene prima convertita in una rappresentazione numerica, chiamata embedding. Questa rappresentazione cattura le informazioni semantiche e sintattiche delle parole.
Positional Encoding: vengono aggiunte informazioni sulla posizione delle parole all'interno della sequenza. Questo è cruciale perché i Transformer non hanno un concetto intrinseco di sequenzialità.
Multi-Head Attention: Questo è il cuore dei Transformer. Consente al modello di pesare l'importanza di diverse parti dell'input quando genera l'output. Ogni "testa" di attenzione si focalizza su aspetti diversi della sequenza.
Feed Forward: Un semplice layer di rete neurale che applica una trasformazione non lineare alle rappresentazioni.
Add & Norm: una combinazione di un'operazione di somma e una normalizzazione layer-wise. Serve a stabilizzare l'addestramento e migliorare le prestazioni.
Decoder
Embedding e Positional Encoding: simili all'encoder, ma con una piccola differenza: la sequenza target viene shiftata di un passo a destra. Questo evita che il modello copi direttamente l'input.
Masked Multi-Head Attention: simile all'attenzione dell'encoder, ma con una maschera che impedisce al modello di "vedere" le parole future quando genera l'output.
Encoder-Decoder Attention: permette al decoder di concentrarsi sulle parti rilevanti dell'input dell'encoder.
Feed Forward e Add & Norm: stessi componenti dell'encoder.
Softmax: Produce una distribuzione di probabilità sulle parole del vocabolario. La parola con la probabilità più alta viene selezionata come output.
Flusso di informazioni
Encoder: l'encoder processa la sequenza di input, creando una rappresentazione contenitiva delle relazioni tra le parole.
Decoder: il decoder genera la sequenza di output un token alla volta, utilizzando l'informazione dall'encoder e dalle parole già generate.
Perché i transformer sono così potenti?
Il meccanismo di attenzione permette di calcolare le relazioni tra tutte le parole in parallelo, rendendo il modello più efficiente. L'attenzione permette al modello di catturare le relazioni tra parole che sono lontane tra loro nella sequenza.
I transformer possono essere applicati a una vasta gamma di compiti di NLP, dalla traduzione automatica alla generazione di testo. Rappresentano un'architettura di rete neurale che ha rivoluzionato il campo del deep learning, in particolare nel settore del linguaggio naturale.
La caratteristica distintiva dei transformer è il meccanismo di auto-attenzione. Questo meccanismo permette al modello di pesare l'importanza di diverse parti dell'input quando genera l'output.
In parole più semplici, il transformer è in grado di "capire" il contesto di una parola all'interno di una frase, considerando le parole che la precedono e quelle che la seguono.
A differenza delle reti ricorrenti (RNN) che processano le frasi in modo sequenziale, i transformer possono catturare dipendenze tra parole molto distanti nella frase, rendendoli particolarmente adatti per compiti come la traduzione automatica e la generazione di testo.
L'auto-attenzione consente al transformer di elaborare l'intera sequenza in parallelo, rendendo l'addestramento più efficiente rispetto alle RNN e CNN.
La maggior parte dei transformer utilizzati per il linguaggio naturale è composta da un encoder e un decoder. L'encoder mappa la sequenza di input in una rappresentazione latente, mentre il decoder genera la sequenza di output. Inoltre, attraverso il meccanismo del multi-head attention riescono a catturare diverse tipologie di dipendenze all'interno dei dati.
Gli strati Feed-forward neural network aggiungono la non-linearità al modello, permettendo di estrarre caratteristiche più complesse, dimostrando di ottenere prestazioni superiori alle reti neurali tradizionali in numerosi compiti di NLP, come la traduzione automatica, la generazione di testo, la risposta a domande e la comprensione del linguaggio naturale. Inoltre, l'architettura dei transformer è molto versatile e può essere applicata a una vasta gamma di compiti, oltre al linguaggio naturale.
I transformer, attraverso un'attività di fine-tuning, possono essere addestrati su grandi quantità di dati, consentendo di creare modelli sempre più potenti e sofisticati.
Nel prossimo articolo vi parlerò dell'Intelligenza Artificiale Generativa e cosa cambia.
1.Intelligenza Artificiale: se la conosci non la temi
2.Intelligenza Artificiale: i modelli linguistici di grandi dimensioni
3.Intelligenza Artificiale: le reti neurali artificiali
5.Intelligenza Artificiale: IA Generativa
6.Intelligenza Artificiale: modelli pre-addestrati di IA locali
7.Intelligenza Artificiale: come creare una chatbot per conversare con Llama3
8.Intelligenza Artificiale: come addestrare LLAMA3 attraverso un Fine-Tuning di tipo no coding
9.Intelligenza Artificiale: cosa dobbiamo sapere su ai act e deepfake
10.Intelligenza Artificiale: Cosa cambia nel mondo del lavoro
