 Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy
Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy





Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy


-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-
Categoria: Home
6.L'Assicurazione della Qualità nell'IFP
![]() Gino Visciano |
Gino Visciano |
 Skill Factory - 24/01/2026 00:01:12 | in Home
Skill Factory - 24/01/2026 00:01:12 | in Home
Prima di approfondire il tema dell'Assicurazione della Qualità nell'Istruzione e Formazione Professionale (IFP), è fondamentale chiarire la distinzione tra tre concetti spesso sovrapposti: Educazione, Istruzione e Formazione.

Educazione (Saper essere)
L'educazione riguarda la sfera dei valori, del comportamento e della personalità. È un processo che dura tutta la vita e serve a formare il cittadino e l'individuo. L'obiettivo dell'educazione è trasmettere i principi etici, civici e sociali che costituiscono la base dell'identità delle persone.
Istruzione (Sapere)
L'istruzione riguarda l'acquisizione di conoscenze teoriche e concetti astratti. È il tipico percorso scolastico o accademico tradizionale che fornisce le basi culturali necessarie. L'obiettivo dell'istruzione è fornire agli studenti un bagaglio di informazioni e nozioni (il "cosa").
Formazione (Saper fare)
La formazione è il cuore pulsante dell'IFP. È il processo mirato ad acquisire competenze pratiche e professionalizzanti per svolgere un compito specifico o un mestiere. In sintesi, è la capacità di trasformare la conoscenza in azione (il "come"). L'obiettivo della formazione è fornire competenze concrete e spendibili.
L’Assicurazione della Qualità (AQ) nell'IFP
Assicurare la qualità nell'Istruzione e Formazione Professionale significa garantire che ogni attività formativa sia pertinente, efficace e coerente con gli obiettivi previsti. Se l'Assicurazione della Qualità rappresenta il processo, gli obiettivi ne costituiscono la meta.
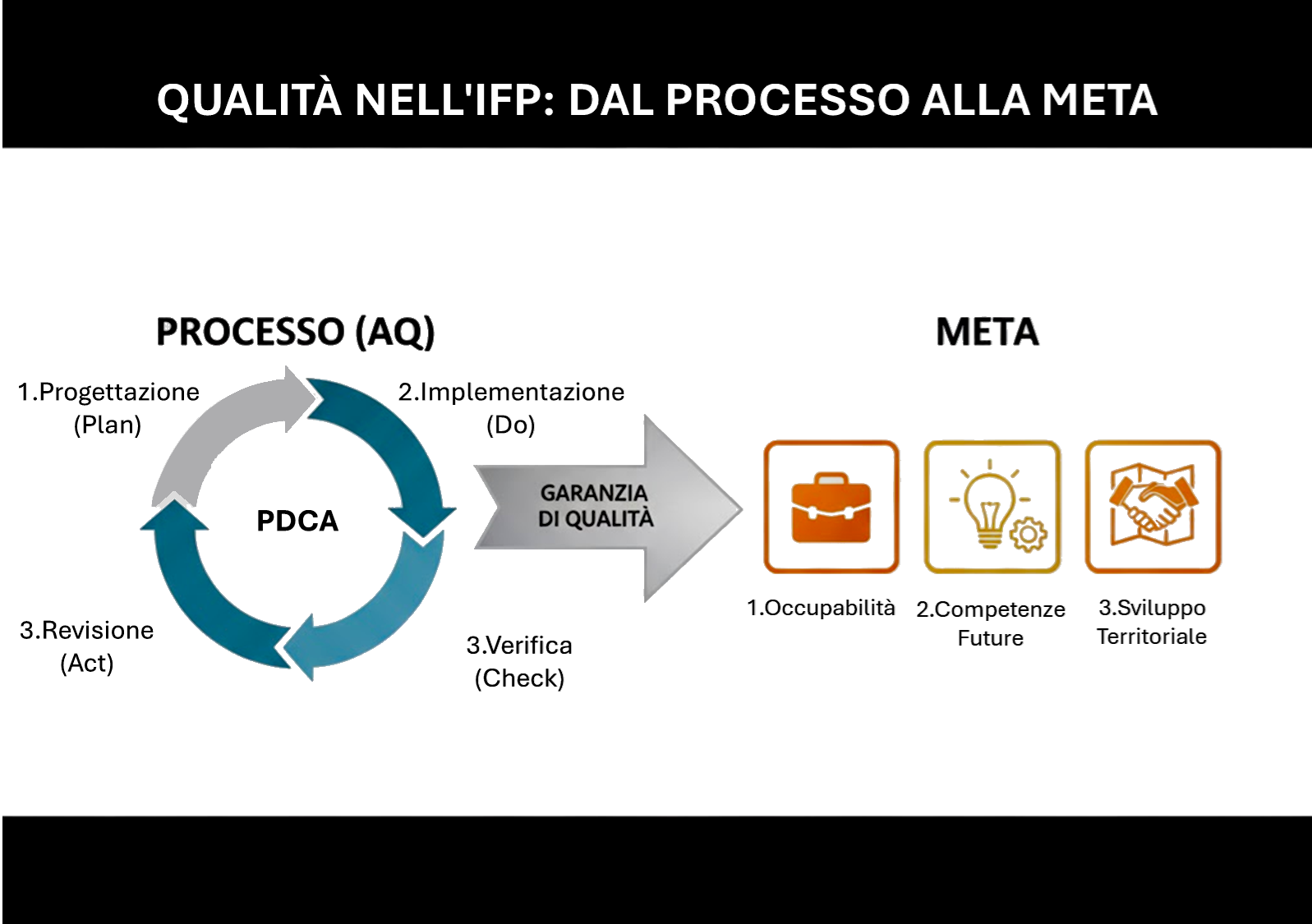
In questo contesto, gli obiettivi non riguardano solo il "sapere", ma soprattutto il "saper fare" e il "saper essere". Gli obiettivi principali dell'IFP si possono riassumere in tre aree:
1.Obiettivi di Occupabilità: Riduzione del mismatch tra domanda e offerta, inserimento lavorativo rapido e certificazione delle competenze per rendere il profilo dello studente competitivo sul mercato.
2.Obiettivi Educativi e Metodologici: Apprendimento esperienziale ("imparare facendo"), sviluppo di soft skills e promozione dell'apprendimento permanente (lifelong learning), fondamentale in settori ad alta evoluzione come l'Intelligenza Artificiale.
3.Obiettivi Strategici per il Territorio: Supporto all'innovazione aziendale, inclusione sociale e capacità di adattare i programmi alle evoluzioni tecnologiche e normative.
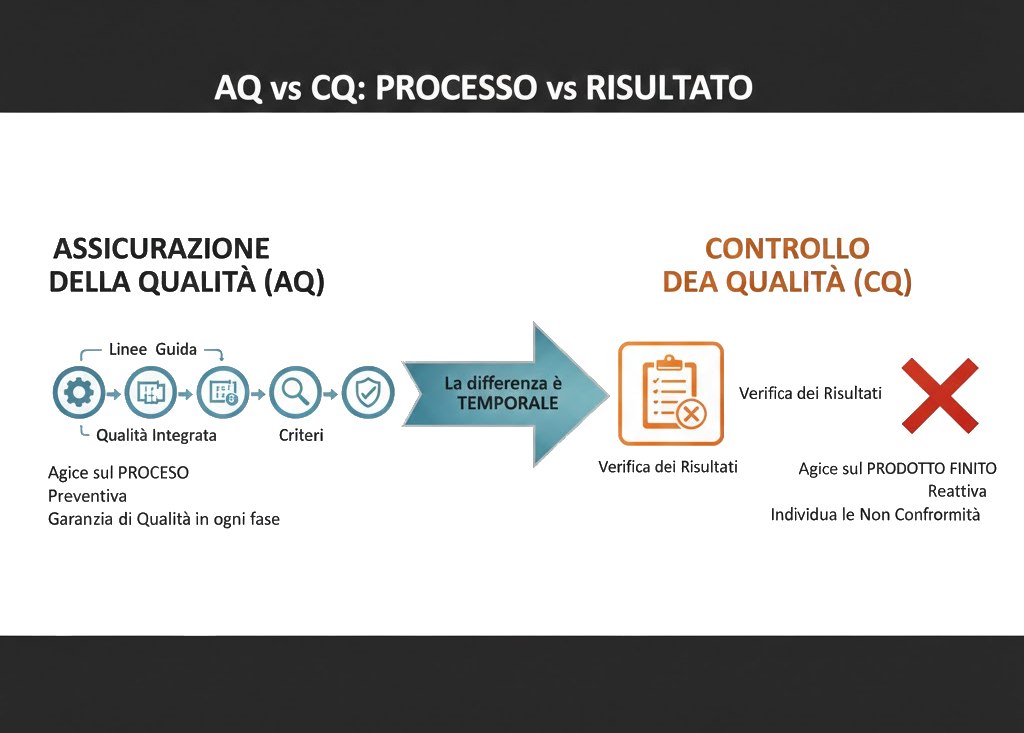
Differenza tra Assicurazione della Qualità (AQ) e Controllo della Qualità (CQ)
È essenziale distinguere tra Assicurazione della Qualità (AQ) e Controllo della Qualità (CQ), queste due funzioni spesso confuse:
L'Assicurazione della Qualità (AQ) agisce sul processo. Stabilisce preventivamente le linee guida, le metodologie, i criteri e le regole da rispettare per garantire che la qualità sia integrata in ogni fase.
Il Controllo della Qualità (CQ) interviene invece a valle per verificare i risultati prodotti. Il suo scopo è individuare eventuali non conformità una volta che il processo è terminato.
L'Unione Europea: Le Raccomandazioni
L'Unione Europea, attraverso le Raccomandazioni, indica agli Stati membri gli obiettivi comuni da seguire per assicurare la qualità e modernizzare i sistemi formativi. Poiché l'istruzione è una competenza dei singoli Stati, l'UE non impone leggi uniche, ma utilizza le Raccomandazioni per creare un linguaggio comune e definire i risultati attesi.

Le Raccomandazioni e gli strumenti più rilevanti sono:
1.EQF (European Qualifications Framework): Istituito nel 2008 e aggiornato nel 2017, è la griglia che definisce gli 8 livelli di competenza. Permette di confrontare i titoli di studio tra nazioni diverse, spostando il focus dall'input (cosa si è studiato) all'output (risultati di apprendimento).
2.EQAVET (European Quality Assurance in Vocational Education and Training): Adottato nel 2009 e rafforzato nel 2020, è il modello specifico per l'assicurazione della qualità nell'IFP. Introduce un ciclo di gestione (PDCA) per garantire il monitoraggio e il miglioramento costante dei corsi.
3.Europass: Nato nel 2004 e rinnovato nel 2018, è lo standard per la trasparenza delle competenze. Trasformatosi in piattaforma digitale, permette di rendere le qualifiche comprensibili ai datori di lavoro di tutta Europa.
Storicamente, questi strumenti sono il frutto di un'evoluzione ventennale volta a creare lo Spazio Europeo dell’Istruzione e della Formazione, garantendo che ogni percorso formativo gli obiettivi attesi dagli Stakeholder.
Approfondimenti:
5.L'Etica della formazione come responsabilità professionale.
4 Buona Formazione: "Come assicurare la qualità della formazione".
3.La qualità della formazione inizia dal confronto.
2.La filiera della Formazione Professionale in Europa e in Italia.
1.Sei uno studente oppure un lavoratore? Scopri qual è il tuo livello di EQF.
Vuoi diventare un "Esperto di Qualità" nell'IFP e migliorare la qualità della Formazione Professionale svolgendo il ruolo di "Pari"?
Il "Pari", è un esperto di "Metodologia Peer Review di EQAVET", collabora con il Natrional Reference Point EQAVET italiano, presso INAPP, per valutare, attraverso visite in loco, gli Istituti/Centri di Formazione della filiera IFP.
Skill Factory in collaborazione con INAPP (Istituto Nazionale per l'Analisi delle Politiche Pubbliche) promuove il corso:
"Metodologia della Peer Review di EQAVET e principali strumenti di autovalutazione nell'IFP".
Sono previste solo due sessioni ad aprile 2026, di 15 partecipanti ciascuna.
Clicca qui per maggiori informazioni oppure consulta il sito www.skillfactory.it.


Skill Factory 2025: Un anno di formazione tra "Innovazione (AI), Qualità (EQAVET) e Politiche Attive del Lavoro (PAR GOL)"
![]() Gino Visciano |
Skill Factory - 30/12/2025 20:41:27 | in Home
Gino Visciano |
Skill Factory - 30/12/2025 20:41:27 | in Home
Il 2025 per noi si chiude con un traguardo fondamentale: aver dimostrato che la nostra visione olistica della formazione insieme a Innovazione (AI), Qualità (EQAVET) e Politiche Attive del Lavoro (PAR GOL) sia stata strategica per generare valore e favorire l'inserimento dei giovani nel mondo del lavoro attraverso lo sviluppo di competenze tecniche e competenze trasversali.

Il successo di quest'anno nasce soprattutto dalla forza della nostra rete di partner: un ecosistema composto da Scuole professionali, Istituti Tecnici, Centri di formazione, ITS, Aziende e Agenzie per il lavoro, interconnessi con un unico obiettivo condiviso: "Favorire l'inserimento dei giovani nel mondo del lavoro".
Non ci siamo limitati a insegnare l'Intelligenza Artificiale, ma l'abbiamo adottata per aumentare le conoscenze e le abilità dei nostri docenti, migliorare la qualità dei nostri corsi, rendere più efficace la didattica e gli strumenti di valutazione.
LA QUALITA' DELLA FORMAZIONE INIZIA DAL CONFRONTO
Grazie alla collaborazione con INAPP, abbiamo portato la metodologia europea della Peer Review al centro del nostro modello formativo, introducendo stabilmente la filosofia del miglioramento continuo.

Ad aprile, per valutare la qualità del nostro Centro di Formazione, abbiamo organizzato una visita tra "Pari" in collaborazione con INAPP (Istituto Nazionale per l'Analisi delle Politiche Pubbliche), che ospita il National Reference Point (NRP) EQAVET italiano.

I "Pari" sono professionisti del settore (formazione, istruzione, politiche attive del lavoro) che non fanno parte dell’organizzazione valutata, esperti di metodologia Peer Review, un sistema chiave per migliorare la qualità della formazione professionale in Italia e in Europa.
Grazie al "Report di Verifica" redatto dai "Pari" durante la visita, abbiamo realizzato un "Piano d'Azione" per migliorare ulteriormente i processi di gestione delle nostre attività di lavoro.
IL PROGRAMMA PAR GOL
L'attuazione del Programma GOL, attraverso i fondi del PNRR e in stretta collaborazione con la Regione Campania, è stata la nostra sfida più grande e gratificante. Abbiamo trasformato le risorse del Piano Nazionale di Ripresa e Resilienza in reali opportunità occupazionali attraverso i seguenti percorsi di formazione, individuati grazie a un'analisi di mercato approfondita e focalizzati sulle professioni digitali e amministrative più richieste:
1. ANALISTA PROGRAMMATORE;
2. TECNICO DELLA PROGRAMMAZIONE E DELLO SVILUPPO DI PROGRAMMI INFORMATICI;
3. TECNICO PROGRAMMATORE DI SITI WEB;
4. TECNICO DELLA PROGETTAZIONE, IMPLEMENTAZIONE E MANUTENZIONE DI SISTEMI DI GESTIONE DI DATABASE;
5. TECNICO ESPERTO DI SICUREZZA INFORMATICA;
6. SEGRETARIO COORDINATORE AMMINISTRATIVO;
7. OPERATORE DELLA PROMOZIONE E ACCOGLIENZA TURISTICA;
8. ASSISTENZA ALL'UTENZA MUSEALE.
I NUMERI CHE DESCRIVONO IL NOSTRO IMPEGNO
Durante l'anno, abbiamo selezionato e formato oltre 300 giovani diplomati, il loro impegno si è tradotto in competenza ed esperienza pratica fatta sul campo attraverso gli stage aziendali.

Alla fine di ogni percorso di formazione, tutti gli studenti hanno acquisito un titolo Europeo di Qualificazione Professionale di livello EQF 3 o EQF 5 (EQF - European Qualifications Framework).
Per il 40% degli studenti, l'esperienza si è trasformata in un contratto di occupazione concreto e stabile.
Nel 2025 abbiamo erogato circa 4000 ore di attività complessive, come mostra la tabella seguente:
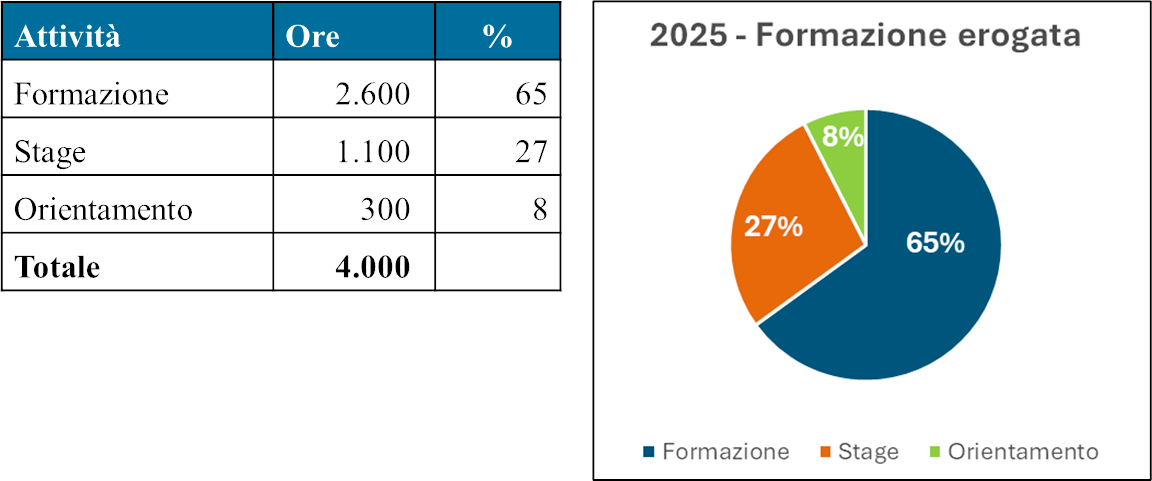
La Formazione in Aula (2.600 ore totali), è stata erogata con le seguenti modalità:
• 1.600 ore in Didattica in Presenza (DIP), per favorire il confronto diretto e l'apprendimento pratico.
• 1.000 ore in Didattica a Distanza (DAD) con docente in modalità sincrona, per abbattere le barriere geografiche.

I NUMERI CHE INDICANO LA NOSTRA QUALITA'
Per noi, la qualità è un processo dinamico di miglioramento continuo. Crediamo fermamente che per valorizzare le risorse umane sia necessario un sistema di monitoraggio rigoroso, capace di garantire che ogni percorso formativo risponda realmente alle esigenze del mercato e alle ambizioni dei nostri studenti.
Per misurare l'efficacia del nostro lavoro, monitoriamo i principali indicatori EQAVET che ci permettono di valutare la Qualità del nostro ciclo di formazione:
1. Tasso di Partecipazione degli studenti: Misura l'attrattività e l'accessibilità dei nostri percorsi sul territorio.
2. Tasso di Completamento dei percorsi: Valuta l'efficacia della nostra didattica e la capacità di supportare lo studente fino al raggiungimento dell'obiettivo.
3. Tasso di Inserimento Lavorativo: L'indicatore più critico, che certifica la coerenza tra le competenze trasmesse e la domanda reale delle aziende partner.
Di seguito, presentiamo i dati consolidati del 2025, che testimoniano la solidità del nostro modello:
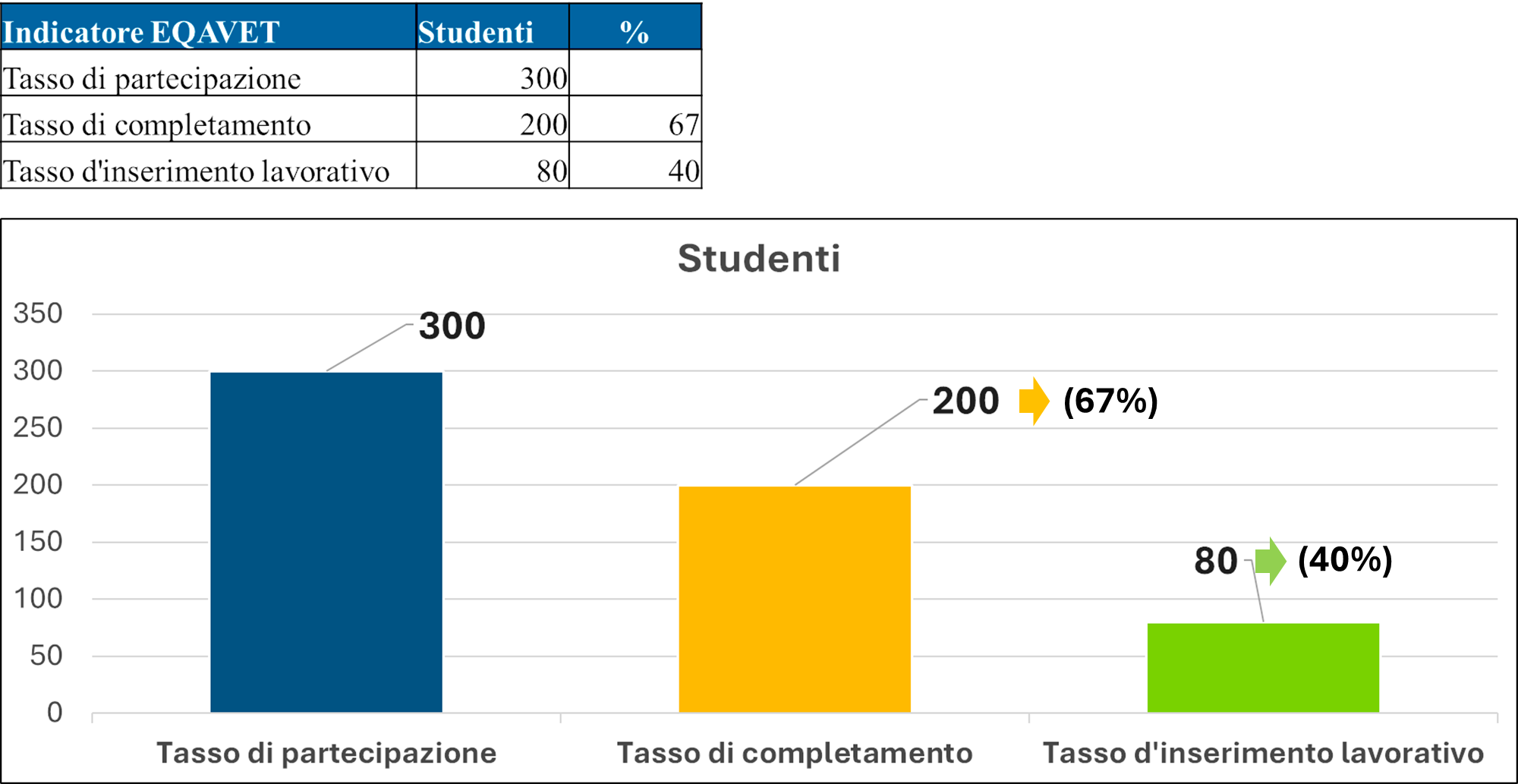
Questi risultati mostrano come, su un bacino di 300 partecipanti, ben 200 studenti (67%) abbiano completato con successo il percorso formativo e conseguito una qualifica di formazione superiore di livello EQF 3 o EQF 5.
Particolarmente significativo è il dato sull'occupazione: 80 diplomati (40%) hanno ottenuto un inserimento lavorativo stabile, a conferma di una strategia di placement che trasforma le competenze e l'esperienza acquisite in posti di lavoro reali.
Approfondimenti:
1. L'Etica della Formazione come responsabilità professionale.
2. Buona Formazione: "Come assicurare la qualità della formazione.
3. La qualità della formazione inizia dal confronto.
4. La filiera della Formazione Professionale in Europa e in Italia.
5. Sei uno studente oppure un lavoratore? Scopri qual è il tuo livello di EQF.
6. CV Story (Gino Visciano): "dalle schede perforate al primo Personal computer in rete" - gli anni '80
10.Intelligenza Artificiale: cosa cambia nel mondo del lavoro
![]() Gino Visciano |
Skill Factory - 21/12/2025 17:30:41 | in Home
Gino Visciano |
Skill Factory - 21/12/2025 17:30:41 | in Home
«L'Intelligenza Artificiale non pensa per noi, ma espande i confini di ciò che la nostra mente può concepire e immaginare...»
Quando si parla di intelligenza artificiale, la domanda più frequente è: "cosa cambierà e se sostituirà l'intelligenza umana?"
L'attuale IA, quella debole, applicata nel mondo del lavoro può essere considerata semplicemente come l'aumento delle nostre capacità intellettuali.

Dire che l’IA aumenta le nostre capacità intellettuali significa riconoscere che alcune funzioni cognitive come:
• analizzare grandi quantità di informazioni;
• individuare pattern;
• sintetizzare contenuti;
• generare alternative;
possono essere svolte in modo più rapido ed efficace con il supporto di sistemi di intelligenza artificiale. Non perché “pensino meglio”, ma perché operano su scale e velocità superiori a quelle umane.
COSA VUOL DIRE, IN CONCRETO, “AUMENTARE LE CAPACITÀ INTELLETTUALI”
Nel lavoro quotidiano, gran parte dell’attività intellettuale non consiste nel prendere decisioni strategiche, ma nel preparare il contesto per poterle prendere, ad esempio: raccogliere dati, leggerli, confrontarli, riassumerli, verificare ipotesi. Sono attività cognitive a tutti gli effetti, ma ripetitive e dispendiose in termini di tempo.

L’IA interviene proprio qui, perché:
• riduce il tempo necessario per arrivare a una visione d’insieme;
• propone alternative valide e nuove idee;
• abbassa il costo cognitivo di analisi complesse;
• rende accessibili capacità avanzate anche a chi non è uno specialista.
Ad esempio, analizzare decine di documenti, report o mail non è difficile dal punto di vista concettuale, ma lo è dal punto di vista pratico. Un sistema IA può farlo in pochi secondi, lasciando alla persona il compito più rilevante che è quello di capire cosa fare di quelle informazioni.
L’importanza dell’IA non sta tanto nell’automazione in sé, quanto nel suo impatto sul modo in cui le persone usano il tempo e l’attenzione. Quando il carico cognitivo di base diminuisce, emergono nuove possibilità:
• più spazio per il ragionamento critico;
• maggiore attenzione al contesto e alle implicazioni;
• decisioni meglio informate, anche in tempi rapidi.
L'IA non serve per “pensare al posto nostro”, ma serve per "pensare meglio".
È importante chiarire un equivoco frequente! Aumentare le capacità intellettuali non significa delegare il pensiero all’IA, ma significa usare strumenti che migliorano la qualità del pensiero umano, così come il calcolo automatico ha migliorato l’ingegneria o il foglio di calcolo ha trasformato la contabilità.
L’IA:
• propone, ma non decide;
• suggerisce, ma non assume responsabilità;
• accelera, ma non dà senso alle cose.
L'IA non ha l'etica e l'empatia, i pilastri che sorreggono ogni decisione che impatta sulle persone, quindi la responsabilità delle scelte è degli uomini.
PERCHÉ QUESTO RIGUARDA TUTTI
L'aumento cognitivo non è limitato solo a ruoli tecnici o altamente specializzati, ma riguarda chiunque lavori con informazioni, testi, dati e deve prendere decisioni, come ad esempio:
• impiegati;
• manager;
• studenti;
• professionisti.
La differenza non la fa il settore, ma la capacità di integrare l’IA nei propri processi mentali e lavorativi.

Chi impara a usarla come supporto al pensiero:
• lavora meglio e più velocemente;
• apprende più in fretta;
• affronta problemi più complessi con meno difficoltà.
L'introduzione dell'IA nelle aziende riduce costi e tempi, mentre i professionisti che la sanno usare aumenteranno il proprio valore di mercato.
Chi ignora l'IA rischia di restare indietro non perché “sostituito da una macchina”, ma perché meno efficiente di chi la usa.
VANTAGGI CONCRETI DELL'IA NEL MONDO DEL LAVORO
L'utilizzo dell'IA nel mondo del lavoro, concretamente offre i vantaggi seguenti:
• automazione delle attività ripetitive;
• aumento della produttività individuale;
• maggiore valore alle competenze decisionali.
Per le aziende questo si traduce in:
• meno tempo su compiti a basso valore;
• supporto decisionale continuo;
• migliore utilizzo dei dati già disponibili;
• riduzione degli errori operativi.

Naturalmente non bisogna dimenticare che l'IA non comprende il contesto umano come una persona e può sbagliare in modo convincente (Allucinazioni).
PERCHÉ INTRODURRE L’IA IN AZIENDA NON È PIÙ OPZIONALE
Introdurre l’IA in azienda oggi non significa essere “innovativi”, ma rimanere "competitivi". La maggior parte delle organizzazioni non parte da zero: dispone già di dati, processi digitali, strumenti informatici. L’IA agisce come un moltiplicatore di valore su ciò che esiste già.
Le aziende che usano l'IA ottengono i seguenti vantaggi cumulativi:
• imparano prima a usarla correttamente;
• costruiscono più velocemente le competenze interne;
• migliorano i processi in modo incrementale.
Chi rimanda, invece, non resta fermo, ma accumula ritardo.
Il punto critico è la formazione delle persone. La tecnologia, da sola, non produce risultati; il vero fattore discriminante è la capacità delle persone di usarla in modo consapevole.
Formarsi sull’IA oggi non significa diventare data scientist o programmatori, ma:
• capire cosa può e cosa non può fare;
• saperla integrare nel proprio lavoro quotidiano;
• valutare criticamente gli output.
La cosa importante è acquisire la cultura e la mentalità giuste per imparare a lavorare con il supporto dell'IA.
Un’organizzazione può acquistare gli strumenti migliori, ma senza competenze interne rischia:
• di usarli male;
• di non usarli affatto;
• affidarsi a decisioni automatizzate senza controllo.
DA DOVE INIZIARE
Per evitare approcci confusi o puramente sperimentali, l’introduzione dell’IA dovrebbe seguire i seguenti passaggi chiave.

1. Individuare i processi a maggior impatto
Non “mettere l’IA ovunque”, ma partire da:
• attività ripetitive;
• flussi informativi complessi;
• colli di bottiglia operativi.
2. Coinvolgere le persone che lavorano sui processi
Chi conosce il lavoro quotidiano è fondamentale per:
• identificare inefficienze reali;
• valutare se l’IA produce valore o solo rumore.
3. Introdurre strumenti semplici e misurare i risultati
Meglio piccoli esperimenti controllati che grandi progetti astratti; il criterio non è la novità, ma il miglioramento misurabile.
4. Investire nella formazione continua
La formazione non è un evento una tantum, ma un processo che prevede:
• apprendimento pratico;
• aggiornamento costante;
• condivisione delle buone pratiche.
I RISCHI DI NON AGIRE
I principali rischi che corriamo se non usiamo l’IA o se non la usiamo correttamente perché non siamo stati formati adeguatamente sono i seguenti:
1. Perdita di competitività: stessi costi, meno produttività rispetto ai concorrenti;
2. Decisioni più lente e meno informate: quando il mercato accelera, la lentezza diventa un problema strategico;
3. Dipendenza da competenze esterne: mancanza di autonomia e maggiore esposizione a errori;
4. Uso improprio o inconsapevole dell’IA: strumenti usati senza controllo aumentano i rischi, non li riducono;
5. GAP culturale: subire il cambiamento invece di governarlo.
L’intelligenza artificiale non è una scelta tecnologica, ma organizzativa e culturale.
Le aziende e i professionisti che iniziano ora non avranno necessariamente più strumenti, ma più competenza nell’usare quelli disponibili.
Oggi la tecnologia corre più veloce della nostra capacità di adattamento. In questo scenario, l’unico vero rischio strategico è restare spettatori dei cambiamenti. L'uso consapevole dell'IA diventa quindi fondamentale per governare la complessità e trasformare il progresso tecnologico in un'opportunità di crescita, restando sempre alla guida dell'innovazione.
Nel prossimo articolo parleremo di come cambierà il mondo della formazione con l'intelligenza artificiale
1.Intelligenza Artificiale: se la conosci non la temi
2.Intelligenza Artificiale: i modelli linguistici di grandi dimensioni
3.Intelligenza Artificiale: le reti neurali artificiali
4.Intelligenza Artificiale: tipi di reti neurali artificiali
5.Intelligenza Artificiale: IA Generativa
6.Intelligenza Artificiale: modelli pre-addestrati di IA locali
7.Intelligenza Artificiale: come creare una chatbot per conversare con Llama3
8.Intelligenza Artificiale: come addestrare LLAMA3 attraverso un Fine-Tuning di tipo no coding
9.Intelligenza Artificiale: cosa dobbiamo sapere su ai act e deepfake
5.L’etica della formazione come responsabilità professionale
![]() Gino Visciano |
Skill Factory - 13/12/2025 18:42:20 | in Home
Gino Visciano |
Skill Factory - 13/12/2025 18:42:20 | in Home
L’etica della formazione si riferisce ai principi, ai valori e agli ideali che guidano l’agire educativo e formativo, concentrandosi sulla crescita culturale, civile e professionale della persona e sulla responsabilità di educatori e formatori. In altre parole, significa utilizzare l’educazione e la formazione per ciò che sono realmente, mettendo al centro i destinatari dell’azione educativa e formativa e le loro esigenze, senza farsi distrarre da altre finalità.

L’etica della formazione è una riflessione critica e un orientamento pratico che assicura che l’azione formativa sia non solo efficace, ma anche giusta, responsabile e orientata al bene comune e alla piena realizzazione della persona.
È POSSIBILE PARLARE DI ETICA DELLA FORMAZIONE SENZA SEMBRARE MORALISTI?
Secondo il mio punto di vista, sì.
Non solo è possibile, ma è necessario.
Basta trattare l’etica come criterio di qualità e non come elemento di giudizio.
Ecco un elenco di valori etici fondamentali nella formazione, concepiti per guidare sia l’agire educativo sia la progettazione dei percorsi formativi:
• Centralità dei destinatari: porre al centro le esigenze, i bisogni e lo sviluppo delle persone coinvolte;
• Responsabilità: assumersi la responsabilità delle scelte formative e dei loro effetti nel breve e nel lungo periodo;
• Trasparenza: essere chiari su finalità, metodi, criteri di valutazione e risultati attesi;
• Equità e inclusione: garantire pari opportunità di accesso e trattamento, valorizzando la diversità;
• Onestà intellettuale: fornire contenuti corretti, aggiornati e basati su evidenze, evitando manipolazioni o semplificazioni fuorvianti;
• Autonomia ed empowerment: favorire lo sviluppo della capacità critica e della responsabilità individuale dei partecipanti;
• Coerenza tra mezzi e fini: assicurare che metodologie, contenuti e obiettivi siano allineati;
• Sostenibilità: progettare percorsi formativi capaci di generare impatti duraturi, non solo risultati immediati;
• Rispetto della dignità: riconoscere il valore dell’esperienza e dell’apprendimento di ogni partecipante;
• Orientamento al bene comune: considerare gli effetti della formazione non solo sul singolo, ma anche sul contesto sociale e organizzativo.
Quando l’etica è trattata come criterio di qualità, consente di osservare le scelte formative sotto una luce professionale. Le considerazioni principali sono:
1. Non giudicare le persone, ma i processi e i risultati;
2. Spostare il focus dalle intenzioni agli impatti;
3. Trattare l’etica come competenza professionale;
4. Comunicare con concretezza e dati osservabili.
L’etica della formazione diventa così una leva per migliorare e assicurare la qualità della formazione, senza apparire moralisti.
IL RUOLO DEI FORMATORI E L’EQUILIBRIO TRA FORMAZIONE SINCRONA E ASINCRONA
Nel contesto dell’etica della formazione, è utile soffermarsi sul ruolo dei formatori e sul corretto equilibrio tra formazione sincrona (in presenza e a distanza) e formazione asincrona (e-learning).
Gli strumenti digitali e le piattaforme di e-learning hanno ampliato in modo significativo le possibilità di accesso, flessibilità e diffusione della formazione. In questo senso, la formazione a distanza rappresenta un supporto efficace e un amplificatore delle potenzialità di docenti e formatori.
Tuttavia, un approccio eticamente consapevole richiede di riconoscere che tali strumenti non possono sostituire completamente il ruolo del formatore. La relazione educativa, il confronto diretto e la capacità di leggere i contesti e le persone restano elementi fondamentali per una crescita professionale reale.
Questo aspetto emerge con particolare chiarezza nella formazione dei giovani, dove il contatto relazionale ed esperienziale tra studenti e docenti è centrale, e in ambiti come la formazione sulla sicurezza sul lavoro, in cui l’apprendimento non riguarda solo il trasferimento di informazioni, ma lo sviluppo di consapevolezza, atteggiamenti e senso di responsabilità. In questi casi, la comprensione reale dei rischi e delle conseguenze dei comportamenti non può essere affidata esclusivamente a strumenti di e-learning.

Un formatore competente trasmette non solo contenuti, ma anche cultura della prevenzione, attenzione e consapevolezza del rischio, elementi che nascono dall’interazione, dall’esperienza e dall’esempio.
L’etica della formazione invita quindi a ricercare un equilibrio: valorizzare le tecnologie come risorsa strategica, senza rinunciare alla presenza qualificata dei formatori, che rimane un fattore determinante per la qualità e l’efficacia dei percorsi formativi.
CONCLUSIONE
Rimettere al centro l’etica della formazione non significa introdurre nuovi vincoli né formulare giudizi, ma recuperare il senso profondo dell’agire educativo e formativo. In un contesto in cui strumenti, progetti e finanziamenti rischiano talvolta di diventare centrali, l’etica aiuta a mantenere lo sguardo orientato verso ciò che conta davvero: le persone e il loro sviluppo.
Assumere l’etica come criterio di qualità consente a dirigenti scolastici, docenti e formatori di compiere scelte più consapevoli, coerenti e sostenibili nel tempo. Non si tratta di opporsi al sistema, ma di rafforzarlo, rendendo la formazione non solo funzionale, ma autenticamente generativa.
In questa prospettiva, l’etica della formazione diventa una responsabilità professionale condivisa e una leva strategica per garantire percorsi formativi capaci di produrre valore reale, duraturo e orientato al bene comune.
Approfondimenti:
6.L'Assicurazione della Qualità nell'IFP.
4 Buona Formazione: "Come assicurare la qualità della formazione".
3.La qualità della formazione inizia dal confronto.
2.La filiera della Formazione Professionale in Europa e in Italia.
1.Sei uno studente oppure un lavoratore? Scopri qual è il tuo livello di EQF.
4.Buona Formazione: "Come assicurare la Qualità della Formazione"
![]() Gino Visciano |
Skill Factory - 06/12/2025 12:20:37 | in Home
Gino Visciano |
Skill Factory - 06/12/2025 12:20:37 | in Home
Oggi parlare di "Buona Formazione" non è un esercizio teorico, ma una necessità concreta. In un mercato del lavoro che evolve rapidamente, la qualità dei percorsi formativi fa la differenza nella crescita professionale dei giovani, nella competitività delle imprese e nella credibilità degli enti di formazione, soprattutto quelli della Campania, dopo il sevizio della trasmissione "Quarata Repubblica" condotta di Nicola Porro.
Ma cosa significa davvero “Buona formazione”?
Garantire una “Buona formazione” significa poter dimostrare che ciò che si fa è efficace, coerente e orientato ai risultati, mettendo al centro dell'azione formativa gli studenti e misurare, con responsabilità e trasparenza, ciò che la formazione produce, ovvero: competenze reali, opportunità di lavoro, crescita personale e professionale.
La "Buona formazione" si garantisce attraverso tre principi chiave:
1. La Centralità degli studenti;
2. Collegamento con il lavoro;
3. Un sistema di garanzia della qualità basato sui dati.
Ogni percorso formativo di qualità deve partire dai bisogni reali degli studenti e offrire loro:
• competenze tecniche solide e aggiornate;
• competenze trasversali essenziali;
• orientamento continuo;
• accompagnamento attivo verso il lavoro.
"La qualità della formazione è reale solo se migliora la vita delle persone".
Il lavoro non è un risultato “a valle” della formazione, ma un criterio di qualità.
La buona formazione deve essere misurabile attraverso indicatori riconosciuti, come quelli definiti dal modello europeo EQAVET (European Quality Assurance in Vocational Education and Training) fondamentali per assicurare la qualità nell'istruzione e formazione professionale (IFP).
Misurare gli indicatori significa trasformare l’idea di qualità in un processo concreto, monitorabile e orientato al miglioramento continuo.
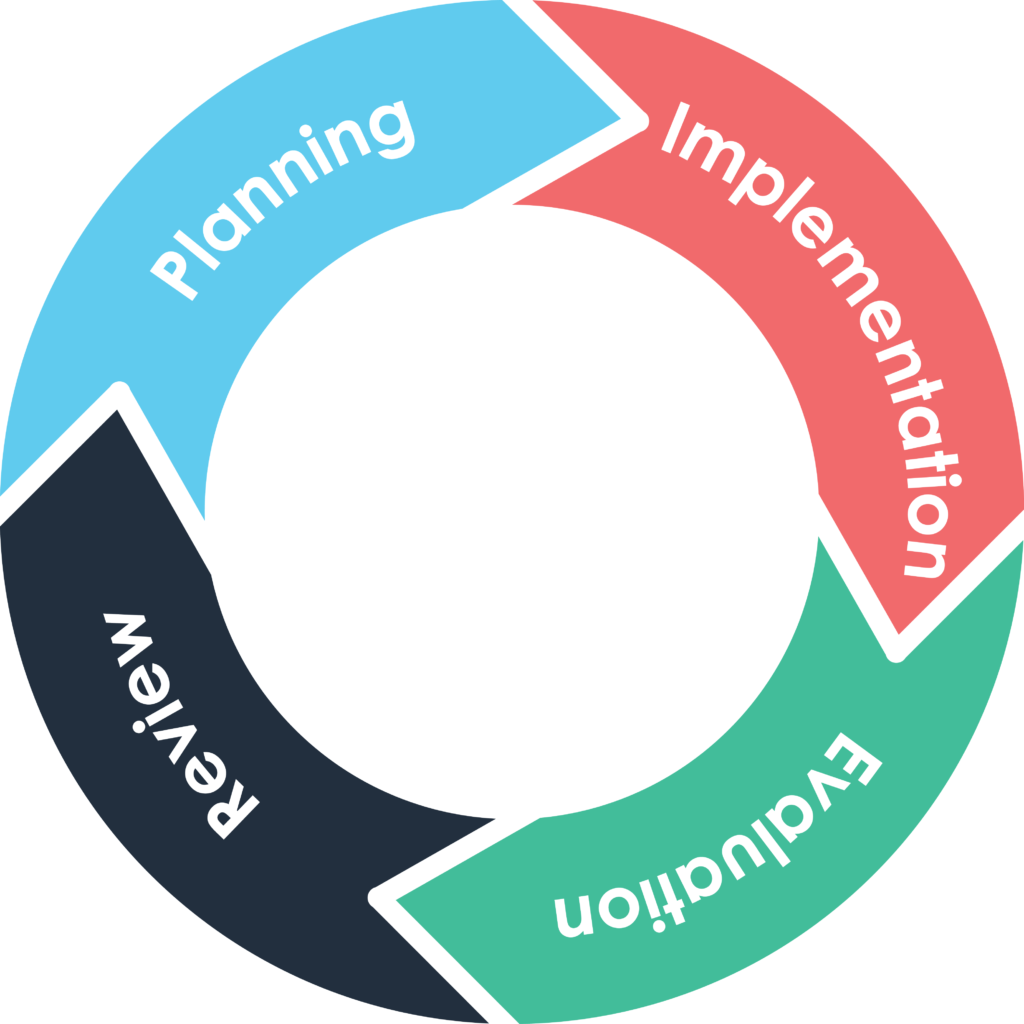
In Skill Factory per garantire la qualità della nostra formazione, costruiamo percorsi altamente professionalizzanti per giovani diplomati e laureati, formando ogni anno oltre 200 studenti nei seguenti profili professionali:
• programmatori;
• software tester;
• sistemisti operativi;
• coordinatori amministrativi;
• esperti ERP;
• specialisti Marketing, Vendite e CRM.
A tutti garantiamo competenze tecniche aggiornate e un forte impegno sullo sviluppo delle soft skills.
Per noi la qualità non è un obiettivo generico, ma un impegno misurabile, attraverso il monitoraggio dei principali Indicatori EQAVET, in particolare:
• Tasso di partecipazione ai percorsi di formazione;
• Tasso di completamento dei corsi;
• Tasso di collocamento dei diplomati nel mercato del lavoro;
• Livello di soddisfazione di studenti e imprese;
• Investimento nella formazione dei formatori e nelle metodologie didattiche;
• Attenzione ai processi di validazione degli apprendimenti non formali e informali.
Questi dati permettono di capire, con evidenza, se stiamo garantendo la buona formazione che promettiamo.
VALUTAZIONE ESTERNA E TRASPARENZA
Per rafforzare ulteriormente il nostro sistema di qualità, collaboriamo con valutatori esterni (“Pari”), esperti della metodologia Peer Review EQAVET.
 .
.
La loro analisi indipendente ci permette di verificare:
• la coerenza del nostro lavoro;
• la validità delle metodologie;
• l'efficacia dei risultati;
• la capacità di miglioramento continuo.
Una formazione di qualità è quella che:
• apre opportunità concrete;
• offre competenze che valgono davvero;
• permette ai giovani di inserirsi nel lavoro con fiducia, preparazione e visione;
• si basa su un sistema trasparente di misurazione, valutazione e miglioramento.
La buona formazione, oggi più che mai, si può garantire solo unendo centralità della persona, connessione con il lavoro e assicurazione della qualità basata sugli Indicatori EQAVET.
Solo così la formazione diventa un investimento reale sul futuro!
Approfondimenti:
6.L'Assicurazione della Qualità nell'IFP.
5.L'Etica della formazione come responsabilità professionale.
3.La qualità della formazione inizia dal confronto.
2.La filiera della Formazione Professionale in Europa e in Italia.
1.Sei uno studente oppure un lavoratore? Scopri qual è il tuo livello di EQF.
 Eventi Formativi
Eventi Formativi

-

TECNICO DELLA PROGRAMMAZIONE
Napoli 22/04/2026
-

TonyBuzan Mind Mapping Practitioner for Business
Napoli 05/07/2018
-

IoT e criptovalute, la nuova frontiera del lavoro giovanile, partecipa al Webinar gratuito
27/04/2018
-
PRINCE2® 2017 Practitioner
Napoli 21/06/2018
-
PRINCE2® 2017 Foundation
Napoli 16/07/2018
-
GTD® I&I Sessions
Roma, Milano 01/01/2018
-

Automazione dell'ufficio con SharePoint
Roma 17/04/2017
-

Automazione dell'ufficio con SharePoint
Napoli 03/04/2017
-
Getting Things Done ® Mastering Workflow 1
Napoli 05/07/2018
-
Mind Mapping Practitioner for Students
Napoli 05/07/2018
 Offerte di Lavoro
Offerte di Lavoro
 Post più recenti
Post più recenti
-

Full Stack Developer
07/05/2026
-
1° MAGGIO: FESTA DEL LAVORO E DELLA FORMAZIONE
01/05/2026
-
Operatore Amministrativo Contabile
09/04/2026
-
Tecnico Programmatore: Il Profilo più richiesto dai giovani che frequentano la nostra Academy
17/03/2026
-
6.L'Assicurazione della Qualità nell'IFP
24/01/2026
-
Skill Factory 2025: Un anno di formazione tra "Innovazione (AI), Qualità (EQAVET) e Politiche Attive del Lavoro (PAR GOL)"
30/12/2025
-
10.Intelligenza Artificiale: cosa cambia nel mondo del lavoro
21/12/2025
-
5.L’etica della formazione come responsabilità professionale
13/12/2025
-
4.Buona Formazione: "Come assicurare la Qualità della Formazione"
06/12/2025
-
Corso gratuito di 60 ore per creare le competenze digitali fondamentali (DIGCOMP2.2)
25/09/2025