 Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy
Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy





Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy


-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-




 Scheda Azienda
Scheda Azienda Blog
Blog Eventi formazione
Eventi formazione Offerta formativa
Offerta formativa Offerte di lavoro
Offerte di lavoro Lavora con noi
Lavora con noi
 Richiedi informazioni
Richiedi informazioni
Skill Factory
Lista post > 2.Intelligenza Artificiale: i modelli linguistici di grandi dimensioni (LLM)
2.Intelligenza Artificiale: i modelli linguistici di grandi dimensioni (LLM)
![]() Gino Visciano |
Skill Factory - 11/10/2024 20:02:22 | in Home
Gino Visciano |
Skill Factory - 11/10/2024 20:02:22 | in Home
 Fino a qualche tempo fa le macchine potevano svolgere compiti solo se venivano programmate. Oggi il paradigma è cambiato, perché le macchine sono capaci di apprendere e risolvere i problemi da sole, per questo motivo parliamo di "Intelligenza Artificiale".
Fino a qualche tempo fa le macchine potevano svolgere compiti solo se venivano programmate. Oggi il paradigma è cambiato, perché le macchine sono capaci di apprendere e risolvere i problemi da sole, per questo motivo parliamo di "Intelligenza Artificiale".
Le macchine si sono evolute al punto che riescono a comprendere il linguaggio naturale (NLP - Natural Language Processing). Per uno come me che ha iniziato a programmare le macchine negli anni '80 con l'Assembler, un linguaggio artificiale mnemonico, molto simile al linguaggio delle macchine, fatto di lunghe sequenze di numeri 1 e numeri 0, vedere oggi macchine che eseguono comandi o rispondono a domande complesse elaborando il linguaggio naturale rappresenta un passo avanti notevole, impensabile fino a qualche anno fa.
Il settore dell'IA che si occupa dell'apprendimento delle macchine si chiama "Machine Learning". Gli algoritmi di ML permettono alle macchine di apprende grandi quantità di dati, proprio come fanno gli uomini quando studiano.
Un delle aree più avanzata del Machine Learning è quella del Deep Learning, che si occupa dell'apprendimento delle macchine attraverso algoritmi avanzati, anche detti algoritmi di apprendimento profondo, questi modelli sono così evoluti che si comportano come reti neurali artificiali.
Il risultato dei dati raccolti durante la fase di addestramento di una macchina attraverso algoritmi di tipo Deep Learning sono gli LLM (Large Language Model) o modelli linguistici di grandi dimensioni.
Potete immaginare un LLM come un computer super intelligente che ha letto tantissimi libri, articoli e pagine web, grazie a questo è capace di comprendere il linguaggio naturale, rispondere alle domande, tradurre testi in molte lingue, scrivere testi e generare immagini, musica e video.
Attenti a non fare l'errore di credere che gli LLM siano dei database in cui si trovano domande e risposte frequenti, come avviene per le FAQ (Frequently Asked Questions); essi contengono solo le informazioni per creare le risposte, che vengono generate ogni volta dall'inferenza.
COME FUNZIONA L'INFERENZA?
L'inferenza è il processo attraverso cui si utilizzano le conoscenze dell'LLM per rispondere alle domande o risolvere problemi. L'inferenza si basa su algoritmi e modelli matematici che permettono all'LLM di prendere decisioni più probabili.
L'LLM non dà mai una risposta con una certezza assoluta. Le sue risposte sono sempre basate sulla probabilità. Il modello sceglie sempre la sequenza di parole più probabile nel contesto dato. Più dati ha a disposizione, più accurate saranno le risposte, le previsioni o le soluzioni.
Le fasi del processo d'inferenza sono le seguenti:
1) Input: si fornisce all'LLM un input, sotto forma di domanda.
2) Elaborazione: l'LLM analizza l'input, cercando di capire il contesto, il significato e le intenzioni.
3) Generazione: l'LLM utilizza i modelli linguistici che ha appreso durante l'addestramento per generare una risposta o un testo che sia coerente con l'input e con le informazioni che ha a disposizione.
Gli LLM sono strumenti potenti, ma è importante evidenziarne subito i limiti:
- Non pensano come gli umani: gli LLM non capiscono veramente il significato delle parole, ma seguono delle regole che hanno imparato.
- Possono sbagliare: a volte gli LLM possono dare risposte sbagliate o senza senso, soprattutto se le domande sono molto complesse. In questo caso parliamo di allucinazioni.
- Dipendono dai dati: le risposte degli LLM vengono create in base ai dati con cui sono stati addestrati; quindi, potrebbero evidenziare dei pregiudizi che dipendono dal tipo d'informazioni acquisite durante l'apprendimento. Naturalmente questo fenomeno, chiamato BIAS, può creare delle implicazioni etiche.
COME VENGONO ADDESTRATI GLI LLM
L'addestramento degli LLM è un processo complesso, che richiede tempo e una notevole quantità di risorse.
L'addestramento può essere: supervisionato, non supervisionato e per rinforzo.

Nel caso degli LLM:
Addestramento supervisionato: utilizziamo enormi quantità di testo, dove ogni frase o paragrafo è etichettato con un'informazione specifica (es: traduzione, risposta a una domanda). Il modello impara a generare testo simile a quello di esempio.
Addestramento non supervisionato: forniamo al modello grandi quantità di testo senza etichette. Il modello impara a prevedere la parola successiva in una frase, a completare frasi o a tradurre testi, identificando le relazioni tra le parole e le frasi.
Apprendimento per rinforzo: il modello viene addestrato a svolgere un compito specifico (es: giocare a scacchi) e riceve un feedback positivo o negativo in base ai risultati ottenuti.
Il primo passo per addestrare un LLM è la raccolta dei dati che vengono puliti, formattati e pre-elaborati per rimuovere errori, incoerenze e informazioni non pertinenti.
I testi raccolti da internet, libri, articoli, codice e altre fonti, vengono divisi in unità più piccole chiamate token, che possono essere parole, sotto-parole o caratteri speciali.
A ogni token viene assegnato a un numero unico, creando una rappresentazione numerica del testo.
Gli LLM si basano su algoritmi avanzati o modelli, che si comportano come reti neurali artificiali, in particolare quelle chiamate "trasformatori", che sono particolarmente adatte a gestire sequenze di dati come il testo.
La potenza di un modello dipende dal numero di parametri che ha disposizione. I parametri sono numeri che vengono prodotti durante la fase di addestramento. Maggiore è il numero di parametri di un modello, migliori sono le capacità di fare previsioni o prendere decisioni. Il ruolo dei parametri, che si possono immaginare come nodi della rete neurale artificiale, è quello di mettere in relazione tra loro il maggior numero di neuroni in base ad una logica basata sul calcolo della probabilità della conoscenza.
Dovete immaginare i parametri o nodi come a delle piccole unità di calcolo (funzioni matematiche). Quando ricevono degli input (dati in ingresso), li elaborano secondo una certa funzione e producono un output (un risultato). Insieme, i nodi formano una rete complessa che permette all'algoritmo di apprendere e fare previsioni.

Tipi di nodi:
Nodi di input: sono i primi nodi della rete, quelli che ricevono i dati grezzi.
Nodi nascosti: si trovano negli strati intermedi della rete e svolgono la maggior parte del lavoro di elaborazione dei dati.
Nodi di output: sono gli ultimi nodi della rete, quelli che forniscono il risultato finale.
Come funzionano i nodi?
Ricezione degli input: ogni nodo riceve un segnale da altri nodi o dall'esterno della rete.
Calcolo: Il nodo applica una funzione matematica (funzione di attivazione) ai dati in ingresso, generando un risultato.
Trasmissione dell'output: il risultato viene trasmesso ai nodi successivi della rete.
L'organizzazione dei parametri di un modello, attraverso algoritmi di ottimizzazione, viene aggiornata continuamente in modo iterativo con l'obbiettivo di ridurre al minimo la differenza tra previsioni del modello e le risposte corrette. Per misura la differenza tra previsioni del modello e le risposte corrette, si usa una funzione matematica chiamata funzione di perdita.
L'addestramento richiede un'enorme potenza di calcolo, spesso utilizzando cluster di GPU o TPU.

Letteralmente, cluster, significa “computazione a grappolo”: un gruppo di computer collegati in rete tra loro che lavorano in parallelo utilizzando processori potentissimi e veloci specializzati nella gestione delle immagini come le GPU (Graphics Processing Unit) oppure le TPU (Tensor Processing Unit) unità di elaborazione progettate da Google specializzate nelle operazioni di Machine Learning. Sono ottimizzate per eseguire operazioni sui tensori: strutture dati multidimensionali fondamentali per le reti neurali artificiali.

Dopo l'addestramento iniziale, il modello può essere ulteriormente addestrato su dataset più piccoli e specifici per migliorare le sue prestazioni su compiti particolari, come la generazione di codice, la traduzione o la risposta a domande, questa operazione di chiama "Fine-tuning".
PRINCIPALI LLM A CONFRONTO
|
Anno |
Nome LLM |
Parametri |
Tipo rete neurale |
Scopo principale |
Licenza |
Azienda/Organizzazione |
|
2023 |
GPT-4 |
>100 miliardi |
Transformer |
Generazione di testo, comprensione, traduzione, ecc. |
Proprietario |
OpenAI |
|
2023 |
PaLM 2 |
Varianti |
Transformer |
Generazione di testo, comprensione, traduzione, coding |
Proprietario |
Google AI |
|
2023 |
LLaMA |
7B - 65B |
Transformer |
Ricerca, creazione di contenuti |
Non-commerciale |
Meta AI |
|
2022 |
T5 |
Varianti |
Transformer |
Molteplici compiti NLP |
Open-source |
Google AI |
|
2020 |
GPT-3 |
175 miliardi |
Transformer |
Generazione di testo |
Proprietario |
OpenAI |
|
2020 |
BART |
Varianti |
Transformer |
Generazione di testo, riassunto, traduzione |
Open-source |
Facebook AI Research |
|
2019 |
RoBERTa |
Varianti |
Transformer |
Comprensione del linguaggio naturale |
Open-source |
Facebook AI Research |
|
2018 |
BERT |
340 milioni |
Transformer |
Comprensione del linguaggio naturale |
Open-source |
Google AI |
COSA SONO I PROMPT?
I prompt sono lo strumento che ci permette di interagire con gli LLM e di sfruttarne al meglio le potenzialità. Sono il ponte tra le nostre richieste e la capacità dell'LLM di generare testi complessi e informativi. È come una chiave che ci permette di aprire le porte della creatività e dell'innovazione. Più siamo abili nel formulare i prompt, più saremo in grado di sfruttare tutto il potenziale di questi modelli linguistici.
La capacità di formulare prompt è così importante che in futuro, con la diffusione dell'Intelligenza Artificiale, la figura del creatore di prompt sarà sempre più richiesta. Il creatore di prompt non è semplicemente colui che fa domande, ma un vero e proprio ingegnere della comunicazione che, attraverso la formulazione di istruzioni precise e creative, è in grado di sfruttare al massimo le potenzialità degli LLM.
il creatore di prompt è una figura che, oltre alle sue competenze linguistiche e creative, si avvale di una serie di strumenti e tecniche per ottimizzare il processo di creazione dei prompt e ottenere i migliori risultati possibili dagli LLM.
Approfondirò sicuramente l'argomento dei creatori di prompt in uno dei miei prossimi articoli, perché è un argomento molto interessante.
CONCLUSIONI
Gli LLM sono sistemi informatici, chiamati modelli, che attraverso algoritmi di apprendimento profondo si addestrano su enormi quantità di dati.
Le informazioni raccolte vengono organizzate in uno spazio vettoriale e collegate tra loro attraverso l'uso di parametri, anche detti nodi, che utilizzano funzioni matematiche per creare una fitta rete di percorsi usati dall'inferenza per creare le risposte o le soluzioni più probabili alle domande o alle richieste formulate dai prompt.
Dopo l'addestramento gli LLM, possono essere ulteriormente specializzati attraverso una fase di fine tuning, che prevede l'apprendimento di un dataset di dati più dettagliato.
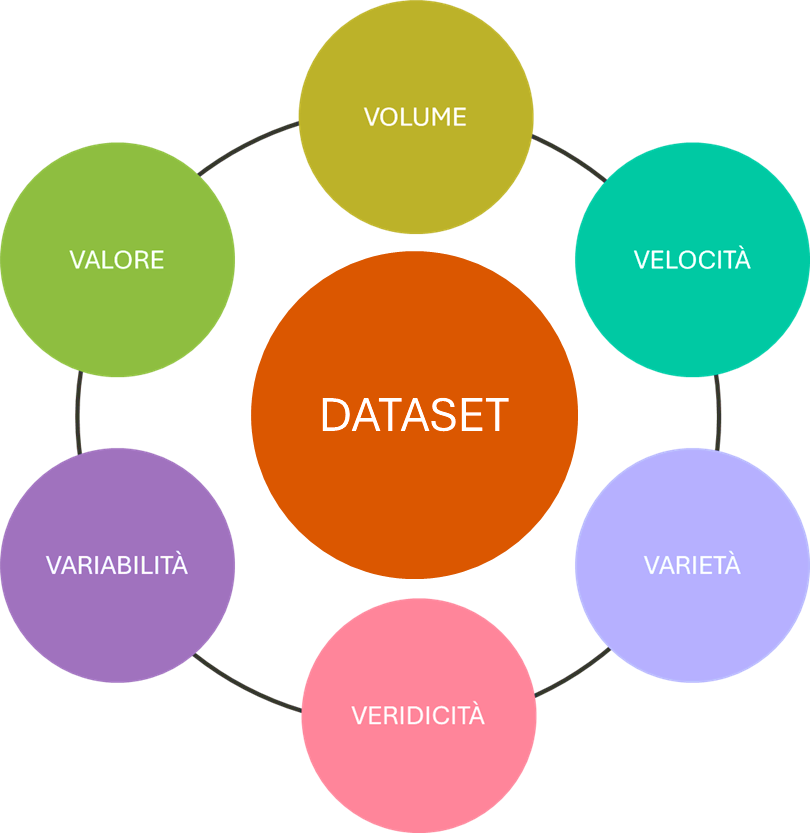
La qualità dei dati durante la fase di addestramento degli LLM è importante per evitare il problema dei pregiudizi o Bias. Un DATASET per essere di valore deve contenere una grande quantità di dati, sempre aggiornati velocemente, provenienti da fonti eterogenee e contesti differenti e le informazioni devono essere affidabili, utili e senza fake.
Gli LLM sono utilissimi nell'ambito scientifico, del lavoro, dell'educazione e dell'intrattenimento; i chatbot e assistenti virtuali sono solo la punta dell'iceberg.
Nel prossimo articolo vi parlerò di reti neurali artificiali, per capire che cosa sono e cosa ci permettono di fare.
1.Intelligenza Artificiale: se la conosci non la temi
3.Intelligenza Artificiale: le reti neurali artificiali
4.Intelligenza Artificiale: tipi di reti neurali artificiali
5.Intelligenza Artificiale: IA Generativa
6.Intelligenza Artificiale: modelli pre-addestrati di IA locali
7.Intelligenza Artificiale: come creare una chatbot per conversare con Llama3
8.Intelligenza Artificiale: come addestrare LLAMA3 attraverso un Fine-Tuning di tipo no coding
9.Intelligenza Artificiale: cosa dobbiamo sapere su ai act e deepfake
10.Intelligenza Artificiale: Cosa cambia nel mondo del lavoro
