 Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy
Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy





Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy


-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-
Tutte le categorie
Nell'era dello SMART LEARNING e di PYTHON i libri non si scrivono ma si sviluppano
![]() Gino Visciano |
Gino Visciano |
 Skill Factory - 17/04/2020 01:28:28 | in Home
Skill Factory - 17/04/2020 01:28:28 | in Home

Nell'era dello SMART LEARNING e di PYTHON i libri non si scrivono, ma si sviluppano, in questo modo chi studia, può sperimentare ed apprendere contemporaneamente; un libro con queste caratteristiche lo possiamo definire un Educational Gaming Book (EGB).
Con Python è molto semplice creare un EGB, basta usare la libreria Pygame che permette di creare giochi 2D. Le animazioni necessarie per sviluppare i laboratori simulati si possono realizzare con gli Sprite, immagini bidimensionali animate.
Per mostrarvi che cos'è un Educational Gaming Book (EGB) e quali sono le potenzialità, prendendo spunto dalla Giornata Mondiale dell'Acqua (World Water Day), ricorrenza istituita dalle Nazioni Unite nel 1992, che il 22 marzo di ogni anno ci ricorda che l’acqua è un bene raro che deve essere tutelato da tutte le nazioni del Mondo, ho sviluppato "H20".
"H2O" è un EGB che descrive tutte le caratteristiche dell'acqua, la sostanza formata da molecole di H2O, che attraverso il suo ciclo di vita garantisce la sopravvivenza di tutti gli esseri viventi del Pianeta.
L'obiettivo dell'EGB è quello di far conoscere ai giovani le proprietà dell'acqua, sotto molti aspetti uniche, per sensibilizzarli a salvaguardare un bene comune e raro, indispensabile per la vita.
Nell'EGB sono presenti diversi laboratori simulati, sviluppati con la tecnologia degli Sprite, che descrivono gli Stati fisici dell'acqua a diverse temperature ed alla pressione di 1 atm.
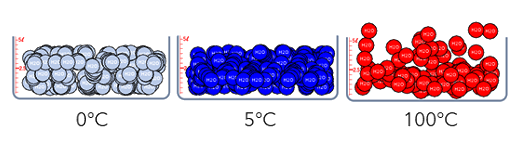
Molto interessanti, anche per la didattica scolastica, sono i laboratori simulati che descrivono i principali fenomeni meteorologici: pioggia, neve, rugiada e nebbia.
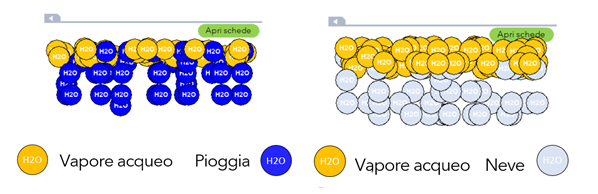
Consiglio l'Educational Gaming Book "H20" agli insegnati delle scuole secondarie di primo e secondo grado, perché può essere utlizzato sia in modalità asicrona, facendolo installare sui computer dgli studenti, sia può essere utilizzato in classe, attraverso l'uso di una LIM.
INDICE delle Schede/Laboratorio contenute nell'Educational Gaming Book "H20":
- 1 Che cos’è l’acqua
- 2 Numero e Peso Atomico
- 3 Peso atomico della molecola H2O
- 4 Il Sistema Internazionale (SI)
- 5,6 Che cos’è la Mole
- 7 La costante di Avogadro
- 8 Il Volume Molare dell’acqua H2O
- 9,10,11 Che cos’è la Temperatura
- 12,13 Che cos’è la Densità
- 14,15 Gli Stati fisici dell’acqua
- 16 Sublimazione e Brinamento
- 17,18 Che cos’è il Calore Latente
- 19 Il Ciclo di vita dell’acqua
- 20,21 Principali fenomeni meteorologici
- 22 Conclusioni
DOWNLOAD ED INSTALLAZIONE
Per utilizzare l'Educational Gaming Book "H20" serve un computer con almeno 4GB di RAM, un spazio libero sul disco di circa 60 MB e seguire le operazione seguenti:
1) Creare una cartella H2O
2) Fare il download dei file egbh2o.zip e risorseh2o.zip utilizzando i link seguenti:
A) Download egbh2o.zip
B) Download risorseh2o.zip
3) Copiare i file egbh2o.zip e risorseh2o.zip nella cartella H2O
3) Estrarre nella cartella H2O il contenuto dei file egbh2o.zip e risorseh2o.zip
4) Per lanciare "H20" cliccare sul file H2O.exe
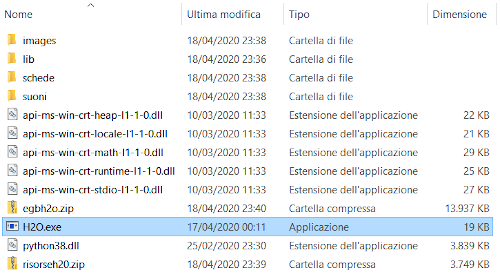
Dopo che avete completato l'installazione, potete cancellare i file zip, per recuperare spazio sul disco.
Quando eseguite l'EGB se Windows chiede l'autorizzazione per l'esecuzione dell'Applicazione, confermate.
Se non avete il mouse, potete usare i comandi della tastiera. Per ottenere l'elenco completo dei comandi della tastiera, consultate la guida usando i tasti Ctrl+h, con Ctrl+1 potete tornare alla prima scheda.
Buona sperimentazione!

Formazione Professionale e Coronavirus - Il nostro punto di vista
![]() Gino Visciano |
Skill Factory - 08/03/2020 13:58:59 | in Home
Gino Visciano |
Skill Factory - 08/03/2020 13:58:59 | in Home
![]() Come altri settori economici, anche il settore della Formazione Professionale risulta fortemente penalizzato dalle misure adottate dal Governo nel DPCM dell'8 marzo 2020, per contrastare e contenere il contagio del virus COVID-19.
Come altri settori economici, anche il settore della Formazione Professionale risulta fortemente penalizzato dalle misure adottate dal Governo nel DPCM dell'8 marzo 2020, per contrastare e contenere il contagio del virus COVID-19.
In realtà questa misura in Campania arriva in un momento in cui gli enti di formazione e le società impegnate nel settore delle politiche attive del lavoro, già da tempo stanno attraversando un momento di difficoltà a causa della lunga fase di stallo creata dai continui rinvii dei progetti e delle attività programmate per l'anno 2020.
Il nostro punto di vista è che il settore della Formazione Professionale non si deve fermare, perché oltre a garantire posti di lavoro, rappresenta il motore principale per lo sviluppo del nostro Territorio.
La Skill Factory nel 2019 ha creato 130 posti di lavoro nel settore dell'Information Technology e quest'anno si pone l'obiettivo di raddoppiare il numero di posti di lavoro creati nel 2019.
La Formazione è immune al Coronavirus, ma non può essere immunizzata dai limiti culturali di chi ha la responsabilità di rilanciare un settore strategico così importante come quello della "Formazione Professionale" e delle "Politiche Attive del lavoro".
Nonostante i progressi tecnologici e l'esperienza sviluppata nel settore della valorizzazione delle risorse umane, la formazione è intesa ancora come un insieme di documenti da firmare per mettersi in regola con gli aspetti burocratici dei progetti formativi.
Come la storia c'insegna, il momento negativo che stiamo vivendo, può rappresentare per il settore della Formazione un momento di rilancio tecnologico, economico, ma soprattutto culturale, un'opportunità per superare i limiti imposti della formazione TRADIZIONALE, basata molto sulla forma e poco sugli obiettivi programmati.
La Formazione per essere efficace, deve porre il "Discente" al centro del processo di formazione e garantire le seguenti caratteristiche:

Questo non significa semplicemente passare da un modello di formazione Frontale, aula con docente, ad un modello di formazione in Virtual Class, attraverso una piattaforma FAD, ma significa applicare un modello didattico intelligente ed innovativo, capace di garantire ai destinatari l'acquisizione delle competenze professionali richieste, anche attraverso l'uso corretto delle nuove tecnologie.
In conclusione ci auguriamo che chiunque abbia un ruolo istituzionale e decisionale nel settore della Formazione Professionale, faccia tutto il possibile per superare i vincoli burocratici che in questo momento bloccano gli enti di formazione e le società che operano nel settore delle politiche attive del lavoro, per permettere la ripresa delle attività programmate, attraverso l'uso di modalità didattiche differenti che gli consentano di operare nel rispetto delle misure adottate dal Governo nel DPCM dell'8 marzo 2020.
 Siamo disponibili in modo assolutamente gratuito, a supportare con il nostro know How tecnico/esperienziale, gli enti di formazione e le scuole che a causa del coronavirus sono stati costretti ad interrompere le attività didattiche, per permettere a tutti di riprendere al più presto possibile le attività di formazione attraverso la nostra piattaforma Skillbook.it, in modalità SMART.
Siamo disponibili in modo assolutamente gratuito, a supportare con il nostro know How tecnico/esperienziale, gli enti di formazione e le scuole che a causa del coronavirus sono stati costretti ad interrompere le attività didattiche, per permettere a tutti di riprendere al più presto possibile le attività di formazione attraverso la nostra piattaforma Skillbook.it, in modalità SMART.
Per contatti ed informazioni: sid@skillfactory.it.
Guida ai corsi della "Scuola di Innovazione Digitale" della Skill Factory
![]() Gino Visciano |
Skill Factory - 06/03/2020 23:01:59 | in Home
Gino Visciano |
Skill Factory - 06/03/2020 23:01:59 | in Home
Sulla piattafroma Skillbook.it è possibile consultare il catalogo dei corsi della "Scuola di Innovazione Digitale" della Skill Factory.
La scuola nasce con l'obiettivo di facilitare l'apprendimento delle Tecnologie Digitali atraverso una metodologia SMART, che permette anche a chi studia o lavora di acquisire le competenze informatiche per arricchire il proprio curriculum professionale.
La formazione SMART si differenzia da quella TRADIZIONALE perché è flessibile, sostenibile e pone al centro del processo di formazione principalmente gli obiettivi programmati.
In questo modello didattico il formatore diventa un Coach che, con il supporto di consulenti esperti nei diversi settori di specializzazione, ti aiuta a costruire step by step il tuo profilo professionale.
Grazie ai corsi del nostro catalogo, potrai acquisire le competenze che ti servono per specializzarti nei seguenti settori applicativi:

Per accedere all'elenco dei corsi organizzati per settore clicca qui.
Le LEZIONI TEORICHE, svolte dai Coach, pssono essere erogate sia in Presenza, presso la nostra sede di Napoli, sia in Virtual Class, attraverso la piattaforma Skillbook.it.
I LABORATORI PRATICI sono svolti in modalità SMART Working assistita, supportati a distanza dal Coach e dagli esperti del settore di specializzazione.
Per permettere a tutti di seguire le LEZIONI TEORICHE, sono disponibili diverse fasce orarie, come mostra la tabella seguente:

La propedeuticità dei corsi è indicata nelle schede tecniche, il colore delle icone associate ai corsi indica il livello di accesso richiesto:
Percorsi professionali disponibili
1.Sviluppatore di Siti e Portali Web

Front-End Developer - PHP Web Developer
2.Sviluppatore Angular

Front-End Developer - Angular Developer
3.Sviluppatore Java

Front-End Developer - Java Developer - Java Web Developer
4.Sviluppatore C#

Front-End Developer - C# Developer - C# Web Developer
5.Sviluppatore di App Mobile (ANDROID)

Front-End Developer - Java Developer - Java Android Developer
6.Sviluppatore C# di Videogame (UNITY)

7.Sviluppatore Python

Front-End Developer - Python Developer - Python Web Developer
8.Sviluppatore Python di Videogame 2D

Python Developer - Python Game Developer 2D
9.Sviluppatore Hadoop ETL (BIG DATA)

Java Developer - Python Developer - Hadoop ETL Developer
- Corsi a numero chiuso, per informazioni e contatti: sid@skillfactory.it
Formazione SMART a Napoli - La Skill Factory apre la "Scuola d'Innovazione Digitale"
![]() Gino Visciano |
Skill Factory - 13/02/2020 23:31:14 | in Home
Gino Visciano |
Skill Factory - 13/02/2020 23:31:14 | in Home

A marzo iniziano a Napoli le attività didattiche della nuova "Scuola d'innovazione digitale" della Skill Factory, un progetto pilota di tipo SMART, che nasce con l'obiettivo di favorire l'acquisizione delle employability skills (abilità per l'impiego) richieste nel mondo delle aziende e dell'industria 4.0, per far fronte ai cambiamenti prodotti dalla trasformazione digitale.
L'idea di applicare un modello di apprendimento diverso, basato sulla "Formazione SMART", è importante per rispondere all'esigenza di un'utenza che ha sempre più bisogno di formazione, ma ha sempre meno tempo per formarsi.
La formazione per essere SMART deve avere le seguenti caratteristiche:
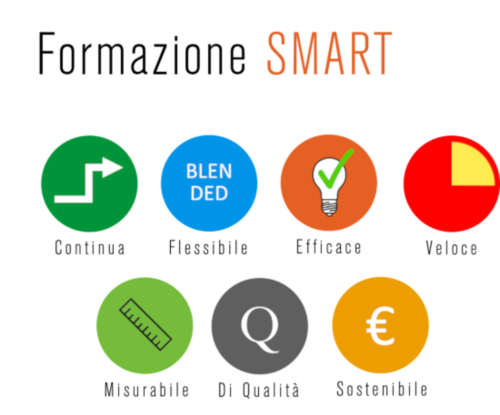
Oggi la rivoluzione digitale impone a tutti coloro che studiano o lavorano di acquisire le Soft Skills, le ICT literacy Skills e le Hard Skills indispensabili per governare la crescente diffusione delle tecnologie informatiche e delle macchine sempre più usate nell'era digitale.

L'insegnamento delle competenze digitali è fondamentale anche per le scuole superiori, per fornire agli studenti le competenze trasversali necessarie per entrare nel mondo del lavoro.
Il nuovo modello SMART , proposto dalla Skill Factory, rappresenta un valido supporto anche per gli Education Partner che condividono con l'azienda progetti PCTO.

Con la "Scuola d'innovazione digitale" collaborano Formatori ed Esperti che lavorano nel settore dell'Information Technology e dell'industria 4.0, con competenze avanzate nei seguenti ambiti applicativi:
- Alfabetizzazione Digitale
- Office Automation
- Digital MarKeting
- Videomaking
- Computer Grafica
- E-Commerce
- CRM/ERP
- Sistemi, Reti e Sicurezza
- Cloud computing
- Cyber Security
- Sviluppo Applicativo/Web/Mobile
- Domotica
- Internet of Things
- Big Data
- Machine Learning
- CAD/CAM
- Robotica

Tutti i Corsi ed i Seminari prevedono sia attività didattiche in Presenza, sia in FAD (Virtual Class e Self-Study).

Sono disponibili le seguenti fasce orarie:
Tutto il processo di Assessment, di Formazione e di Certificazione delle competenze è gestito attraverso la piattaforma Skillbook, la community learning che favorisce l'incontro tra domanda ed offerta di formazione e lavoro.
Se sei già registrato su www.skillbook.it, per richiedere infomazioni clicca qui.

Impariamo Python creando il "Calendario Perpetuo" - Lezione 7
![]() Gino Visciano |
Skill Factory - 30/01/2020 23:29:56 | in Tutorials
Gino Visciano |
Skill Factory - 30/01/2020 23:29:56 | in Tutorials
In questa lezione creiamo un Calendario perpetuo, per ricavare il giorno della settimana di qualsiasi data.
L'algoritmo per creare un calendario perpetuo richiede le seguenti informazioni:
1) Codice dell'anno
2) Codice del mese
3) Numero del giorno della settimana
4) Se l'anno è Bisestile oppure no
Come calcolare il Codice dell'anno
Per calcolare Il codice dell'anno bisogna prima ottenere le due cifre a destra dell'anno scelto, ad esempio per l'anno 2019 serve il 19, che per comodità indichiamo con aa.
In Python per ottenere aa possiamo usare il comando seguente:
La funzione str(...) converte la variabile intera anno in stringa, mentre con [2:] indichiamo a Python di eliminare dalla stringa i due caratteri a sinistra. Infine i due caratteri che restano vengono di nuovo convertiti in intero ed assgnati alla variabile aa.
Successivamente dobbiamo calcolare il codice_anno_intermedio che è dato dalla formula:
codice_anno_intermedio=aa+int(aa/4)
Infine per ottenere il codice_anno occorre sottrarre al codice_anno_intermedio il suo multiplo di 7 più piccolo, come mostra la formula seguente:
codice_anno=codice_anno_intermedio-int(codice_anno_intermedio/7)*7.
Facciamo un esempio, calcoliamo il codice anno del 2019:
1) aa=19
2) codice_anno_intermendio=aa+int(aa/4)=19+4=23
3) codice_anno=codice_anno_intermedio-int(codice_anno_intermedio/7)*7=23-21=2
Come ottenere il Codice del mese
Il codice del mese è un valore intero difficile da calcolare, fortunatmente c'è già chi l'ha fatto per noi, quindi basta guardare semplicemente i risultati ottenuti:
1) gennaio = 6 se l'anno è bisestile 5
2) febbraio = 2 se l'anno è bisestile 1
3) marzo = 2
4) aprile = 5
5) maggio = 0
6) giuugno = 3
7) luglio = 5
8) agosto = 1
9) settembre = 4
10) ottobre = 6
11) novembre = 2
12) dicembre = 4
Come potete vedere per ottenere il codice del mese è importante sapere se l'anno di riferimento è bisestile.
Come verificare se un anno è bisestile
def verificaBisestile(anno):
bisestile=False
if anno%100==0:
if anno%400==0:
bisestile=True
elif anno%4==0:
bisestile=True
return bisestile
In questa funzione l'opertore % (modulo) permette di capire se l'anno è divisibile prima per 100 e poi per 400 oppure se è divisibile direttamente per 4.
1) Lunedì = 1
2) Martedì = 2
3) Meercoledì = 3
4) Giovedì = 4
5) Venerdì = 5
6) Sabato = 6
7) Domenica = 7 oppure 0
La formula per calcolare il numero del giorno è la seguente:
Numero giorno = (Codice anno + Codice Mese + Progressivo giorno del mese)%7
Facciamo un esempio, con un anno non bisestile ed uno bisestile:
Esempio 1
Il 18 marzo 2019, corrisponde ad un lunedì, per verificare calcolare il numero del giorno:
1) aa=19
2) codice_anno_intermendio=aa+int(aa/4)=19+4=23
3) codice_anno=codice_anno_intermedio-int(codice_anno_intermedio/7)*7=23-21=2
4) codice_mese=2
5) Numero giorno = (Codice anno + Codice Mese + Progressivo giorno del mese)%7 = (2+2+18)%7=1
6) Il numero giorno 1 corrisponde a lunedì
Esempio 2
Il 10 gennaio 2020, corrisponde ad un venerdì, per verificare calcolare il numero del giorno:
1) aa=20
2) codice_anno_intermendio=aa+int(aa/4)=20+5=25
3) codice_anno=codice_anno_intermedio-int(codice_anno_intermedio/7)*7=25-21=4
4) codice_mese=5 perché l'anno 2020 è bisestile
5) Numero giorno = (Codice anno + Codice Mese + Progressivo giorno del mese)%7 = (4+5+10)%7=5
6) Il numero giorno 5 corrisponde a venerdi
In Python per ottenere il numero del giorno della settimana di una data qualunque del calendario, possiamo usare la funzione seguente:
aa=int(str(aaaa)[2:])
codici_mesi=[6,2,2,5,0,3,5,1,4,6,2,4]
if verificaBisestile(aaaa)==True:
codici_mesi=[5,1,2,5,0,3,5,1,4,6,2,4]
codice_anno_intermedio=(aa+int(aa/4))
codice_anno=codice_anno_intermedio-int(codice_anno_intermedio/7)*7
giorno=(codice_anno+codici_mesi[mm-1]+gg)%7
return giorno
Analisi del codice Python
# Calendario perpetuo
import tkinter as tk # Classe che permette di creare GUI
from PIL import Image, ImageTk # Classi per gestire immagini
import time # Classe che permette di gestire il tempo
# Funzione che calcola il numero del giorno della settimana
def giornoSettimana(gg,mm,aaaa):
aa=int(str(aaaa)[2:])
codici_mesi=[6,2,2,5,0,3,5,1,4,6,2,4]
if verificaBisestile(aaaa)==True:
codici_mesi=[5,1,2,5,0,3,5,1,4,6,2,4]
codice_anno_intermedio=(aa+int(aa/4))
codice_anno=codice_anno_intermedio-int(codice_anno_intermedio/7)*7
giorno=(codice_anno+codici_mesi[mm-1]+gg)%7
return giorno
# Funzione che stampa i mesi dell'anno scelto
def stampaGiorni(mm,aaaa):
mesi=["Gennaio", "Febbraio", "Marzo", "Aprile","Maggio","Giugno","Luglio","Agosto","Settembre","Ottobre","Novembre","Dicembre"]
giorni=[31, 28, 31, 30,31,30,31,31,30,31,30,31]
if mm==2:
if verificaBisestile(aaaa)==True:
giorni[1]=29 # Imposta il mese di febbraio a 29 giorni se l'anno è bisestile
conta=0
titolo=mesi[mm-1]+" "+str(aaaa)
centra=" "[:10-int(len(titolo)/2)]
T2.insert(tk.END, '\n'+centra+titolo+'\n')
T2.insert(tk.END, " Lu Ma Me Gi Ve Sa Do\n")
gg_settimana=giornoSettimana(1,mm,aaaa)
if gg_settimana==0:
gg_settimana=7
for i in range(1,gg_settimana):
T2.insert(tk.END, " ")
conta=gg_settimana-1
for gg in range(1,giorni[mm-1]+1):
giorno=" "[:(3-len(str(gg)))]+str(gg)
T2.insert(tk.END, giorno)
conta=conta+1
if conta==7:
T2.insert(tk.END,'\n')
conta=0
T2.insert(tk.END,'\n')
T2.insert(tk.END,"---------------------\n")
# Funzione che verifica se l'anno è bisestile
def verificaBisestile(aaaa):
bisestile=False
if aaaa%100==0:
if aaaa%400==0:
bisestile=True
elif aaaa%4==0:
bisestile=True
return bisestile
# Funzione che imposta l'anno precedente e lo visualizza
def anno_precedente():
global anno
anno=anno-1
label_anno.config(text=anno)
main()
# Funzione che imposta l'anno successivo e lo visualizza
def anno_successivo():
global anno
anno=anno+1
label_anno.config(text=anno)
main()
# Funzione che crea i Frame in cui visualizzare i mesi dell'anno
def main():
global T2
F=[]
offset=0 # Permette di stampare 3 mesi in ogni Frame
for f in range(0,4):
F.append(tk.Frame(Frame_body)) # Il Frame_body contiene 4 Frame ciascuno con 3 mesi
F[f].grid(column = f, row = 0)
for f in range(0,4):
T2=tk.Text(F[f], height=29, width=25,font=("Courier", 12)) # Imposta lo stile del testo per stampare i mesi dell'anno
T2.pack(side=tk.LEFT, fill=tk.Y)
for mm in range(1+offset,4+offset):
stampaGiorni(mm,anno)
offset=offset+3 # Inizio programma
root = tk.Tk()
root.wm_title('CALENDARIO PERPETUO')
root.resizable(False, False)
icona = ImageTk.PhotoImage(Image.open("icona_cal.ico")) # Carica l'immagine dell'icona visualizzata in alto a sinistra della finestra del calendario
root.tk.call("wm", "iconphoto", root._w, icona)
Frame_top=tk.Frame(root)
Frame_top.pack(side="top", fill="both", expand = True) # Associa il Frame_top alla finestra root e lo espande in tutto lo spazio disponibile
# Pulsante freccia a sinistra usato per visualizzare l'anno precedente
freccia_sx=tk.Button(Frame_top,text="<", bd=1,command=anno_precedente, bg="blue",fg="white",font=("courier", 28))
freccia_sx.pack(side="left")
t = time.localtime()
anno=t.tm_year
label_anno = tk.Label(Frame_top, text=anno, bg="blue", fg="white",font=("Courier", 38))
label_anno.pack(side="left",fill="both",expand=True)
# Pulsante freccia a destra usato per visualizzare l'anno successivo
freccia_dx=tk.Button(Frame_top,text=">", bd=1, command=anno_successivo, bg="blue",fg="white",font=("courier", 28))
freccia_dx.pack(side="left")
Frame_body.pack()
w, h = root.winfo_screenwidth(), root.winfo_screenheight()
Frame_bottom=tk.Frame(root)
Frame_bottom.pack()
logo=ImageTk.PhotoImage(Image.open('logo_sf.png'))
label_logo=tk.Label(Frame_bottom, image=logo)
label_powered_sf=tk.Label(Frame_bottom, text="2020 - Powered by Skill Factory",font=("times", 14,'italic'))
label_logo.pack(side="left")
label_powered_sf.pack(side="left",fill="both",expand=True)
main()
tk.mainloop()
Questa lezione è sicuramente molto interessante perché oltre a permettere di acquisire nuove conoscenze ed abilità sull'utilizzo del linguaggio Python, permette anche di conoscere le caratteristiche fondamentali del calendario Gregoriano, come ad esempio la durata effettiva di un anno astronomico ed il meccanismo dell'anno bisestile per correggere il ritardo che si accumula ogni quattro anni.
L'applicazione può essere compilata per ottenere un eseguibile che vi permetterà di usare il calendario perpetuo senza dover usare l'interprete Python.
Per compilare lo script Python dovete installare il tool pyinstaller, con il comando:
pip install pyinstaller
Per compilare lo script dovete usare il comando:
pyinstaller calendario.py --noconsole
Dopo la compilazione travate tutto quello che vi serve nella cartella \dist\calendario.
Prima di lanciare il file eseguibile calendario.exe, dovete caricare nella cartella \dist\calendario tutte le immagini.
Arrivederci alla prossima lezione!
Per scaricare le risorse di questa lezione clicca sul link seguente:risorse_lezione_07

EDUCATIONAL GAMING BOOK (EGB) "H2O"
 Nell'era dello SMART LEARNING e di PYTHON i libri non si scrivono, ma si sviluppano, in questo modo chi studia, può sperimentare ed apprendere contemporaneamente; un libro con queste caratteristiche lo possiamo definire un Educational Gaming Book (EGB).
Nell'era dello SMART LEARNING e di PYTHON i libri non si scrivono, ma si sviluppano, in questo modo chi studia, può sperimentare ed apprendere contemporaneamente; un libro con queste caratteristiche lo possiamo definire un Educational Gaming Book (EGB).
"H2O" è un EGB che descrive tutte le caratteristiche dell'acqua, la sostanza formata da molecole di H2O, che attraverso il suo ciclo di vita garantisce la sopravvivenza di tutti gli esseri viventi del Pianeta.
L'obiettivo dell'EGB è quello di far conoscere ai giovani le proprietà dell'acqua, sotto molti aspetti uniche, per sensibilizzarli a salvaguardare un bene comune e raro, indispensabile per la vita.
Per il DOWNLOAD di "H2O" clicca qui.
 Eventi Formativi
Eventi Formativi

-

TECNICO DELLA PROGRAMMAZIONE
Napoli 22/04/2026
-

TonyBuzan Mind Mapping Practitioner for Business
Napoli 05/07/2018
-

IoT e criptovalute, la nuova frontiera del lavoro giovanile, partecipa al Webinar gratuito
27/04/2018
-
PRINCE2® 2017 Practitioner
Napoli 21/06/2018
-
PRINCE2® 2017 Foundation
Napoli 16/07/2018
-
GTD® I&I Sessions
Roma, Milano 01/01/2018
-

Automazione dell'ufficio con SharePoint
Roma 17/04/2017
-

Automazione dell'ufficio con SharePoint
Napoli 03/04/2017
-
Getting Things Done ® Mastering Workflow 1
Napoli 05/07/2018
-
Mind Mapping Practitioner for Students
Napoli 05/07/2018
 Offerte di Lavoro
Offerte di Lavoro
 Post più recenti
Post più recenti
-

Full Stack Developer
07/05/2026
-
1° MAGGIO: FESTA DEL LAVORO E DELLA FORMAZIONE
01/05/2026
-
Operatore Amministrativo Contabile
09/04/2026
-
Tecnico Programmatore: Il Profilo più richiesto dai giovani che frequentano la nostra Academy
17/03/2026
-
6.L'Assicurazione della Qualità nell'IFP
24/01/2026
-
Skill Factory 2025: Un anno di formazione tra "Innovazione (AI), Qualità (EQAVET) e Politiche Attive del Lavoro (PAR GOL)"
30/12/2025
-
10.Intelligenza Artificiale: cosa cambia nel mondo del lavoro
21/12/2025
-
5.L’etica della formazione come responsabilità professionale
13/12/2025
-
4.Buona Formazione: "Come assicurare la Qualità della Formazione"
06/12/2025
-
Corso gratuito di 60 ore per creare le competenze digitali fondamentali (DIGCOMP2.2)
25/09/2025