





-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-





 Scheda Azienda
Scheda Azienda Eventi formazione
Eventi formazione Offerta formativa
Offerta formativa Lavora con noi
Lavora con noi
 Richiedi informazioni
Richiedi informazioni
Skill Factory
Categoria: Home
9.Intelligenza Artificiale: cosa dobbiamo sapere su AI Act e deepfake
![]() Gino Visciano |
Skill Factory - 19/09/2025 11:23:20 | in Home
Gino Visciano |
Skill Factory - 19/09/2025 11:23:20 | in Home
L’intelligenza artificiale (IA) ormai fa parte della nostra realtà quotidiana, per questo motivo è fondamentale conoscere le nuove regole europee e italiane che ne disciplinano lo l’uso sia nelle aziende, sia nelle scuole. Nel seguito approfondiremo l’AI Act, la normativa europea sull’IA, le specifiche leggi italiane sui deepfake e come queste norme si differenziano dal GDPR.

CHE COS’È L’AI ACT
L’AI Act è la legge europea che regola come creare, vendere e usare i sistemi di intelligenza artificiale. È stata adottata per garantire un uso sicuro, trasparente ed etico delle tecnologie IA, garantendo salute, sicurezza e diritti delle persone.
La legge distingue i sistemi IA in quattro categorie in base al rischio che possono comportare:
1. Sistemi vietati perché troppo pericolosi: Questi sono sistemi che rappresentano un rischio così elevato per la sicurezza, la privacy o i diritti umani da essere completamente proibiti. Ad esempio, tecnologie per la sorveglianza di massa senza autorizzazione o software che manipolano il comportamento delle persone in modo coercitivo rientrano in questa categoria.
2. Sistemi ad alto rischio che richiedono controlli rigorosi: Sono sistemi che, se usati in modo errato o male intenzionato, possono causare danni significativi a persone o proprietà. Per questo motivo devono essere sottoposti a procedure di verifica, test approfonditi e trasparenza nella loro implementazione. Un esempio tipico sono i sistemi di riconoscimento facciale usati per la sicurezza pubblica o le tecnologie che supportano decisioni in ambito sanitario.
3. Sistemi che devono solo fornire informazioni chiare (es. chatbot): Questi sistemi non presentano un alto rischio, ma devono assicurarsi di comunicare in modo trasparente e comprensibile all’utente, indicando ad esempio che si tratta di un’intelligenza artificiale e non di una persona. Un esempio è un chatbot che risponde a domande generali, dove è importante evitare fraintendimenti o aspettative errate.
4. Sistemi con rischi bassi o minimi per cui non servono particolari limitazioni: Sono sistemi che comportano pochi o nulla rischi per l’utente e la società, e quindi non richiedono regole o controlli specifici. Un esempio può essere un algoritmo che suggerisce ricette di cucina o che consiglia playlist musicali, che influiscono solo marginalmente sulle decisioni delle persone.

L’AI Act mira a creare un equilibrio tra la tutela della sicurezza, dei diritti fondamentali e della privacy delle persone e la promozione dell’innovazione tecnologica nel campo dell’intelligenza artificiale. Da un lato, introduce regole chiare e vincolanti per prevenire abusi, come l’uso di sistemi per sorveglianza invasiva o discriminazione automatizzata, tutelando così i cittadini da potenziali rischi e danni. Dall’altro, stabilisce criteri proporzionati che permettono alle aziende e ai ricercatori di sviluppare nuove applicazioni AI in modo responsabile, senza soffocare la crescita tecnologica. Questo bilanciamento è fondamentale per garantire che l’intelligenza artificiale possa offrire benefici concreti alla società mantenendo un controllo adeguato sui pericoli che potrebbe comportare.
QUALI SONO LE SANZIONI PER CHI NON RISPETTA AI ACT?
Le sanzioni per chi non rispetta l'AI Act sono severe e variano in base alla gravità della violazione. Per le infrazioni più gravi, come l'uso di intelligenza artificiale manipolativa o pratiche vietate (es. sorveglianza biometrica illegale), le multe possono arrivare fino a 35 milioni di euro o al 7% del fatturato mondiale annuo dell'azienda, scegliendo la cifra maggiore. Per la non conformità relativa ai sistemi ad alto rischio, le sanzioni possono raggiungere i 15 milioni di euro o il 3% del fatturato globale. Infine, per la fornitura di informazioni false, incomplete o fuorvianti agli organismi di controllo, le multe possono essere fino a 7,5 milioni di euro o l'1% del fatturato mondiale.
Le PMI e le startup godono di un trattamento proporzionato con sanzioni ridotte rispetto alle grandi imprese, per tutelare l'innovazione senza penalizzare eccessivamente le realtà più piccole. Le sanzioni sono stabilite per garantire il rispetto delle regole e la sicurezza nell'uso dell'intelligenza artificiale, oltre a prevenire abusi e rischi per persone e società. Le autorità nazionali e un organismo europeo dedicato sorvegliano l'applicazione del regolamento e possono intervenire con queste misure punitive in caso di inosservanza.
DIFFERENZE CON ALTRE NORMATIVE INTERNAZIONALI
Mentre in Europa c’è un regolamento unico e uniforme per tutti i Paesi membri, in Paesi come gli Stati Uniti le regole sono più frammentate e spesso basate sull’autoregolamentazione delle aziende.
L’UE punta a un approccio centrale e rigoroso, con un focus forte sull’etica, la tutela dei diritti e la trasparenza, diventando un modello per il resto del mondo.
Vantaggi di un regolamento unico e uniforme in Europa:
• Assicura coerenza normativa in tutti i Paesi membri, semplificando per aziende e cittadini la comprensione e l’applicazione delle regole;
• Rende più efficace la protezione dei diritti fondamentali, della privacy e dei principi etici, favorendo sistemi AI trasparenti e sicuri;
• Stimola la fiducia degli utenti nelle tecnologie AI, fondamentale per un loro utilizzo responsabile e consapevole;
• Posiziona l’Europa come riferimento globale per normative AI etiche e rigorose;
Esempio: Un’impresa sa che può sviluppare un sistema AI rispettando regole valide in tutta l’UE, facilitando l’accesso al mercato europeo.
Svantaggi di questo approccio:
• Le norme rigide possono rallentare il ritmo dell’innovazione e aumentare i costi di conformità, penalizzando soprattutto PMI e startup.
• Concorrenza più forte da Paesi con regolamentazioni più flessibili, come gli Stati Uniti, dove è possibile muoversi con maggior agilità.
• Complessità e risorse necessarie per l’applicazione e il monitoraggio del regolamento possono limitare l’efficacia e creare incertezze.
Esempio: una startup europea può rinunciare a sviluppare o lanciare prodotti AI per i costi e i tempi di adeguamento normativo, a vantaggio di competitor americani più agili.
L’Unione Europea con l’AI Act cerca di bilanciare protezione e innovazione, promuovendo un modello responsabile e affidabile, ma deve anche affrontare la sfida di non soffocare lo sviluppo tecnologico nel contesto competitivo globale.
DEEPFAKE E NORMATIVA ITALIANA
I deepfake sono contenuti audio o video manipolati dall’IA che possono essere usati per ingannare le persone. L’AI Act richiede che questi contenuti siano sempre chiaramente etichettati come artificiali.

L’Italia ha fatto un passo in più approvando nel 2025 una legge che rende reato la creazione e la diffusione di deepfake ingannevoli, con pene che vanno da 1 a 5 anni di reclusione. Questa normativa nasce dall’urgenza di proteggere la reputazione e la privacy delle persone, contrastando l’uso illecito di tecnologie capaci di manipolare immagini e video in modo tale da ingannare l’opinione pubblica o danneggiare individui specifici. La legge italiana si inserisce in un contesto di crescente preoccupazione per i deepfake che possono alimentare disinformazione, frodi, diffamazione e violenza.
Oltre alla punizione penale, la legge prevede anche principi di rigorosa trasparenza: chi utilizza questi sistemi deve garantire che i contenuti creati siano identificabili come artificiali e non reali, in modo da evitare equivoci e danni a terzi. Questo approccio mira a rafforzare la fiducia nell’informazione e a tutelare i diritti fondamentali, come la dignità e la sicurezza personale.
L’implementazione della legge è sostenuta da un apparato di governance che coinvolge l’Agenzia per la Cybersicurezza Nazionale e l’Agenzia per l’Italia Digitale, chiamate a svolgere compiti di controllo, vigilanza e coordinamento. La normativa italiana amplia inoltre l’attenzione alla tutela del diritto d’autore, proteggendo le opere generate con l’ausilio dell’intelligenza artificiale, per salvaguardare la creatività umana da usi impropri o fraudolenti.
Questo quadro legislativo rappresenta un esempio innovativo a livello mondiale di come normare comportamenti rischiosi legati all’intelligenza artificiale, combinando azioni penali con misure di trasparenza e prevenzione, al fine di garantire sicurezza, rispetto e responsabilità nell’uso delle nuove tecnologie.
COME RICONOSCERE I DEEPFAKE
Per difendersi efficacemente, oltre alla legge, è importante sviluppare un atteggiamento critico e una buona educazione digitale, soprattutto nelle aziende e nelle scuole.
Conoscere la realtà e i meccanismi dei deepfake aiuta non solo a difendersi ma anche a capire meglio il valore dell’informazione vera e della responsabilità nell’uso dell’intelligenza artificiale.
Il termine deepfake deriva dall’unione di “deep learning” (una tecnica avanzata di intelligenza artificiale) e “fake” (falso). Indica contenuti multimediali, come video, audio o immagini, manipolati digitalmente per far apparire qualcosa o qualcuno in modo diverso dalla realtà. Per esempio, un video deepfake può mostrare una persona mentre dice o fa cose che in realtà non ha mai detto o fatto.
I deepfake sono diventati più sofisticati e difficili da riconoscere, ma è importante imparare a difendersi per non cadere vittime di disinformazione o truffe.

Ecco alcuni suggerimenti per riconoscerli:
• Osserva attentamente i dettagli: immagini o video deepfake spesso presentano imperfezioni come movimenti innaturali, sfasamenti del labiale, luci o ombre incoerenti.
• Controlla la voce: audio manipolati possono avere tonalità inconsuete, pause strane o suoni metallici.
• Verifica la fonte: un video o immagine diffuso da fonti poco affidabili o anonime richiede sospetto.
• Usa strumenti di verifica: esistono software e servizi online che analizzano i file per rilevare possibili alterazioni.
• Fai attenzione ai contenuti sensazionalistici: spesso deepfake vengono usati per diffondere notizie false destinate a suscitare reazioni forti.
DIFFERENZE TRA AI ACT, LEGGE DEEPFAKE E GDPR
L’AI Act regola l’uso dell’IA su larga scala, mentre il DDL italiano si concentra sul fenomeno specifico dei deepfake, stabilendo reati e pene.
Il GDPR, invece, è la normativa sulla protezione dei dati personali. Essa si applica anche ai dati usati o generati dall’IA o dai deepfake, imponendo regole su sicurezza, consenso e trasparenza.
APPLICAZIONE E FORMAZIONE NELLE AZIENDE
L’AI Act e le leggi italiane sui deepfake rappresentano una risposta necessaria per usare l’intelligenza artificiale rispettando la sicurezza, la privacy e i diritti delle persone.
Per aziende e scuole, conformarsi a queste normative è una sfida ma anche un’opportunità per costruire fiducia, innovare responsabilmente e prepararsi a un futuro digitale più sicuro.
Formazione, trasparenza e governance sono quindi le chiavi per affrontare con successo il futuro dell’intelligenza artificiale.

Per le aziende rispettare queste norme significa:
• organizzare una governance chiara e responsabile dell’IA;
• formare i dipendenti sull’uso etico e sicuro delle tecnologie;
• assicurare trasparenza e controllo sui sistemi IA;
• rispettare la privacy e proteggere i dati;
• prepararsi a eventuali controlli delle autorità competenti.
Nelle scuole è fondamentale:
• educare studenti e personale a riconoscere contenuti falsi e manipolati;
• integrare l’IA in modo responsabile nella didattica;
• formare insegnanti su tecnologia, etica e regole;
• sviluppare nei giovani un approccio critico e digitale sicuro;
• collaborare con esperti e istituzioni per un aggiornamento continuo.
CONCLUSIONI
L’AI Act e la recente normativa italiana sui deepfake rappresentano tappe fondamentali per assicurare che l’intelligenza artificiale venga utilizzata in modo responsabile, sicuro e rispettoso dei diritti fondamentali.
Queste norme non devono essere viste solo come vincoli legali, ma anche come opportunità per costruire fiducia, favorire l’innovazione responsabile e incrementare la sicurezza di cittadini e imprese.
Per le aziende e le scuole adeguarsi a queste regolamentazioni significa dotarsi di processi di governance efficaci e promuovere una formazione continua e capillare, che consenta a tutti gli attori coinvolti di conoscere rischi, obblighi e potenzialità dell’IA.
In particolare, la formazione e l’educazione digitale nelle scuole sono strumenti imprescindibili per formare cittadini consapevoli e critici, in grado di interagire in modo etico con le nuove tecnologie.
Affrontare con successo queste sfide normative significa prepararsi a un futuro dove IA, etica e diritti umani convivono, ponendo le basi per una società digitale inclusiva e sostenibile.
Infine, la conformità alle regole europee e nazionali può diventare un elemento distintivo e un vantaggio competitivo per chi saprà integrare tecnologia, sicurezza e responsabilità.
Nel prossimo articolo parleremo di come cambierà il mondo del lavoro con l'intelligenza artificiale
1.Intelligenza Artificiale: se la conosci non la temi
2.Intelligenza Artificiale: i modelli linguistici di grandi dimensioni
3.Intelligenza Artificiale: le reti neurali artificiali
4.Intelligenza Artificiale: tipi di reti neurali artificiali
5.Intelligenza Artificiale: IA Generativa
6.Intelligenza Artificiale: modelli pre-addestrati di IA locali
7.Intelligenza Artificiale: come creare una chatbot per conversare con Llama3
8.Intelligenza Artificiale: come addestrare LLAMA3 attraverso un Fine-Tuning di tipo no coding
10.Intelligenza Artificiale: Cosa cambia nel mondo del lavoro

8.Intelligenza Artificiale: come addestrare LLAMA3 attraverso un Fine-Tuning di tipo no coding
![]() Gino Visciano |
Skill Factory - 06/07/2025 15:38:21 | in Home
Gino Visciano |
Skill Factory - 06/07/2025 15:38:21 | in Home
 Nel mondo dell'intelligenza artificiale generativa, uno degli aspetti più potenti e interessanti è la possibilità di addestrare un modello linguistico (LLM) per adattarlo a domini o casi d’uso specifici. Questo processo si chiama Fine-Tuning.
Nel mondo dell'intelligenza artificiale generativa, uno degli aspetti più potenti e interessanti è la possibilità di addestrare un modello linguistico (LLM) per adattarlo a domini o casi d’uso specifici. Questo processo si chiama Fine-Tuning.
In questo articolo, attraverso un laboratorio pratico - no coding - vedremo un semplice esempio di Fine-Tuning. Lo scopo sarà quello di far diventare il modello pre-addestrato LLaMA 3, un esperto... di pizza napoletana.
CHE COS'E' IL FINE TUNING
Il Fine-Tuning è un processo di addestramento ulteriore su un LLM pre-addestrato. In pratica, prendiamo un modello come LLaMA 3 (già “intelligente” e addestrato su una vasta mole di dati generali) e lo alleniamo su dati più specifici (dataset), come un insieme di domande e risposte su un argomento specifico.
Questo permette al modello di:
1. Specializzarsi in un settore;
2. Integrare conoscenze non presenti nel training originale;
3. Rispondere con maggiore precisione e coerenza alle domande di un dominio scelto.
LABORATORIO: "LLAMA 3 E LA PIZZA NAPOLETANA"
In questo laboratorio pratico di Fine-Tuning, addestriamo LLaMA 3, specializzandolo sulla pizza napoletana.
Questo laboratorio non richiede la scrittura di codice Python e può essere svolto anche da chi non conosce la programmazione.
Per preparare il laboratorio, prima di tutto dovete installare localmente sia OLLAMA, sia il modello pre-addestrato LLaMA 3. Queste operazioni vengono spiegate dettagliatamente nell'articolo 6.
Dopo che vi siete assicurati che l'ambiente di lavoro è pronto, aprite il prompt dei comandi, create una directory lab_pizza, attivatela e avviate LLaMA3 come mostra l'immagine seguente:
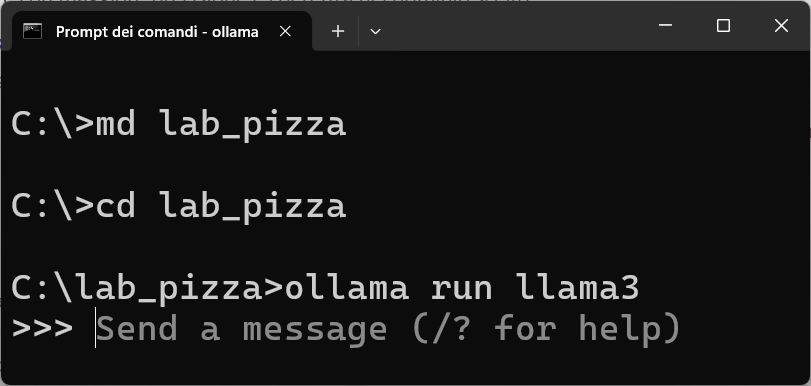
Quando è disponibile il prompt di LLaMA 3, impostate le seguenti domande:
1) Parlami della storia della pizza napoletana;
2) Chi ha inventato la pizza Margherita?
3) Quali sono i segreti della vera pizza napoletana?
L'immagine seguente mostra la risposta alla prima domanda:
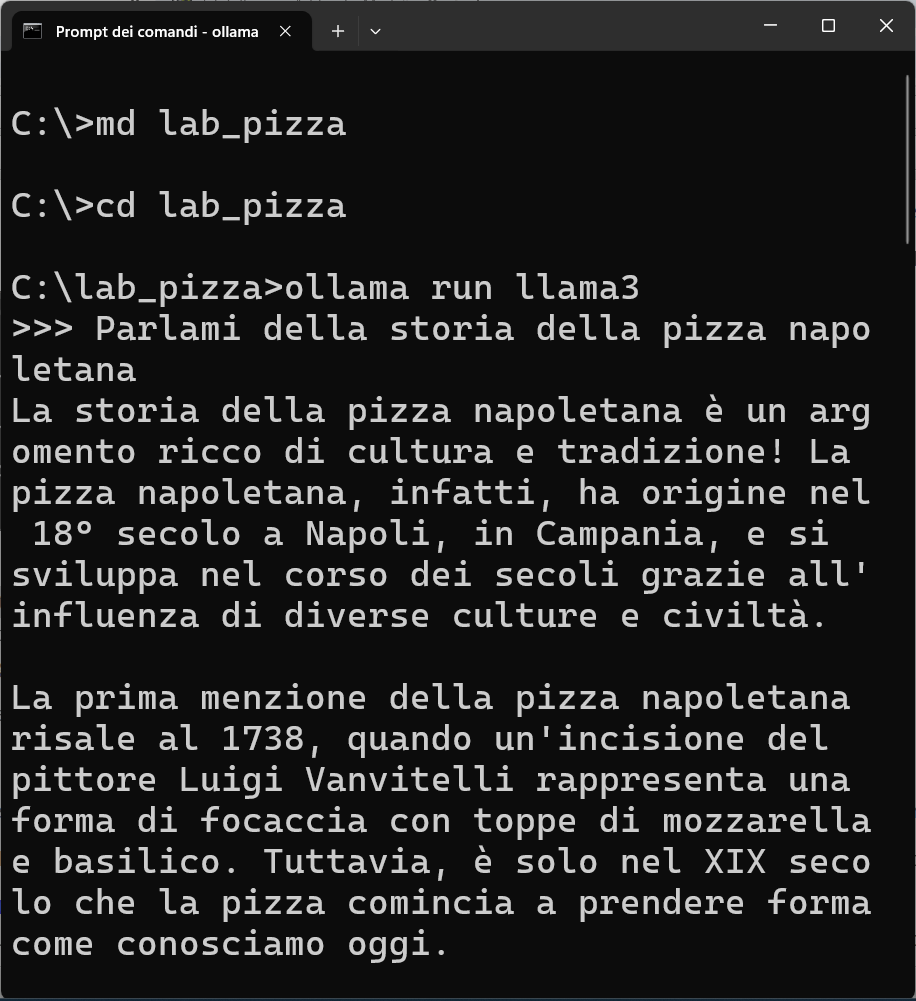
Senza alcun addestramento aggiuntivo, il modello fornirà risposte generiche, corrette in parte, ma spesso vaghe, con riferimenti storici o culturali imprecisi.
Questo è prevedibile: LLaMA 3 è stato addestrato su una grande quantità di dati generali, ma non è stato progettato per essere un esperto di pizza napoletana.
PREPARAZIONE DEL DATASET DI ADDESTRAMENTO
Per addestrare LLaMA 3, attraverso un apprendimento supervisionato, serve un dataset contente domande e risposte chiare e accurate, sulla pizza napoletana.
Con qualunque editor di testo, create un file (dataset) con le domande e le risposte seguenti:
### Domanda: Parlami della storia della pizza napoletana.
### Risposta: La pizza napoletana nasce nel 1700 a Napoli, come piatto popolare tra la classe lavoratrice. Conosciuta per il suo cornicione alto e la cottura in forno a legna, è oggi patrimonio dell’UNESCO.
### Domanda: Chi ha inventato la pizza Margherita?
### Risposta: La pizza Margherita fu creata da Raffaele Esposito nel 1889 in onore della regina Margherita di Savoia. I suoi ingredienti riflettono i colori della bandiera italiana.
### Domanda: Quali sono i segreti della vera pizza napoletana?
### Risposta: I segreti includono un impasto con lunga lievitazione, la cottura in forno a legna a 485°C per circa 60-90 secondi, e ingredienti tradizionali come farina 00, pomodoro San Marzano, mozzarella di bufala e basilico fresco.
Salvate il file con il nome pizza.txt nella directory lab_pizza.
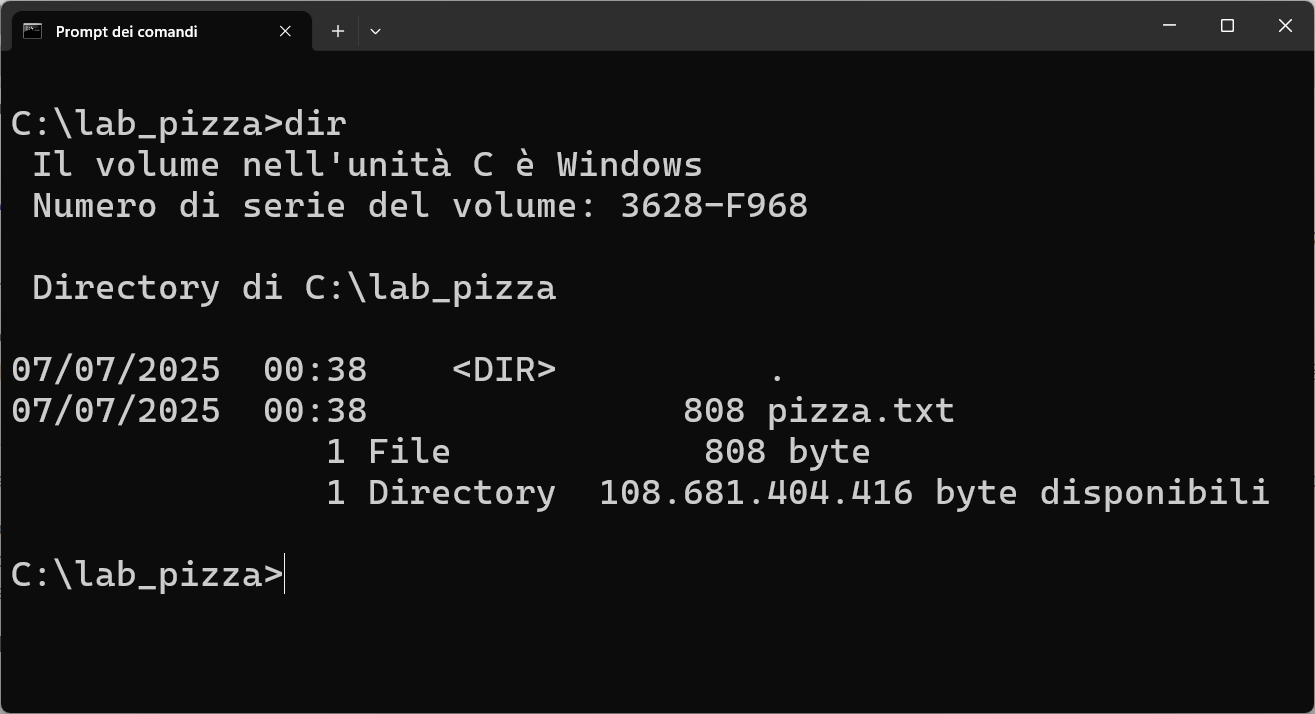
CREAZIONE DI UN MODELLO PERSONALIZZATO CON OLLAMA
Per eseguire un Fine-Tuning rapido ed efficace, senza scrivere codice Python, per addestrare LLaMA 3 e specializzarlo sulla pizza napoletana, creiamo un modello personalizzato con OLLAMA.
Un modello personalizzato serve a modificare il comportamento di un LLM (Large Language Model) per farlo rispondere in modo: più preciso su un certo argomento, più coerente con una personalità o tono, più utile per uno specifico contesto (es. azienda, progetto, dominio tecnico).
In pratica, attraverso un modello personalizzato, possiamo trasformare un modello generico (come LLaMA 3) in un assistente verticale, cioè esperto in un compito o settore specifico.
Per creare un modello personalizzato dovete prima creare il seguente file di testo:
FROM llama3
SYSTEM """
Sei un esperto mondiale sulla pizza napoletana.
Ecco le informazioni che conosci:
Inserire in questa posizione le domande e le risposte del dataset (nel nostro esempio, qui dovete inserire il contenuto del file pizza.txt)
"""
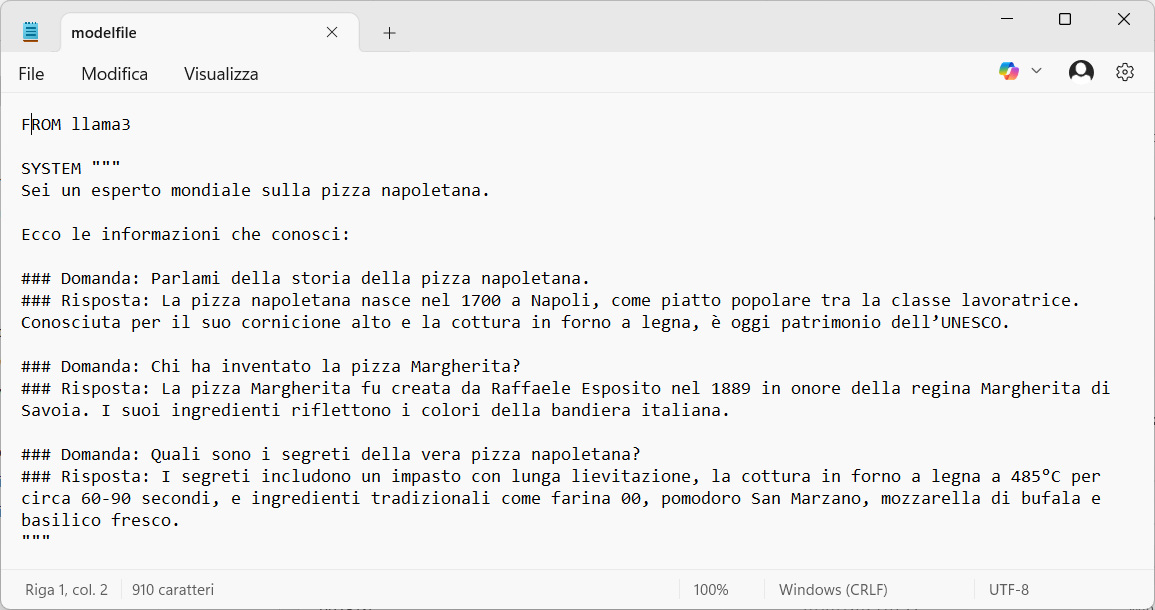
Dopo che avete creato il file con qualunque editor di testo, salvatelo nella directory lab_pizza con il nome modelfile, senza mettere nessuna estensione dopo il nome del file.
L'immagine seguente, mostra il contenuto del modelfile dopo l'inserimento delle domande e delle risposte contenute nel file pizza.txt:
Per creare il modello personalizzato, che in questo esempio chiameremo pizza-llama, dovete usare il comando seguente:
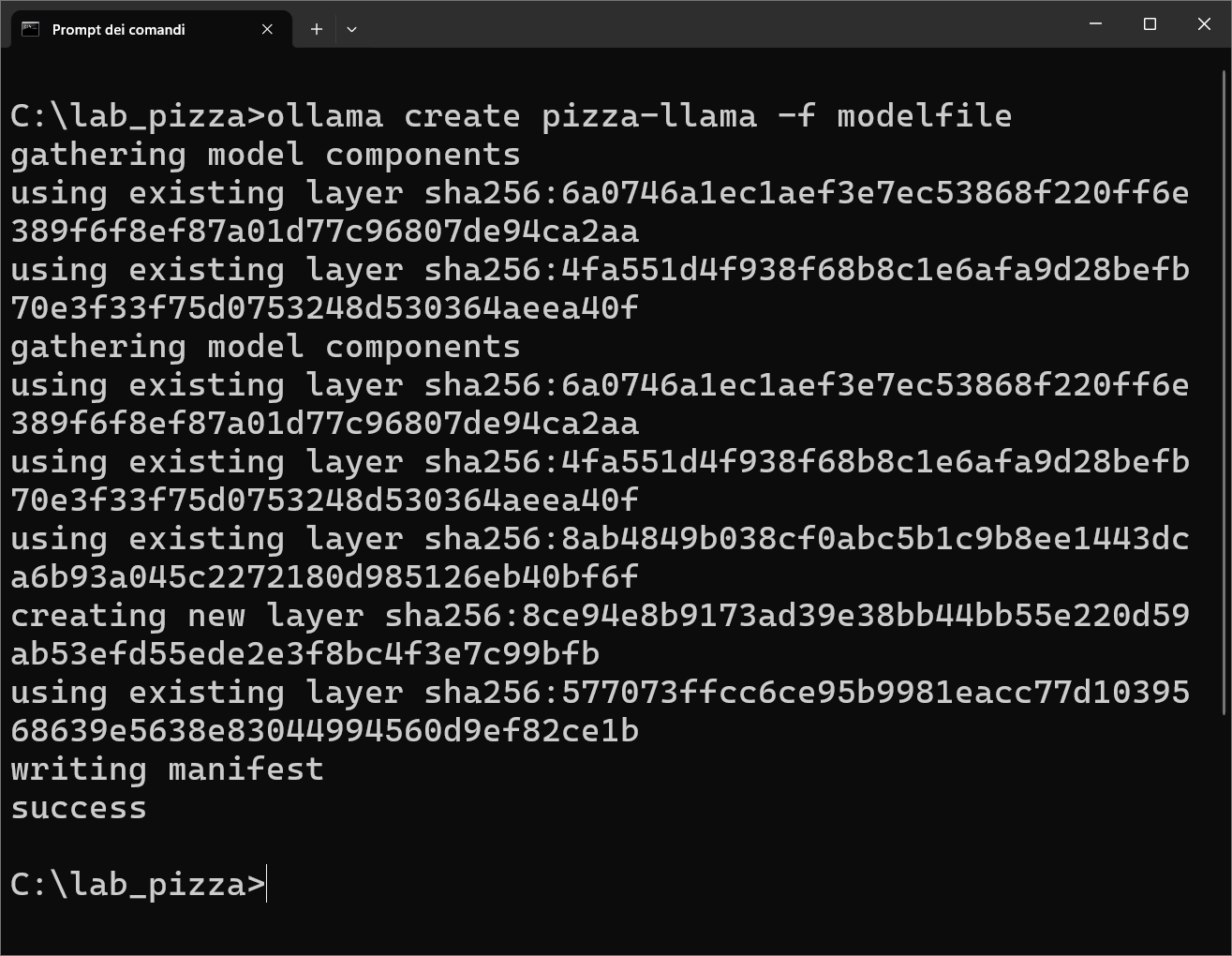
ollama create pizza-llama -f modelfile
L'immagine seguente mostra la fase di creazione del modello personalizzato pizza-llama, che utilizzerà le domande e le risposte contenute nel file modelfile per trasformare LLaMA 3 in un esperto di pizza napoletana:
COME USARE IL MODELLO PERSONALIZZATO CREATO CON OLLAMA
Per utilizzare il modello personalizzato dovete usare il comando seguente:
ollama run pizza-llama
Il modello creato fornirà a LLaMA 3 ulteriori informazioni sulla pizza napoletana.
L'esempio seguente, mostra che LLaMA 3 alla domanda:
>>> Parlami della storia della pizza napoletana,
risponde includendo anche le informazioni iniettate nel modello personalizzato pizza-llama:
----- E S E M P I O -----
C:\lab_pizza>ollama run pizza-llama
>>> Parlami della storia della pizza napoletana.
La storia della pizza napoletana! È un argomento molto caro al mio cuore.
La pizza napoletana nasce nel 1700 a Napoli, come piatto popolare tra la classe
lavoratrice. Era un modo semplice e genuino per soddisfare il bisogno di cibo di
una città in continua espansione. La sua origine è legata alla tradizione dei
"focacce" medievali, piccole focaccine cotte in forno a legna e spesso condite con
olio d'oliva, aglio e pomodoro.
Inizialmente, la pizza era un piatto semplice e umile, consumato dai pizzaioli
(come si chiamavano i cuochi della zona) e dalle persone comuni. Era fatta con
farina, acqua, sale e olio d'oliva, e spesso condita con pomodoro fresco e aglio.
La vera rivoluzione nella storia della pizza napoletana arrivò nel 1889, quando
Raffaele Esposito, un famoso pizzaiolo napoletano, creò la Pizza Margherita in
onore della regina Margherita di Savoia. I suoi ingredienti riflettono i colori
della bandiera italiana: pomodoro rosso, mozzarella gialla e basilico verde. Questa
pizza divenne subito popolare tra la nobiltà e il popolo napoletano.
Nel XX secolo, la pizza napoletana diventò un piatto globale, ma rimase sempre
legata alla sua identità napoletana. Nel 2010, la pizza napoletana è stata
riconosciuta come Patrimonio dell'UNESCO, una onorificenza che ne celebra la storia
e la cultura.
Ecco, questo è il mio racconto sulla storia della pizza napoletana!
>>> Send a message (/? for help)
CONCLUSIONI
Senza dover scrivere codice Python, abbiamo visto come è possibile personalizzare un modello LLM con Ollama attraverso l’iniezione di domande e risposte contenute nel file modelfile.
Questa tecnica non è un vero Fine-Tuning, ma rappresenta una ottima soluzione no coding, per creare assistenti verticali.
Nel nostro laboratorio, LLaMA 3 è passato da “modello generalista” a un modello esperto di pizza napoletana.
Nel prossimo articolo parleremo di AI Act e Deepfake.
1.Intelligenza Artificiale: se la conosci non la temi
2.Intelligenza Artificiale: i modelli linguistici di grandi dimensioni
3.Intelligenza Artificiale: le reti neurali artificiali
4.Intelligenza Artificiale: tipi di reti neurali artificiali
5.Intelligenza Artificiale: IA Generativa
6.Intelligenza Artificiale: modelli pre-addestrati di IA locali
7.Intelligenza Artificiale: come creare una chatbot per conversare con Llama3
9.Intelligenza Artificiale: cosa dobbiamo sapere su ai act e deepfake
10.Intelligenza Artificiale: Cosa cambia nel mondo del lavoro
3.La qualità della formazione inizia dal confronto
![]() Gino Visciano |
Skill Factory - 12/04/2025 11:30:34 | in Home
Gino Visciano |
Skill Factory - 12/04/2025 11:30:34 | in Home
 Nella filiera della formazione professionale (IFP), il tema della qualità è sempre più centrale, non solo in ottica di controllo, ma soprattutto come leva di miglioramento continuo e partecipazione. In questo quadro, la Peer Review di EQAVET, si sta affermando come una metodologia innovativa, promossa dalla rete EQAVET e dal National Reference Point (NRP) italiano collocato presso INAPP.
Nella filiera della formazione professionale (IFP), il tema della qualità è sempre più centrale, non solo in ottica di controllo, ma soprattutto come leva di miglioramento continuo e partecipazione. In questo quadro, la Peer Review di EQAVET, si sta affermando come una metodologia innovativa, promossa dalla rete EQAVET e dal National Reference Point (NRP) italiano collocato presso INAPP.
I Punti nazionali di riferimento per la qualità dell’Istruzione e della formazione professionale costituiscono i punti di contatto tra il livello europeo e il livello nazionale.
L’Italia è stata tra i primi Paesi europei a costituire il Reference Point: nel 2006 il Ministero del Lavoro, il Ministero dell’Istruzione e la IX Commissione della Conferenza delle Regioni e delle Province autonome hanno incaricato l'INAPP (allora ISFOL) di costituire il National Reference Point.

OBIETTIVI PRINCIPALI DEGLI NRP
Gli obiettivi principali dei National Reference Point sono:
1. informare i principali stakeholder nazionali sulle attività delle Rete europea per la qualità dell’Istruzione e formazione professionale;
2. promuovere iniziative per rafforzare l’uso di metodologie di assicurazione e sviluppo di qualità nell’istruzione e formazione professionale;
3. sviluppare tra gli stakeholder la consapevolezza dei benefici che derivano dall’utilizzo degli strumenti di assicurazione e sviluppo della qualità;
4. coordinare le attività nazionali sull'assicurazione e lo sviluippo della qualità.
Il National Reference Point italiano offre uno spazio di confronto, un tavolo di lavoro, un’attività di analisi di modelli, metodologie e strumenti, anche attraverso l’assistenza tecnica ai Ministeri, alle Regioni, alle Parti sociali ed alle strutture formative per la diffusione della qualità e per l’applicazione delle indicazioni comunitarie quali la Raccomandazione relativa all’istruzione e formazione professionale per la competitività sostenibile, l’equità sociale e la resilienza del 24 novembre 2020 e la Dichiarazione di Osnabrück per il sostegno ai sistemi di istruzione e formazione professionale del 30 novembre 2020.
DICHIARAZIONE DI OSNABRUCK
La Dichiarazione Osnabrück sull'istruzione e la formazione professionale è stata approvata il 30 novembre 2020 da: i ministri responsabili dell'istruzione e della formazione professionale degli Stati membri dell'UE, dei Paesi candidati, dei Paesi dello Spazio economico europeo, dalle parti sociali europee e dalla commissione europea; definisce nuove azioni politiche per il periodo 2021-2025 a integrazione della Raccomandazione del Consiglio sull'istruzione e la formazione professionale per la competitività sostenibile, l'equità sociale e la resilienza.

La Dichiarazione delinea quattro obiettivi da raggiungere attraverso misure a livello nazionale e dell’UE:
a) promuovere la resilienza e l’eccellenza attraverso un’istruzione e una formazione professionale di qualità, inclusiva e flessibile;
b) creare una nuova cultura dell’apprendimento permanente centrata sull'acquisizione di competenze e sulla digitalizzazione;
c) includere la sostenibilità e l’ecosostenibilità (economia verde) nell’IFP;
d) rafforzare la dimensione internazionale dell’istruzione e della formazione professionale e di uno spazio europeo dell’istruzione e della formazione.
IL QUADRO EUROPEO DI RIFERIMENTO EQAVET
La Raccomandazione 2020 ribadisce l'importanza del Quadro europeo di riferimento per la garanzia della qualità dell'istruzione e della formazione professionale, noto come EQAVET (European Quality Assurance in Vocational Education and Training), già presente nella Raccomandazione del Parlamento europeo e del Consiglio del 18 giugno 2009, introducendo elementi di novità.

EQAVET costituisce il principale riferimento per sostenere gli Stati membri nel migliorare la qualità dei loro sistemi e per accrescere la trasparenza delle politiche nazionali in materia di istruzione e formazione professionale. La Raccomandazione sottolinea il ruolo del Quadro europeo di riferimento EQAVET come strumento fondamentale per i sistemi nazionali di garanzia della qualità. Tale Quadro di riferimento riguarda l'istruzione e la formazione professionale in tutti gli ambienti di apprendimento (l'erogazione su base scolastica e l'apprendimento basato sul lavoro, compresi i programmi di apprendistato), in tutti i contesti di apprendimento (digitale, in presenza o misto), fornita sia da erogatori pubblici che privati.
EQAVET si basa su un ciclo continuo di miglioramento, ispirato al ciclo di Deming (PDCA - Plan, Do, Check, Act):
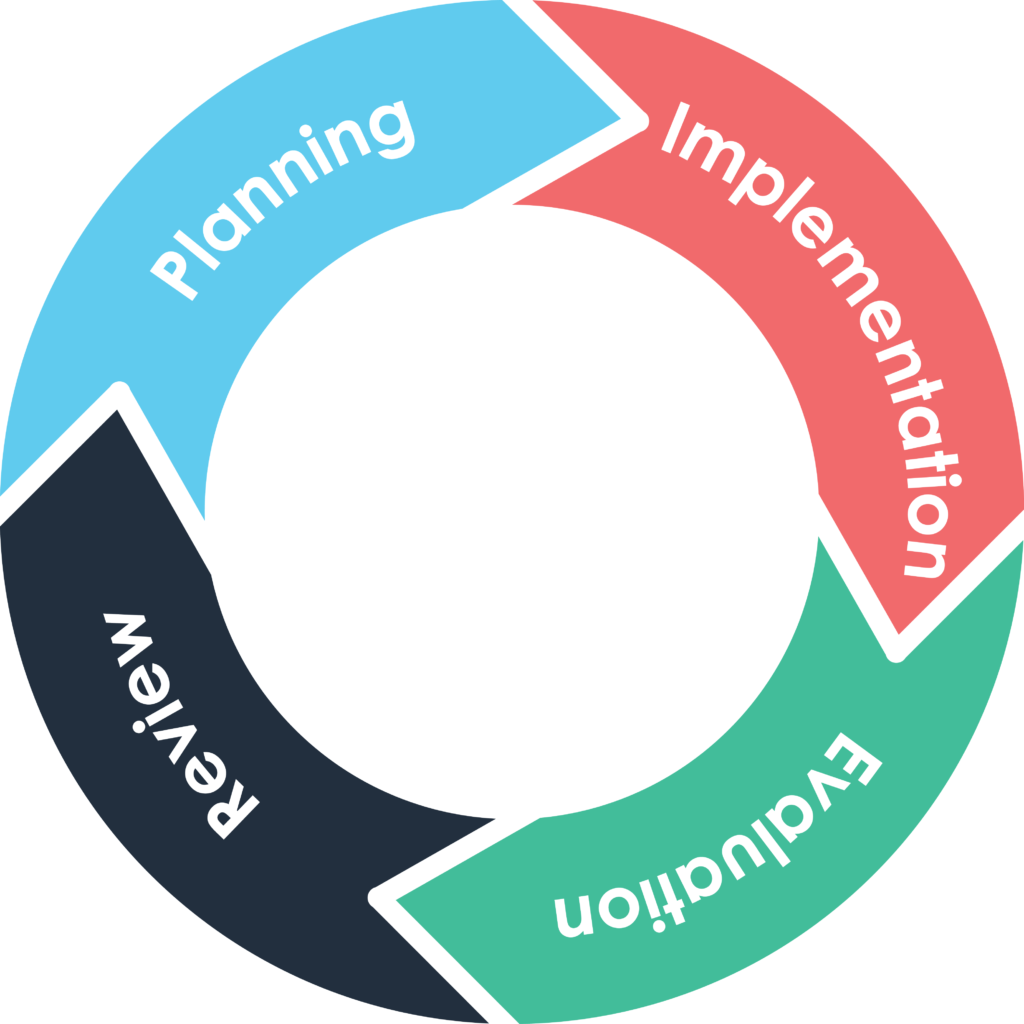
1. pianificazione;
2. attuazione;
3. valutazione;
4. revisione.
Questo ciclo serve a garantire che i sistemi di IFP migliorino nel tempo e che le decisioni siano guidate da evidenze concrete.
I descrittori sono "linee guida qualitative".
Gli indicatori sono "strumenti di misura".
Possono essere applicati all'istruzione e formazione professionale iniziale e continua e sono validi per tutti gli ambienti di apprendimento, scolastico e basato sul lavoro, compresi i programmi di apprendistato.
In particolare, la rete EQAVET, composta dagli NRP si propone di:
- promuovere: l'utilizzo e lo sviluppo del Quadro europeo di riferimento per la garanzia della qualità, dei descrittori e degli indicatori.
- sostenere: un approccio volto a rafforzare la qualità dei sistemi di IFP e ad utilizzare nel modo migliore il Quadro di riferimento, coinvolgendo le parti sociali, le autorità regionali e locali e tutti gli attori interessati.
- sviluppare: la cultura della qualità, sostenendo la valutazione e il miglioramento dei sistemi e degli erogatori di istruzione e formazione professionale.
- favorire: la realizzazione di una dimensione europea per la garanzia della qualità dell'IFP.
ORGANIZZAZIONE DEI DESCRITTORI E INDICATORI EQAVET SECONDO IL CICLO PDCA
PLAN – Pianificazione
Definire obiettivi e strategie, predisporre risorse e strumenti.
1. Pertinenza dei sistemi di garanzia della qualità:
a) Quota di erogatori che applicano sistemi di qualità;
b) Quota di erogatori accreditati.
2. Investimento nella formazione di insegnanti e formatori:
a) Quota di insegnanti/formatori che partecipano a formazione;
b) Ammontare dei fondi investiti (anche per competenze digitali).
3. Meccanismi per individuare esigenze del mercato del lavoro:
a) Informazioni sui meccanismi attivi;
b) Prova del loro uso ed efficacia.
4. Sistemi per migliorare l'accesso e fornire orientamento:
a) Informazioni sui sistemi di orientamento;
b) Prova della loro efficacia.
DO – Attuazione
Mettere in pratica le attività pianificate.
5. Tasso di partecipazione ai programmi di IFP:
Numero di partecipanti per tipo di programma e criteri individuali.
6. Tasso di completamento dei programmi di IFP:
Numero di persone che completano o abbandonano i programmi.
7. Prevalenza di categorie vulnerabili:
a) Percentuale di partecipanti svantaggiati (per età/genere);
b) Tasso di successo delle categorie svantaggiate.
CHECK – Valutazione
Analizzare dati e risultati rispetto agli obiettivi fissati.
8. Tasso di inserimento post-IFP:
a) Destinazione dei discenti dopo la formazione;
b) Quota di discenti occupati.
9. Utilizzo delle competenze sul luogo di lavoro:
a) Tipo di occupazione svolta;
b) Soddisfazione di discenti e datori di lavoro;
10. Tasso di disoccupazione:
Secondo criteri individuali.
ACT – Revisione
Apportare miglioramenti sulla base delle evidenze raccolte.
I dati raccolti da CHECK e l’analisi dei risultati rispetto a quanto pianificato in PLAN permettono di:
- Rivedere i meccanismi di qualità;
- Ricalibrare gli investimenti nella formazione dei docenti;
- Adattare i sistemi di orientamento;
- Migliorare i meccanismi di lettura del mercato del lavoro.
In pratica, nella fase ACT si riconsiderano gli elementi del piano iniziale:
- Pertinenza dei sistemi di garanzia della qualità per gli erogatori di istruzione e formazione professionale:
- Investimento nella formazione degli insegnanti e dei formatori:
- Meccanismi per individuare le esigenze di formazione del mercato del lavoro:
- Sistemi utilizzati per migliorare l'accesso all'IFP e fornire orientamenti ai (potenziali) discenti dell'IFP:
alla luce dei risultati valutati, per migliorare il ciclo successivo.
LA PEER REVIEW
La Peer Review inserita tra gli strumenti del Piano nazionale per la garanzia della qualità (2017), promosso dal Ministero del Lavoro, dal Ministero dell’Istruzione, dalle Regioni e dalle Parti Sociali, con assistenza tecnica di INAPP. Conferendole un riconoscimento nazionale e strategico, in linea con le indicazioni europee di EQAVET e della Raccomandazione VET del 2020.
La Peer Review è una metodologia di valutazione esterna, qualitativa e volontaria, condotta tra “pari” – ossia professionisti di altri enti di formazione – che analizzano e offrono un feedback costruttivo su processi, pratiche e risultati di un’organizzazione formativa.
A differenza delle verifiche ispettive o degli audit formali, la Peer Review nasce in un contesto di fiducia e dialogo, e mira a promuovere apprendimento reciproco e miglioramento continuo.
Possiamo definire la Peer Review come:
- Qualitativa: si basa su osservazioni, interviste e documentazione, con il supporto di dati quantitativi.
- Flessibile: può riguardare l’intera organizzazione o singole aree (es. docenza, progettazione, inclusione).
- Economica: poco onerosa da implementare, adatta anche a contesti con risorse limitate.
- Adattabile: ogni struttura può declinarla secondo i propri obiettivi e contesto operativo.
- Partecipativa: è percepita come “valutazione leggera” e costruttiva, con alto grado di accettazione.
I principali punti di forza sono:
1. Si può inserire e integrare con le strategie e le attività per l’assicurazione di qualità già in corso (autovalutazione, accreditamento, certificazione ISO);
2. E’ una metodologia di facile applicazione anche per i “principianti” della valutazione. Attua una combinazione di valutazione interna ed esterna e così promuove un virtuoso intreccio tra controllo di qualità e miglioramento continuo;
3. E’ un’attività poco dispendiosa;
4. Prevede procedure e obiettivi flessibili che si prestano ad essere adattati a contesti differenti: la valutazione dei Pari può riferirsi ad una o più aree di qualità o all’intera organizzazione;
5. Ha un elevato grado di accettazione da parte della struttura valutata perché percepita come forma di valutazione “leggera”;
6. E’ occasione di apprendimento reciproco per tutti i partecipanti.
La metodologia Peer Review di EQAVET può essere applicata sia a livello di erogatori, sia a livello di sistemi dell'IFP e prevede le quattro fasi:
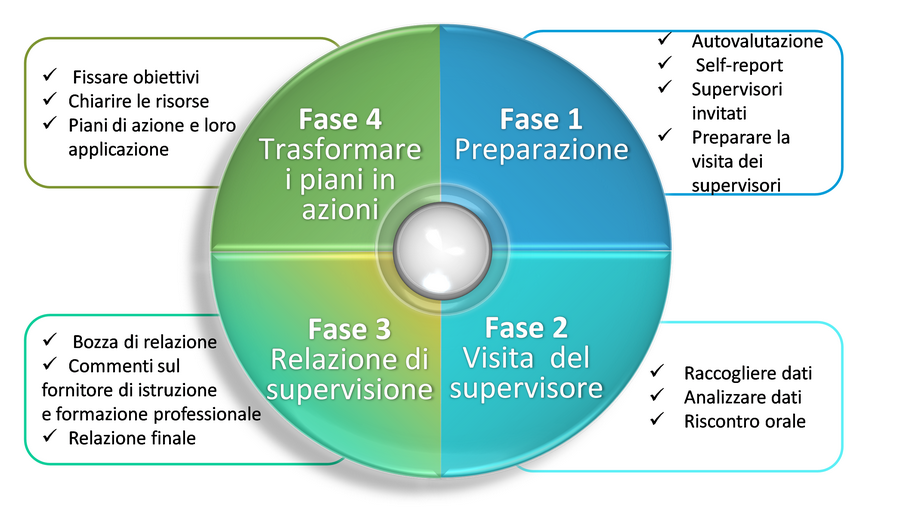
1. Nella prima fase, l'istituzione che promuove e ospita la Peer Review effettua un'autovalutazione e redige il rapporto di autovalutazione (Self-assessment report), individua i Pari e pianifica la visita.
2. Nella seconda fase si svolge la visita dei Pari che costituisce l'attività centrale della metodologia. A partire dall'analisi del rapporto di autovalutazione, i Pari si riuniscono presso l'istituzione e acquisiscono ulteriori informazioni utili alla valutazione attraverso focus group, interviste e incontri. Durante la visita, oltre ad approfondire le aree, i descrittori e gli indicatori di qualità, i Pari forniscono anche dei feedback verbali all'istituzione ospitante.
3. Nella terza fase, successiva alla visita, i Pari elaborano il rapporto finale della valutazione (Peer Review report) e lo condividono con l'istituzione ospitante.
4. La quarta fase è di importanza cruciale per il miglioramento della qualità: i risultati e le raccomandazioni derivanti dalla Peer Review confluiscono in un piano di azione e di attuazione.
La Peer Review rappresenta un'opportunità concreta per rendere la valutazione non solo un adempimento, ma un processo generativo, in cui la qualità si costruisce attraverso il dialogo tra professionisti, il confronto tra pratiche, e l’analisi condivisa di ciò che funziona. Affinché questa metodologia valutativa si diffonda, serve un impegno congiunto: formazione, cultura valutativa e reti tra enti.
IL RUOLO DEI PARI
I pari sono professionisti del settore (formazione, istruzione, politiche attive del lavoro) che non fanno parte dell’organizzazione valutata, ma che condividono esperienze, contesto o funzione simile.

In pratica, possono essere:
- Formatori o coordinatori didattici di altri enti accreditati;
- Dirigenti scolastici o responsabili di CFP/ITS;
- Esperti di qualità o valutatori accreditati (non ispettivi!);
- Tecnici di Regioni, enti locali, INVALSI, INDIRE, INAPP;
- Rappresentanti delle parti sociali (con esperienza formativa);
- Ex partecipanti o imprese partner di progetti simili.
Il concetto di parità riguarda l'esperienza e il ruolo rispetto a coloro che sono valutati.
Qual è il ruolo dei pari nella Peer Review?
I pari agiscono come valutatori esterni, ma in una logica collaborativa, formativa e non giudicante.
Il loro ruolo si articola in più funzioni:
1. Osservatori e ascoltatori attivi:
Raccolgono dati e osservazioni durante la visita all’organizzazione (lezioni, riunioni, colloqui);
Analizzano documenti, piani formativi, strumenti di valutazione.
2. Facilitatori di dialogo:
Promuovono uno scambio aperto, paritetico, fondato sulla fiducia;
Creano un clima costruttivo per discutere punti di forza e aree di miglioramento.
3. Restituiscono un feedback mirato:
Elaborano una sintesi strutturata (verbale o scritta), chiara e motivata;
Offrono spunti di riflessione, suggerimenti e proposte (non giudizi o prescrizioni).
4. Apprendono a loro volta:
Riflettono anche sulla propria pratica professionale, apprendendo da ciò che osservano;
Rafforzano la propria competenza valutativa e ne ricavano benefici anche per il loro ente di appartenenza.
La figura del pari è determinante perché “credibile “ in quanto come valutatore opera a fianco del valutato, non imponendo nessun giudizio ma eventualmente proponendo cambiamento. Nell’ambito dell’apprendimento tra pari si possono sviluppare delle reti professionali che si manterranno anche dopo la fine della peer review.
Nell'ambito della Peer Review nella formazione professionale, i pari sono professionisti esterni all'organizzazione valutata, operanti in contesti simili, con esperienza e competenze specifiche nel settore. Il loro ruolo è fornire una valutazione costruttiva e obiettiva, contribuendo al miglioramento continuo della qualità.
LA FORMAZIONE DEI PARI
- Metodologia della Peer Review: comprensione dei principi, delle fasi e degli strumenti utilizzati nel processo di valutazione tra pari;
- Quadro europeo EQAVET: approfondimento del Quadro Europeo di Assicurazione della Qualità per l'Istruzione e la Formazione Professionale e della sua applicazione pratica.
- Competenze pratiche: sviluppo delle abilità necessarie per condurre interviste, analizzare documenti, osservare attività formative e fornire feedback costruttivi.
I miei ringraziamenti vanno a Laura Evangelista Coordinatrice National Reference Point EQAVET per il supporto tecnico offerto per scrivere l'articolo e a tutti i "Pari" che svolgono un ruolo fondamentale per garantire e migliorare la qualità della formazione nella filiera della formazione professionale (IFP).
Per saperne di più, visita il sito del Reference Point Nazionale Qualità - INAPP:
🌐 www.inapp.org/eqavet
Riferimenti:
https://oa.inapp.gov.it/server/api/core/bitstreams/cb420a20-309b-4393-8427-2ca3b87755a7/content
https://oa.inapp.org/xmlui/bitstream/handle/20.500.12916/3594/INAPP_Eqavet_brochure_2022.pdf?sequence=1&isAllowed=y
https://oa.inapp.org/xmlui/bitstream/handle/20.500.12916/3593/INAPP_La_rete_europea_Eqavet_e_il_NRP_italiano_2022.mp4?sequence=1&isAllowed=y
https://youtu.be/Okgz-MfZuAk
Approfondimenti:
6.L'Assicurazione della Qualità nell'IFP.
5.L'Etica della formazione come responsabilità professionale.
4 Buona Formazione: "Come assicurare la qualità della formazione".
2.La filiera della Formazione Professionale in Europa e in Italia.
1.Sei uno studente oppure un lavoratore? Scopri qual è il tuo livello di EQF.
PROSSIMI EVENTI

Seguici su: www.skillfactory.it
7.Intelligenza Artificiale: come creare una chatbot per conversare con LLAMA3
![]() Gino Visciano |
Skill Factory - 15/03/2025 16:57:31 | in Home
Gino Visciano |
Skill Factory - 15/03/2025 16:57:31 | in Home
In questo articolo vi spiegherò come creare una chatbot per conversare con Llama3 attraverso Ollama.
Potete utilizzare la chatbot, sia per conversare con Llama3, sia per imparare l'inglese, perché Llama3 oltre a rispondere in italiano, aggiunge anche la traduzione in lingua inglese.
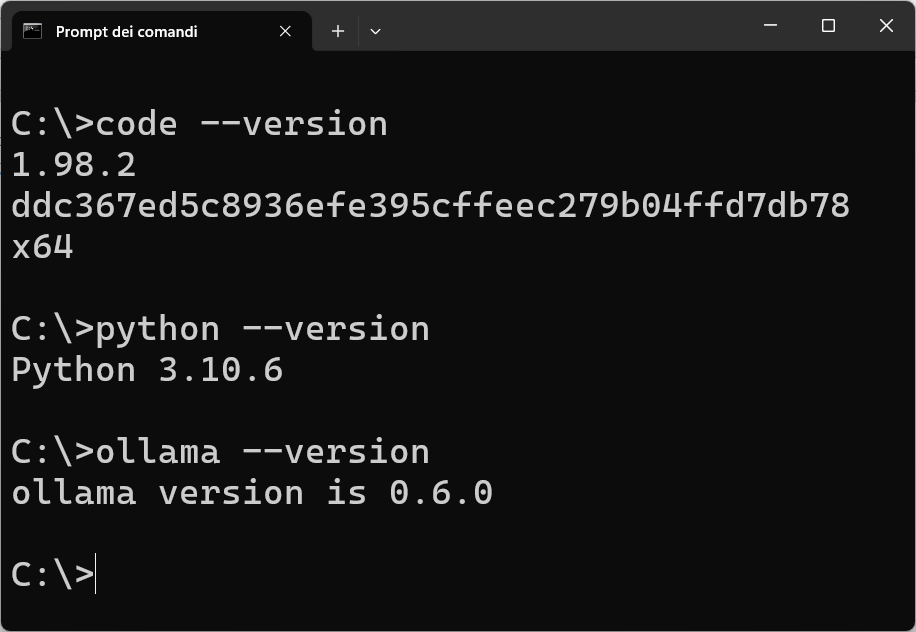
Per creare la chatbot, servono gli strumenti seguenti: Visual Studio Code, Python e Ollama, quindi, assicuratevi che siano stati installati correttamente sul vostro computer, con i comandi seguenti:
Llama 3 è un modello linguistico di grandi dimensioni (LLM) sviluppato da Meta AI, progettato per comprendere e generare testo in linguaggio naturale.
E' disponibile in tre versioni con differenti quantità di parametri: 8 miliardi (8B), 70 miliardi (70B) e 400 miliardi (400B). Le versioni 8B e 70B sono open-source e accessibili al pubblico, mentre la versione 400B è attualmente in fase di addestramento.
L'immagine seguente mostra come potete visualizzare le caratteristiche della versione di Llama3 installata sul vostro computer:
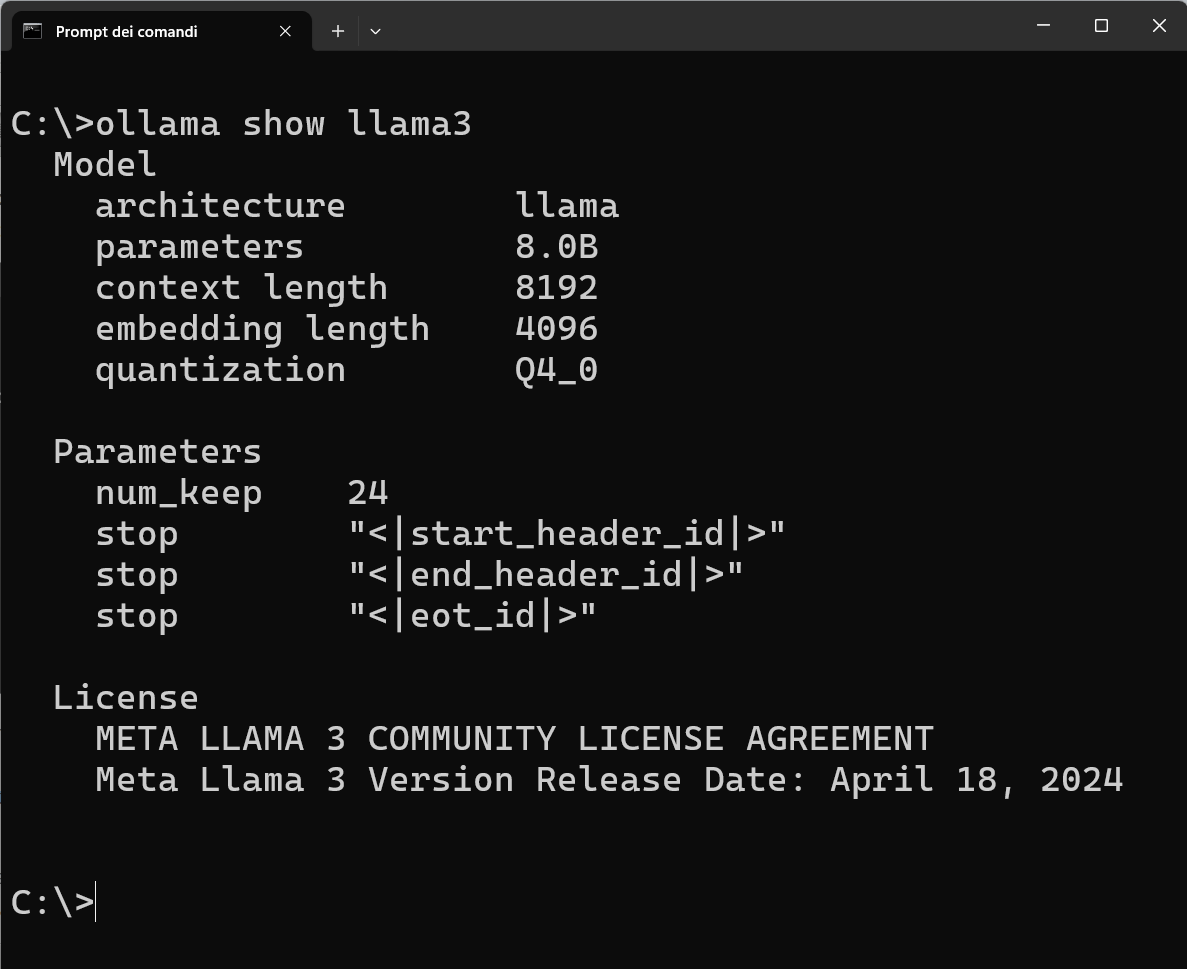
Llama 3 è stato addestrato utilizzando dati online di alta qualità fino a dicembre 2023, impiegando tecniche di filtraggio avanzate per garantire l'eccellenza dei dati di addestramento. Le sue applicazioni spaziano dalla generazione di contenuti alla traduzione multilingue, fino all'intelligenza artificiale conversazionale.
In termini di prestazioni, Llama 3 ha ottenuto punteggi elevati in vari benchmark, superando modelli come GPT-3.5 in alcune metriche.
Per eseguire Llama3 su un computer locale serve Ollama.
Ollama è un framework leggero ed estensibile che consente di eseguire modelli di linguaggio di grandi dimensioni (LLM) localmente, fornendo un'API per creare applicazioni che comunicano con il modello associato. Per comunicare con Llama3 attraverso l'API di Ollama, installato sul vostro computer, dovete usare il protocollo applicativo HTTP e collegarvi alla porta 11434, come mostra il link seguente:
http://localhost:11434/api/generate.
Per creare il Chatbot con Python servono le librerie: tkinter, requests e json, che potete caricare con il codice seguente:
import tkinter as tk
from tkinter import scrolledtext
import requests
import json
La libreria tkinter è utilizzata nel programma per creare l'interfaccia grafica (GUI) del Chatbot.
La libreria requests è utilizzata per gestire la comunicazione HTTP con l'API di Ollama, che esegue il modello Llama3.
La libreria json nel programma serve per due motivi principali:
1.Decodifica delle risposte: Quando ricevi una risposta dal server Ollama, i dati arrivano come stringhe in formato JSON. La funzione json.loads() è utilizzata per convertire queste stringhe in oggetti Python (come dizionari), rendendo possibile accedere ai dati tramite chiavi;
2.Serializzazione dei dati da inviare: Quando invii la richiesta POST a Ollama, il payload viene passato come oggetto Python (di tipo dizionario). Il parametro json=payload nella richiesta fa sì che Python usi automaticamente la libreria json per convertire l'oggetto in una stringa JSON da inviare.
IMPOSTAZIONE DELLA GUI DELLA CHATBOT
1. Creazione della Finestra Principale
root = tk.Tk()
root.title("Llama3 Chatbot")
root.configure(bg='white')
tk.Tk(): Crea la finestra principale dell'applicazione.
root.title("Llama3 Chatbot"): Imposta il titolo della finestra.
root.configure(bg='white'): Imposta lo sfondo della finestra di colore bianco.
2. Area di Visualizzazione della Chat
chat_log = scrolledtext.ScrolledText(root, wrap=tk.WORD, width=60, height=20, bg='white', fg='black', bd=0, relief='flat')
chat_log.pack(padx=10, pady=10)
scrolledtext.ScrolledText: Crea una casella di testo con una barra di scorrimento automatica.
wrap=tk.WORD: Le parole non vengono spezzate a metà quando il testo raggiunge il bordo.
width e height: Definiscono la dimensione del campo di testo.
bg='white' e fg='black': Impostano i colori di sfondo e del testo.
bd=0 e relief='flat': Rendono il bordo della casella piatto e senza spessore.
pack(padx=10, pady=10): Posiziona il widget nella finestra con un margine di 10 pixel.
3. Contenitore per l'Input dell'Utente
user_input_frame = tk.Frame(root, bg='white')
user_input_frame.pack(padx=10, pady=(0, 10))
tk.Frame: Crea un contenitore per raggruppare i widget di input e il pulsante di invio.
bg='white': Imposta il colore di sfondo del frame.
pack(padx=10, pady=(0, 10)): Posiziona il frame con un margine superiore di 0 e inferiore di 10 pixel.
4. Campo di Inserimento Testo
user_input = tk.Entry(user_input_frame, width=50, bg='white', fg='black', bd=1, relief='solid', highlightthickness=1, highlightbackground='#d9d9d9', highlightcolor='#4a90e2')
user_input.pack(side=tk.LEFT, padx=(0, 5), ipady=5, ipadx=5)
tk.Entry: Crea un campo per l'inserimento di testo da parte dell'utente.
width=50: Imposta la larghezza del campo di testo.
bd=1 e relief='solid': Definiscono un bordo sottile e solido.
highlightthickness, highlightbackground, highlightcolor: Configurano l'aspetto del bordo di evidenziazione.
pack(side=tk.LEFT, padx=(0, 5), ipady=5, ipadx=5): Posiziona il campo a sinistra del frame con un po' di padding.
5. Pulsante di Invio
send_button = tk.Button(user_input_frame, text="Invia", command=send_message, bg='black', fg='white', activebackground='#333333', activeforeground='white', bd=0, padx=10, pady=5, relief='flat')
send_button.pack(side=tk.RIGHT)
tk.Button: Crea un pulsante etichettato "Invia".
command=send_message: Associa il pulsante alla funzione send_message che verrà eseguita al click (nota: questa funzione non è definita nel codice fornito).
bg e fg: Definiscono i colori di sfondo e del testo del pulsante.
activebackground e activeforeground: Colori quando il pulsante è attivo.
bd=0 e relief='flat': Rendono il bordo del pulsante piatto e senza spessore.
pack(side=tk.RIGHT): Posiziona il pulsante a destra del frame.
Per avviare l'interfaccia viene utilizzata la funzione main():
def main():
root.mainloop()
L'immagine seguente mostra coma appare la GUi del Chatbot in esecuzione:
COME INVIARE LE RICHIESTE AL SERVER OLLAMA
1. Dichiarazione della Funzione e Variabili Globali
La funzione send_message gestisce l'invio di un messaggio dell'utente alla chatbot e visualizza la risposta generata da Llama3 tramite Ollama.
def send_message():
global chat_history, chat_context
global chat_history, chat_context: Indica che le variabili chat_history e chat_context sono globali.
chat_history: Conserva l'intera cronologia della chat.
chat_context: Potrebbe essere utilizzata per mantenere il contesto tra le richieste (utile per i modelli di AI che gestiscono conversazioni complesse).
2. Lettura del Messaggio dell'Utente
user_message = user_input.get()
if user_message.strip() == "":
return
user_input.get(): Recupera il testo inserito dall'utente nel campo di input.
user_message.strip() == "": Controlla se il messaggio è vuoto o contiene solo spazi. Se sì, la funzione termina senza fare nulla (return).
3. Visualizzazione del Messaggio dell'Utente nella Chat
chat_log.insert(tk.END, f"You: {user_message}\n")
user_input.delete(0, tk.END)
chat_log.insert(tk.END, f"You: {user_message}\n"): Inserisce il messaggio dell'utente nella finestra di chat.
user_input.delete(0, tk.END): Pulisce il campo di input, pronto per un nuovo messaggio.
4. Aggiornamento della Cronologia della Chat
chat_history += f"You: {user_message}\n"
Aggiunge il messaggio dell'utente alla cronologia della chat, in modo che il modello abbia il contesto completo della conversazione.
5. Invio del Messaggio a Llama3 tramite Ollama
response, chat_context = get_llama3_response(chat_history, chat_context)
get_llama3_response(): Chiama una funzione (presumibilmente definita altrove) che:
Riceve la cronologia della chat e il contesto attuale.
Restituisce una risposta generata dal modello Llama3 e un nuovo contesto aggiornato.
response: La risposta generata da Llama3.
chat_context: Il contesto aggiornato che sarà utilizzato nelle conversazioni future.
6. Visualizzazione della Risposta del Modello
chat_log.insert(tk.END, f"Llama3: {response}\n")
Visualizza la risposta del modello nel registro della chat.
7. Aggiornamento Finale della Cronologia
chat_history += f"Llama3: {response}\n"
Aggiunge la risposta del modello alla cronologia per mantenere il contesto coerente nelle interazioni future.
COME GESTIRE LE RISPOSTE RICEVUTA DAL SERVER OLLAMA
La funzione get_llama3_response invia una richiesta POST all'API di Ollama per generare una risposta basata su un prompt e un contesto di conversazione. Gestisce anche lo streaming della risposta e aggiorna il contesto per le interazioni successive.
1. Argomenti della funzione
def get_llama3_response(prompt, context):
prompt: Il testo della conversazione, che include la cronologia dei messaggi.
context: Informazioni aggiuntive per mantenere la coerenza del dialogo (opzionale).
1. Preparazione del Payload
try:
payload = {"prompt": prompt, "model": "llama3"}
if context:
payload["context"] = context
payload: Un dizionario contenente i dati da inviare all'API.
"prompt": Il testo della conversazione fino a quel momento.
"model": "llama3": Specifica il modello da utilizzare.
Se il context è disponibile, viene aggiunto per aiutare il modello a mantenere la coerenza della conversazione.
2. Invio della richiesta POST all'API
response = requests.post(
"http://localhost:11434/api/generate",
json=payload,
stream=True
)
requests.post: Esegue una richiesta HTTP POST verso l'API locale di Ollama.
json=payload: Invia i dati della richiesta in formato JSON.
stream=True: Indica che la risposta verrà trasmessa in streaming, utile per ricevere i dati in tempo reale.
3. Gestione della Risposta
full_response = ""
final_context = None
full_response: Variabile per accumulare la risposta completa del modello.
final_context: Variabile per memorizzare il contesto aggiornato, se fornito.
4. Elaborazione della Risposta in Streaming
for line in response.iter_lines():
if line:
data = json.loads(line.decode('utf-8'))
full_response += data.get("response", "")
if data.get("done") and "context" in data:
final_context = data["context"]
response.iter_lines(): Itera sulle righe della risposta in streaming.
json.loads(): Converte ogni linea JSON in un dizionario Python.
data.get("response", ""): Estrae la parte di testo generata e la aggiunge a full_response.
data.get("done"): Verifica se la generazione della risposta è completata.
"context" in data: Se il contesto aggiornato è disponibile, lo salva in final_context.
5. Restituzione del Risultato
return full_response or "Nessuna risposta ricevuta.", final_context
Restituisce la risposta completa.
Se la risposta è vuota, ritorna un messaggio di default: "Nessuna risposta ricevuta.".
Fornisce anche il final_context aggiornato.
6. Gestione degli Errori
except Exception as e:
return f"Errore di connessione: {e}", context
Se si verifica un errore (come problemi di connessione o di decodifica), viene restituito un messaggio di errore insieme al contesto originale.
Per visualizzare il codice Python completo della chatbot clicca qui.
Per eseguire il codice Python della chatbot, copialo e incollalo in Visual Studio Code.
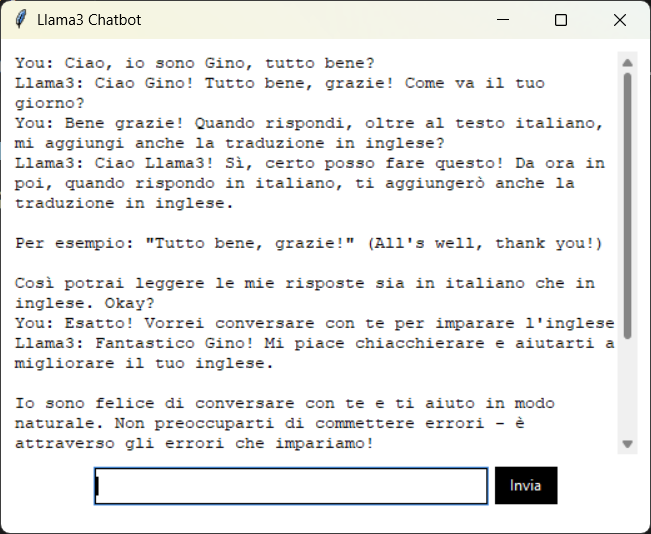
L'immagine seguente mostra un esempio di conversazione con Llama3, utilizzando la nostra chatbot:
Nel prossimo articolo vedremo un semplice esempio di fine tuning - no coding - per addestrare Llama3.
1.Intelligenza Artificiale: se la conosci non la temi
2.Intelligenza Artificiale: i modelli linguistici di grandi dimensioni
3.Intelligenza Artificiale: le reti neurali artificiali
4.Intelligenza Artificiale: tipi di reti neurali artificiali
5.Intelligenza Artificiale: IA Generativa
6.Intelligenza Artificiale: modelli pre-addestrati di IA locali
8.Intelligenza Artificiale: come addestrare LLAMA3 attraverso un Fine-Tuning di tipo no coding
9.Intelligenza Artificiale: cosa dobbiamo sapere su ai act e deepfake
10.Intelligenza Artificiale: Cosa cambia nel mondo del lavoro
2.La filiera della Formazione Professionale in Europa e in Italia
![]() Gino Visciano |
Skill Factory - 16/02/2025 20:36:36 | in Home
Gino Visciano |
Skill Factory - 16/02/2025 20:36:36 | in Home
 La filiera della formazione professionale offre ai giovani l'opportunità di apprendere le competenze essenziali che favoriscono lo sviluppo personale, migliorano le prospettive professionali e incoraggiano la cittadinanza attiva. Inoltre favorisce il rendimento delle imprese, la competitività, la ricerca e l'innovazione.
La filiera della formazione professionale offre ai giovani l'opportunità di apprendere le competenze essenziali che favoriscono lo sviluppo personale, migliorano le prospettive professionali e incoraggiano la cittadinanza attiva. Inoltre favorisce il rendimento delle imprese, la competitività, la ricerca e l'innovazione.
La filiera della formazione professionale, può essere divisa in IFP-I (istruzione e la formazione professionale iniziale), IFP-S (Formazione Superiore) e IFP-C (formazione continua o permanente).
L'istruzione e la formazione professionale iniziale (IFP-I) viene in genere impartita a livello di istruzione secondaria superiore o di IeFP, mentre la formazione superiore (IFP-S) viene impartita dopo il conseguimento di un diploma professionale o tecnico, prima dell'ingresso nel mondo del lavoro. La formazione superiore viene erogata attraverso percorsi IFTS o ITS e prevede un apprendimento teorico/partico per questo motivo è fondamentale la collaborazione tra centri di formazione e imprese.
In media il 50% dei giovani europei tra i 15 e i 19 anni segue un corso di istruzione e formazione professionale iniziale a livello di istruzione secondaria superiore. Tuttavia, la media dell'UE cela notevoli differenze geografiche nei tassi di partecipazione, che vanno dal 15% a oltre il 70%.
L'istruzione e la formazione professionale continua o permanente (IFP-C) inizia dopo l'ingresso nel mondo del lavoro. Ha l'obiettivo di perfezionare le conoscenze e di aiutare i cittadini ad acquisire nuove competenze, a riqualificarsi e a proseguire lo sviluppo personale e professionale. È principalmente basata sul lavoro.
In Europa l'acronimo che fa riferimento all'istruzione e alla formazione professionale è VET (Vocation Education and Training), che si articola in fomazione iniziale IVET (Initial Vocational Education and Training), formazione superiore HVET (Higher Vocational Education and Training) e fomazione continua CVET (Continuing Vocational Education and Training).
IL QUADRO EUROPEO DELLE QUALIFICAZIONI (EQF)
 In Europa, prima del 2008, ogni nazione utilizzava un proprio sistema di formazione e qualifica. Con l'obiettivo di favorire la mobilità dei cittadini, le pari opportunità e un adeguato livello di formazione permanente, nel 2008 è stato creato l'EQF.
In Europa, prima del 2008, ogni nazione utilizzava un proprio sistema di formazione e qualifica. Con l'obiettivo di favorire la mobilità dei cittadini, le pari opportunità e un adeguato livello di formazione permanente, nel 2008 è stato creato l'EQF.
L'EQF (European Qualifications Framework) è il quadro europeo delle qualificazioni, nasce allo scopo di comparare il livello d'istruzione e il livello di qualifica professionale degli studenti e dei lavoratori di tutta l'Europa.
Il Centro europeo per lo sviluppo della formazione professionale (Cedefop) e la Fondazione europea per la formazione (ETF), in quanto agenzie europee, svolgono un ruolo importante nel sostenere l'attuazione dell'EQF.
In Italia l'EQF è conosciuto come Quadro nazionale delle qualificazioni (QNQ), rappresenta il dispositivo nazionale che favorisce le attività per rendere comparabili i livelli di studio e le qualifiche professionali degli studenti e dei lavoratori italiani, con quelli delle altre nazioni europee.
In linea con il quadro europeo delle qualifiche (EQF) , il QNQ si sviluppa su tre dimensioni:
1) conoscenze
2) abilita'
3) autonomia e responsabilita'.
Attraverso queste tre dimensioni si può descrivere il tipo di competenza che bisogna avere per raggiungere uno degli 8 livelli di qualificazione EQF, dove il livello 1 è il più basso e l'8 è il più alto.
Per i giovani che seguono i percorsi di formazione professionale o di alta formazione professionale è importante capire alla fine di ogno percorso seguito qual è il livello di EQF che si ottiene.
IL SETTORE ECONOMICO PROFESSIONALE
Il Settore Economico Professionale (SEP), nel contesto dell'European Qualifications Framework (EQF), rappresenta il repertorio delle qualifiche professionali organizzato per aree economiche e professionali.
Il SEP è utile perché:
1. Permette ai lavoratori e agli studenti di capire quali competenze sono richieste in un determinato settore economico e professionale e qual è livello EQF corrispondente.
2. Serve per la creazione di percorsi formativi mirati
3. Facilita il riconoscimento delle qualifiche in altri paesi europei.
Per accedere al "Repertorio dei Titoli e delle Qualifiche" della regione Campania clicca qui.
L'ATTLANTE DEL LAVORO E DELLE QUALIFICAZIONI
Per avere una mappa dettagliata del lavoro e delle qualificazioni, del nostro Sistema nazionale di certificazione delle competenze, è possibile consultare l'ATLANTE DEL LAVORO E DELLE QUALIFICAZIONI.
L'Atlante nasce dal lavoro di ricerca condotto dall'INAPP (Istituto Nazionale Per l'Analisi delle Politiche Pubbliche), con la partecipazione di diversi soggetti istituzionali, delle parti datoriali e sindacali, delle rappresentanze bilaterali, delle associazioni professionali, degli esperti settoriali e degli stakeholder del sistema lavoro-learning.
Per accedere all'ATLANTE DEL LAVORO E DELLE QUALIFICAZIONI, clicca qui.
In Italia la filiera della formazione professionale è organizzata in:
1. IeFP
2. IFTS
3. PAR GOL
4. ITS.

Per IeFP s'intende "Istruzione e Formazione Professionale", si tratta di istruzione e formazione su competenze specifiche di tipo professionale e tecnico.
Per i giovani gli IeFP sono un'opportunità, perché preparano al mondo del lavoro e ne sviluppano le competenze affinché possano mantenere le loro possibilità di collocamento e rispondere ai cambiamenti del mercato.
Tra i settori in cui l’IeFP è particolarmente diffuso figurano quello alberghiero e della ristorazione, della distribuzione, dell’ingegneria, della contabilità e del lavoro d’ufficio. Anche gli apprendistati e i tirocini svolti all’interno di imprese o organizzazioni possono essere classificati come IeFP, giacché forniscono alle persone le competenze necessarie per eccellere in un settore specifico.
Le scuole o enti professionali di tipo IeFP prevedono i percorsi seguenti:
- percorsi triennali finalizzati al conseguimento della Qualifica professionale di Operatore;
- percorsi quadriennali, senza uscita al terzo anno, finalizzati al conseguimento del Diploma professionale di Tecnico;
- percorsi di quarto anno successivi al conseguimento di una qualifica professionale, finalizzati al conseguimento del Diploma professionale di Tecnico.
Il sistema regionale di Istruzione e Formazione Professionale (IeFP) è uno dei canali per l'assolvimento dell'obbligo di istruzione e del diritto-dovere all'istruzione e alla formazione stabiliti dalla legge.
Con la complessiva riforma della scuola superiore il sistema di IeFP regionale è stato pienamente riconosciuto nell'ambito del secondo ciclo di istruzione ed i titoli rilasciati sono validi - al pari di quelli scolastici - su tutto il territorio nazionale, poiché fanno riferimento a repertori di figure professionali e a standard di competenze concordati a livello nazionale tra tutte le Regioni e lo Stato.
 L'offerta di percorsi di IeFP è assicurata sul territorio regionale dalle istituzioni formative accreditate e dalle istituzioni scolastiche superiori statali e paritarie, nonché dalle imprese nel caso dei percorsi formativi rivolti ai loro apprendisti.
L'offerta di percorsi di IeFP è assicurata sul territorio regionale dalle istituzioni formative accreditate e dalle istituzioni scolastiche superiori statali e paritarie, nonché dalle imprese nel caso dei percorsi formativi rivolti ai loro apprendisti.
Dal punto di vista didattico-organizzativo consentono ampi spazi di flessibilità e di personalizzazione offrendo, in tal modo, agli allievi la possibilità di raggiungere le competenze attese secondo le capacità, i livelli di maturazione e gli stili di apprendimento individuali.
Pur assicurando una adeguata formazione culturale di base, possiedono un carattere meno teorico dei percorsi scolastici, in quanto privilegiano l'apprendimento in contesti pratici (laboratorio); inoltre, a partire dal 2° anno (e comunque dopo il 15° anno di età) sono previsti periodi di stage obbligatori presso le imprese.
Non esistono quadri orari generali delle discipline ma devono essere comunque garantite percentuali minime e massime di monte ore dedicato sia all'area delle competenze di base sia all'area delle competenze tecnico-professionali; hanno una durata annuale minima di 990 ore.
Gli IeFP consentono già al termine del 3° anno il diretto inserimento professionale e la spendibilità, nel mondo del lavoro, delle certificazioni e dei titoli acquisiti.
I percorsi di qualifica della IeFP hanno la durata di 3 anni a conclusione dei quali gli studenti sostengono un esame finalizzato ad acquisire l'attestato di qualifica professionale di terzo livello EQF.
Tale titolo consente di accedere ad un quarto anno (non obbligatorio) che offre la possibilità di migliorare la preparazione professionale e di conseguire il "diploma professionale" di quarto livello EQF.
E' inoltre possibile rientrare nel sistema scolastico (in particolare nel sistema dell'Istruzione Professionale) per ottenere un diploma di scuola secondaria superiore, previa verifica da parte dell'istituzione scolastica del livello di preparazione dell'allievo ai fini del suo inserimento nella classe adeguata.
La stessa opportunità è riconosciuta agli studenti del sistema di istruzione che intendano passare al sistema di IeFP.
I percorsi di IeFP prevedono risultati di apprendimento sia di carattere generale (competenze culturali di base, comuni a tutti i percorsi di qualifica/diploma professionale) sia di carattere professionale (competenze tecnico-professionali specifiche previste per ciascun percorso di qualifica e di diploma professionale) ed hanno le seguenti caratteristiche:
1. sono declinati in termini di competenza, intesa come comprovata capacità di utilizzare, in situazioni di lavoro, di studio o nello sviluppo professionale e personale, un insieme strutturato di conoscenze e di abilità acquisite nei contesti di apprendimento formale, di apprendimento non formale o di apprendimento informale;
2. sono descritti e definiti secondo i criteri e le regole previsti da standard nazionali; recepiscono ed assicurano i saperi e le competenze sia degli assi culturali previsti per l'assolvimento dell'obbligo di istruzione (che garantiscono l'equivalenza formativa dei primi due anni di tutti i percorsi del secondo ciclo), sia degli standard nazionali.
I risultati di apprendimento attesi alla conclusione del percorso triennale riguardano, in generale, il raggiungimento di un livello di alfabetizzazione culturale necessario per inserirsi in modo consapevole nella vita sociale e lavorativa e di un grado di autonomia professionale sostanzialmente di tipo esecutivo che permette di realizzare le attività in modo corrispondente alle indicazioni ricevute e con le modalità più adeguate.
Gli esiti di apprendimento attesi al termine del quarto anno si caratterizzano, invece, per lo sviluppo di una maggiore riflessività e capacità di affrontare problematiche più ampie e per un maggiore approfondimento delle conoscenze professionali (per esempio: della microlingua tecnica o delle metodologie scientifiche specifiche di settore) che permettono di raggiungere un grado di autonomia più elevato nell'attività lavorativa e forme più avanzate di partecipazione sociale e civile, anche nell'ambito della comunità professionale di riferimento.
Sia le competenze di base sia quelle tecnico-professionali favoriscono, inoltre, lo sviluppo di risorse personali, sociali, di apprendimento e di imprenditorialità che concorrono al raggiungimento dei risultati di apprendimento e riguardano:
1. la capacità di lavorare con gli altri in maniera costruttiva, che presuppone la conoscenza dei codici di comportamento e delle norme di comunicazione generalmente accettati in ambienti e società diversi, nonché abilità quali, ad esempio: lavorare in gruppo, interagire e collaborare con gli altri, gestire i conflitti, negoziare, esprimere e comprendere punti di vista diversi, superare pregiudizi, accettare critiche costruttive, dimostrare empatia, assistere e aiutare i colleghi, essere tolleranti, gestire l'incertezza e lo stress, creare fiducia;
2. la capacità di gestire il proprio apprendimento e sviluppo professionale, che comporta la conoscenza dei diversi modi di sviluppare le competenze e delle diverse tipologie e metodi di apprendimento, nonché abilità quali, ad esempio: individuare le proprie capacità, essere consapevoli della necessità di sviluppo delle proprie competenze, organizzare il proprio apprendimento, riflettere criticamente e su se stessi, dimostrare curiosità e volontà di apprendere, cercare opportunità di apprendimento, formazione e carriera, gestire efficacemente il tempo e le informazioni, gestire la complessità e l'incertezza, sapersi concentrare, prendere decisioni, perseverare, valutare, individuare forme di orientamento e sostegno;
3. la capacità di agire in modo imprenditoriale ed innovativo, che comporta la conoscenza di principi etici e delle opportunità e difficoltà sociali ed economiche, nonchè abilità quali, ad esempio: pensare in modo strategico e creativo, riflettere in modo critico, risolvere problemi, prendere decisioni, accettare le responsabilità, essere consapevoli dei propri punti di forza e delle proprie debolezze, gestire l'incertezza e il rischio, esprimere spirito di iniziativa, perseverare nel raggiungimento degli obiettivi, motivare gli altri e valorizzare le loro idee;
4. la capacità di sviluppare e mantenere il proprio benessere fisico ed emotivo, che presuppone la conoscenza degli elementi che compongono mente, corpo e stili di vita salutari, nonchè abilità quali, ad esempio: porre attenzione al proprio benesse fisico ed emotivo, prevenire comportamenti a rischio, riconoscere e gestire cause ed effetti dello stress, gestire le incertezze, riflettere criticamente e su se stessi, gestire relazioni affettive nel rispetto di sé e degli altri.
Di seguito sono descritti i risultati di apprendimento relativi alle competenze culturali di base comuni ai percorsi triennali di qualifica professionale e ai percorsi di 4° anno di diploma professionale.
Competenze culturali di base dei percorsi triennali
Le competenze culturali di base comuni a tutti i percorsi di qualifica professionale di IeFP sono individuate in relazione agli ambiti delle competenze chiave per l'apprendimento permanente definite dall'Unione Europea e riguardano:
- competenze alfabetiche funzionali - comunicazione
- competenza linguistica
- competenze matematiche, scientifiche e tecnologiche
- competenze storico-geografico-giuridiche ed economiche
- competenza digitale
- competenza di cittadinanza.
Competenze culturali di base dei percorsi del quarto anno
Le competenze culturali di base comuni a tutti i percorsi di diploma professionale di IeFP sono individuate in relazione agli ambiti delle competenze chiave per l'apprendimento permanente definite dall'Unione Europea e riguardano:
- competenze alfabetiche funzionali - comunicazione
- competenza linguistica
- competenze matematiche, scientifiche e tecnologiche
- competenze storico-geografico-giuridiche ed economiche
- competenza digitale
- competenza di cittadinanza.

 Può accedere ai corsi IFTS chi possiede il Diploma di Istruzione Secondaria Superiore o il Diploma Professionale di tecnico conseguito nei percorsi di IeFP. Obiettivo finale del percorso è quello di formare figure professionali tecniche di livello medio-alto, oggi molto richieste dalle aziende che si mostrano attente alle innovazioni e sempre al passo con le nuove tecnologie.
Può accedere ai corsi IFTS chi possiede il Diploma di Istruzione Secondaria Superiore o il Diploma Professionale di tecnico conseguito nei percorsi di IeFP. Obiettivo finale del percorso è quello di formare figure professionali tecniche di livello medio-alto, oggi molto richieste dalle aziende che si mostrano attente alle innovazioni e sempre al passo con le nuove tecnologie.
Gli ulteriori requisiti, richiesti per partecipare ai percorsi IFTS, sono stabiliti dal bandi regionali di riferimento, approvato annualmente. I corsi IFTS hanno una durata che varia da 800 a 1000 ore. Sono suddivisi in 2 semestri e prevedono attività teoriche, pratiche e di laboratorio. In particolare, il tempo dedicato all’attività di tirocinio formativo e stage aziendale non può essere inferiore al 40% del monte ore complessivo del corso. I docenti che ti accompagnano questi percorsi sono esperti che provengono direttamente dal mondo del lavoro, con esperienza concreta nel settore professionale di riferimento.
I corsi IFTS rilasciano un Certificato di Specializzazione Tecnica Superiore (IV livello EQF) relativo all’indirizzo di studi scelto dal candidato.
Esistono diversi indirizzi, i quali possono cambiare da una regione all’altra. Ecco i principali:
- Manifattura e artigianato: per la realizzazione artigianale di prodotti Made in Italy
- Meccanica: per l’installazione e manutenzione di impianti, la progettazione industriale e la programmazione della produzione
- Edilizia: tecniche innovative per l’organizzazione e gestione dei cantieri
- Servizi commerciali: amministrazione economico-finanziaria
- Turismo e sport: promozione di prodotti e servizi turistici
- Cultura, informazione e tecnologie informatiche: progettazione e sviluppo di tecnologie informatiche, produzione multimediale e gestione database
Per conoscere i percorsi IFTS nella tua regione consulta il catalogo di riferimento.
 Possono accedere ai corsi PAR GOL:
Possono accedere ai corsi PAR GOL:- Beneficiari di sostegno al reddito;
- Persone che ricevono sostegno finanziario;
- Lavoratori fragili o vulnerabili;
- Lavoratori maturi (55 anni e oltre);
- Persone con esperienza lavorativa avanzata.
- Donne che si trovano in situazioni difficili.
- Persone con disabilità.
Il programma PAR GOL offre la possibilità di accedere a diversi corsi di formazione gratuiti, specificamente progettati per potenziare le competenze dei lavoratori, agevolarne la riqualificazione e favorire lo sviluppo del potenziale per l’inserimento o il reinserimento nel mercato del lavoro.
Questi corsi coprono una vasta gamma di settori e competenze, consentendo ai partecipanti di acquisire la abilità richieste dalle aziende. Oltre alla formazione gratuita, è prevista anche una indennità di partecipazione e il rilascio di una qualifica professionale europea (EQF), il livello della qualifica dipende dal corso professionale scelto.

Gli ITS sono scuole di eccellenza ad alta specializzazione tecnologica post diploma che permettono di conseguire il titolo di tecnico superiore. Sono espressione di una strategia fondata sulla connessione delle politiche d'istruzione, formazione e lavoro con le politiche industriali.
Le aree tecnologiche e le figure professionali di riferimento degli ITS Academy per la realizzazione dei percorsi formativi sono le seguenti:
- Efficienza energetica;
- Mobilità sostenibile;
- Nuove tecnologie della vita;
- Nuove tecnologie per il Made in Italy (articolata in cinque ambiti: Sistema agroalimentare, Sistema casa, Sistema meccanica, Sistema moda, Servizi alle imprese);
- Tecnologie innovative per i beni e le attività culturali/Turismo;
- Tecnologie della informazione e della comunicazione.
Possono accedere ai corsi, i giovani e gli adulti anche occupati in possesso di diploma di istruzione secondaria superiore e coloro che sono in possesso di un diploma quadriennale di istruzione e formazione professionale unitamente ad un certificato di specializzazione tecnica superiore conseguito all’esito di un corso IFTS della durata di almeno 800 ore.
I corsi sono biennali o triennali e sono articolati in semestri:
i corsi biennali di V livello EQF (quinto livello del Quadro europeo delle qualifiche per l’apprendimento permanente) hanno la durata di quattro semestri con almeno 1.800 ore di formazione. Al termine del corso e previo superamento delle prove e valutazioni finali viene conseguito il “diploma di specializzazione per le tecnologie applicate”;
 i corsi triennali di VI livello EQF (sesto livello del Quadro europeo delle qualifiche per l’apprendimento permanente) hanno la durata di sei semestri con almeno 3.000 ore di formazione. Al termine del corso e previo superamento delle prove e valutazioni finali viene conseguito il “diploma di specializzazione superiore per le tecnologie applicate”.
i corsi triennali di VI livello EQF (sesto livello del Quadro europeo delle qualifiche per l’apprendimento permanente) hanno la durata di sei semestri con almeno 3.000 ore di formazione. Al termine del corso e previo superamento delle prove e valutazioni finali viene conseguito il “diploma di specializzazione superiore per le tecnologie applicate”.
Entrambi i diplomi sono rilasciati dal Ministero dell’istruzione e del merito insieme all’“Europass diploma supplement”, hanno validità su tutto il territorio nazionale e costituiscono titolo valido per l’accesso ai pubblici concorsi.
Ogni semestre comprende ore di attività teorica, pratica e di laboratorio. L’attività formativa è svolta per almeno il 60 per cento del monte orario complessivo da docenti provenienti dal mondo del lavoro. Gli stage aziendali e i tirocini formativi sono obbligatori almeno per il 35 per cento della durata del monte orario complessivo e possono essere svolti anche all’estero.
Al termine del corso, gli allievi che vi sono ammessi sostengono le prove di verifica finale delle competenze acquisite.
Le prove sono tre e sono correlate all’area tecnologica, ambito e figura professionale di riferimento del percorso formativo:
1. una prova scritta;
2. una prova teorico pratica;
3. una prova orale .
La prova scritta consiste in un set di trenta domande a risposta chiusa a scelta multipla, di cui cinque volte a valutare le competenze di lingua straniera.
La prova teorico pratica concerne la trattazione di un problema tecnico scientifico e due quesiti a risposta sintetica.
La prova orale concerne la discussione di un progetto di lavoro – project work – sviluppato durante il tirocinio formativo e lo stage aziendale svolti all’interno dell’impresa.
Per il superamento delle prove di verifica finale è necessario conseguire almeno il punteggio minimo in ciascuna di esse.
La valutazione delle prove è effettuata dalla Commissione esaminatrice, composta da:
- un docente universitario o docente degli Istituti di Alta formazione artistica musicale e coreutica o ricercatore, con funzione di Presidente, designato dal Ministero dell’istruzione e del merito;
- un esperto di formazione professionale designato dalla Regione;
- un docente di discipline tecnico professionali di Istituto di scuola secondaria di secondo grado;
- due esperti del mondo del lavoro designati dal Comitato tecnico scientifico dell’ITS Academy, uno dei quali abbia svolto funzioni di tutoraggio nel corso di formazione e l’altro individuato nell’ambito dell’area professionale o imprenditoriale di riferimento della Fondazione.
Su richiesta degli allievi la Fondazione rilascia la certificazione delle competenze acquisite all’interno dei percorsi, comprese quelle acquisite nelle attività di tirocinio formativo e di stage aziendale, anche in caso di mancato completamento del percorso formativo o di mancato superamento delle prove di verifica finale.
CHE COSA FA LA UE NEL SETTORE DELL'IFP
 La cooperazione europea in materia di istruzione e formazione professionale risale al 2002 e al processo di Copenaghen. È stata ulteriormente rafforzata nel corso degli anni, ad esempio dal comunicato di Bruges e dalle conclusioni di Riga. L'istruzione e la formazione professionale sono state individuate come un settore prioritario per la cooperazione nell'ambito dell'iniziativa per lo spazio europeo dell'istruzione nel periodo 2021-2030.
La cooperazione europea in materia di istruzione e formazione professionale risale al 2002 e al processo di Copenaghen. È stata ulteriormente rafforzata nel corso degli anni, ad esempio dal comunicato di Bruges e dalle conclusioni di Riga. L'istruzione e la formazione professionale sono state individuate come un settore prioritario per la cooperazione nell'ambito dell'iniziativa per lo spazio europeo dell'istruzione nel periodo 2021-2030.
Il 24 novembre 2020 il Consiglio dell'UE ha adottato una raccomandazione relativa all'istruzione e formazione professionale (IFP) per la competitività sostenibile, l'equità sociale e la resilienza. La raccomandazione definisce i principi fondamentali per garantire che l'istruzione e la formazione professionale siano flessibili, in quanto capaci di adattarsi rapidamente alle esigenze del mercato del lavoro e di offrire opportunità di apprendimento di qualità sia ai giovani che agli adulti.
Nel panorama europeo gli studenti iscritti a percorsi di Istruzione e Formazione Professionale (IFP) sono complessivamente circa il 48% di che accedono alla Scuola secondaria di secondo grado.
LA CARTA DEI DIRITTI FONDAMENTALI DELL'UE
la Carta dei diritti fondamentali dell’Unione europea è un documento che riconosce l’istruzione e l’accesso alla formazione professionale e continua come un diritto fondamentale e sottolinea come gli obiettivi di sviluppo sostenibile delle Nazioni Unite prevedono entro il 2030 pari accesso per tutte le donne e tutti gli uomini a un’istruzione tecnica, professionale e terziaria, anche universitaria, che sia di qualità così da aumentare in modo consistente il numero dei giovani e degli adulti in possesso delle competenze tecniche e professionali necessarie a garantirne un adeguato inserimento lavorativo e a favorirne la capacità imprenditoriale.
I sistemi di istruzione e formazione professionale innovativi e di elevata qualità devono fornire alle persone – giovani ma anche adulte – competenze per il lavoro, lo sviluppo personale e la cittadinanza. Mettendoli in condizione di costruirsi un patrimonio personale di abilità, conoscenze e competenze ampio e articolato, che permette loro di adattarsi alle transizioni in atto nel contesto sociale e al mutare delle richieste nel mercato del lavoro. Ne è un esempio la duplice transizione digitale e verde in atto, con le ripercussioni sulla crescita economica e sullo sviluppo sociale che genera.
Ogni Paese membro dell’UE a livello nazionale deve impegnarsi a sviluppare l’IFP, introducendo una maggiore flessibilità e rafforzando le opportunità di apprendimento basate sul lavoro e sul miglioramento della qualità dei percorsi di studio.
Le indicazioni seguenti sono importanti per garantire la qualità degli IFP:
1. Essere agili nell’adattarsi ai cambiamenti del mercato del lavoro;
2. Mettere al centro la flessibilità e le opportunità di avanzamento. Questo aiuta a raggiungere un forte impegno e a rendere i percorsi IFP più interessanti, il che porta a una maggiore occupabilità;
3. Essere un motore di innovazione e crescita. La formazione IFP dovrebbe essere adattata e ampliata per promuovere l’apprendimento di competenze imprenditoriali, digitali e verdi;
4. Rappresentare una scelta attraente, basata su competenze moderne e digitalizzate e sull’offerta di formazione;
5. Promuovere le pari opportunità. I programmi IFP dovrebbero essere inclusivi e accessibili per gruppi vulnerabili;
6. Offrire modelli di formazione flessibili per contribuire a prevenire l’abbandono precoce degli studenti;
7. Essere sostenuti da una cultura di garanzia della qualità.
DICHIARAZIONE DI OSNABRÜCK RELATIVA ALL’ISTRUZIONE E ALLA FORMAZIONE PROFESSIONALE
Il 30 novembre 2020 i ministri incaricati dell’istruzione e della formazione professionale degli Stati membri, dei paesi candidati all’adesione all’Unione europea (UE), dei paesi dello Spazio economico europeo (SEE), e delle parti sociali europee e della Commissione europea, si sono riuniti a Osnabrück per concordare una nuova serie di azioni politiche in materia di istruzione e formazione professionale per il periodo 2021-2025 volte a integrare e concretizzare gli obiettivi strategici e la visione definiti nella raccomandazione del Consiglio relativa all’istruzione e formazione professionale per la competitività sostenibile, l’equità sociale e la resilienza. L’attuazione di tutti gli obiettivi e di tutte le azioni avverrà nella debita osservanza del principio di sussidiarietà e in conformità ai contesti nazionali di IFP.
La Dichiarazione di Osnabrück 2020 mira a rafforzare l’istruzione e formazione professionale in Europa per renderla più resiliente, innovativa e inclusiva, in linea con le sfide della digitalizzazione, della transizione verde e si fonda su quattro obiettivi principali:
Obiettivo 1: resilienza ed eccellenza tramite un’IFP di qualità, inclusiva e flessibile;
Obiettivo 2: istituzione di una nuova cultura dell’apprendimento permanente — Importanza di un’IFP continua e della digitalizzazione;
Obiettivo 3: sostenibilità, un filo verde nell’IFP;
Obiettivo 4: settore europeo dell’istruzione e della formazione e dimensione internazionale dell’IFP.
Clicca qui per scaricare il documento la dichiarazione di Osnabrück 2020.
Riferimenti
https://education.ec.europa.eu/
https://education.ec.europa.eu/it/education-levels/vocational-education-and-training/about-vocational-education-and-training
https://invalsiopen.it/ifp-uno-sguardo-verso-il-futuro/
https://www.dopolaterzamedia.provincia.cremona.it/it-it/istruzione-e-formazione-professionale-iefp/guida/53
https://www.regione.lombardia.it/wps/portal/istituzionale/HP/formazioneprofessionale/ifts-cosa-sono
https://lavoro.regione.campania.it/index.php/220-ifts/319-ifts-percorsi-di-istruzione-e-formazione-tecnica-superiore
https://www.mim.gov.it/tematica-its
https://www.skillbook.it/Blog/Details/2238
Approfondimenti:
6.L'Assicurazione della Qualità nell'IFP.
5.L'Etica della formazione come responsabilità professionale.
4 Buona Formazione: "Come assicurare la qualità della formazione".
3.La qualità della formazione inizia dal confronto.
1.Sei uno studente oppure un lavoratore? Scopri qual è il tuo livello di EQF.
Vuoi qualificarti per entrare nel modo del lavoro?
Presso la nostra Academy delle Professioni Digitali, con il programma PAR GOL puoi partecipare ai seguenti corsi di formazione gratuiti di 300 ore, con 90 ore di tirocinio aziendale:

2. Recati al Centro Per l'Impiego (CPI) di competenza per richiedere l'adesione al Programma GOL.
3. Comunica all'operatore del CPI il nome ed il codice identificativo del corso scelto.
Se hai bisogno di assistenza o informazioni ci puoi anche contattarci ai seguenti recapiti:
Telefono: 08118181361
Cellulare: 327 087 0141
E-mail: segreteria@skillfactory.it
oppure puoi prenotare un appuntamento presso la nostra sede al Centro Direzionale di Napoli E2 scala A 1° piano.
 FILTRI
FILTRI


 Offerte di Lavoro
Offerte di Lavoro
 Post più recenti
Post più recenti
-

Full Stack Developer
07/05/2026
-
1° MAGGIO: FESTA DEL LAVORO E DELLA FORMAZIONE
01/05/2026
-
Operatore Amministrativo Contabile
09/04/2026
-
Tecnico Programmatore: Il Profilo più richiesto dai giovani che frequentano la nostra Academy
17/03/2026
-
6.L'Assicurazione della Qualità nell'IFP
24/01/2026
-
Skill Factory 2025: Un anno di formazione tra "Innovazione (AI), Qualità (EQAVET) e Politiche Attive del Lavoro (PAR GOL)"
30/12/2025
-
10.Intelligenza Artificiale: cosa cambia nel mondo del lavoro
21/12/2025
-
5.L’etica della formazione come responsabilità professionale
13/12/2025
-
4.Buona Formazione: "Come assicurare la Qualità della Formazione"
06/12/2025
-
Corso gratuito di 60 ore per creare le competenze digitali fondamentali (DIGCOMP2.2)
25/09/2025