





-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-





 Scheda Azienda
Scheda Azienda Eventi formazione
Eventi formazione Offerta formativa
Offerta formativa Lavora con noi
Lavora con noi
 Richiedi informazioni
Richiedi informazioni
Skill Factory
Tutte le categorie
Excel delle meraviglie Lezione 9 - Come estrarre dati da un elenco
![]() Gino Visciano |
Skill Factory - 01/06/2020 20:56:58 | in Tutorials
Gino Visciano |
Skill Factory - 01/06/2020 20:56:58 | in Tutorials
Questa lezione è molto interessante perché imparerete ad estrarre dati da un Elenco, impostando criteri di selezione avanzati, per creare tabelle personalizzate.
Per svolgere questo tipo di attività, nel foglio di lavoro dovete creare tre aree.
1) Nella prima area dovete inserire l'elenco con i dati, come mostra l'immagine seguente:
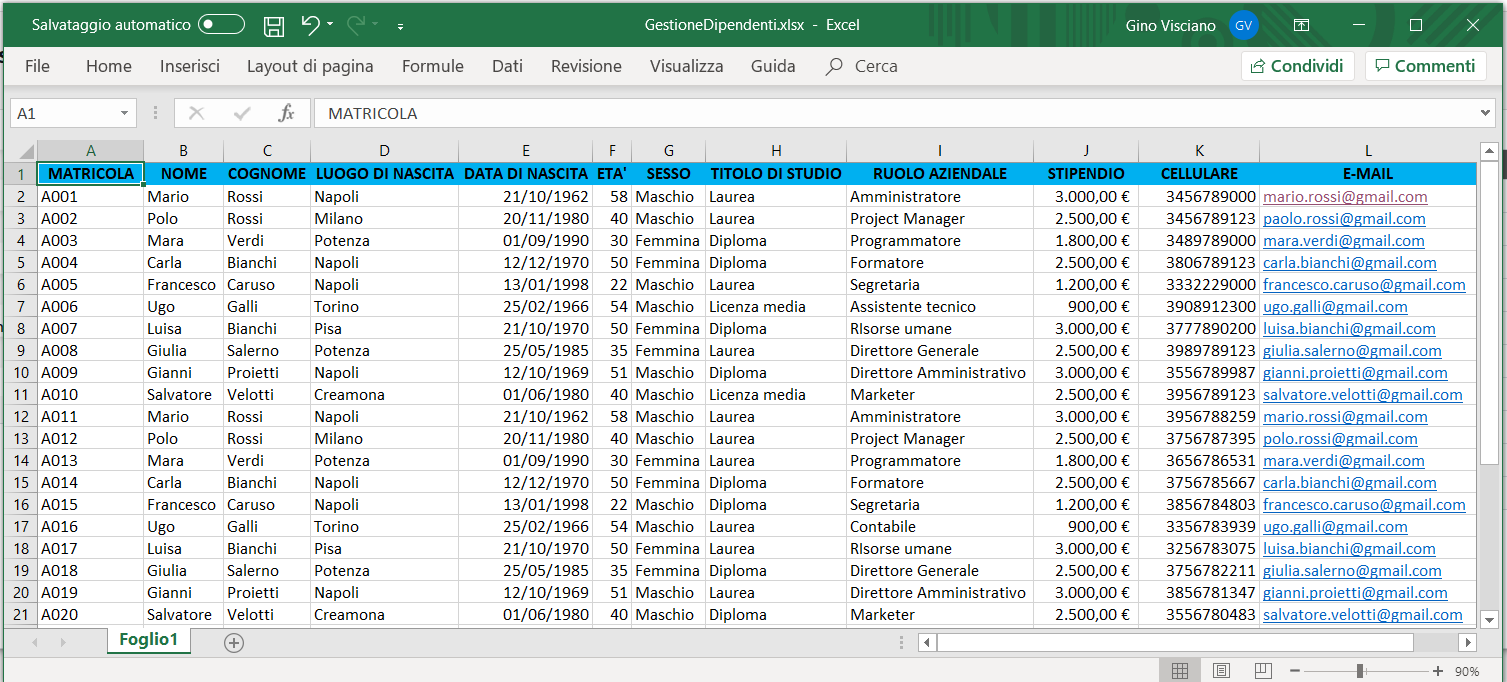
2) Nella seconda area dovete inserire i criteri di selezione, come mostra l'immagine seguente:

3) Nella terza area dovete inserire la tabella di estrazione, come mostra l'immagine seguente:

Attenzione, sotto le tre aree non dovete inserire nulla!
COME CREARE L'AREA DEI CRITERI
Per creare l'area dei CRITERI, procedete nel modo seguente:
1) nella cella P1 scrivete la parola CRITERI;
2) scegliete il menu Home;
3) selezionate le celle da P1 a X1;
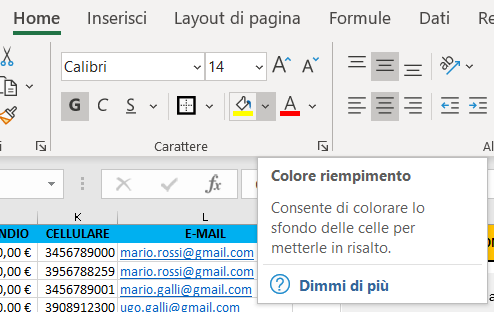
4) cliccate sul comando unisci e allinea al centro:

5) Successivamente impostate un colore a piacere, con il comando Colore riempimento;
Per completare l'area dei CRITERI, dovete impostare le colonne in cui inserire i valori da usare per la selezione. Per eseguire questa operazione, procedete nel modo seguente:
1) copiate le celle da A1 ad I1;
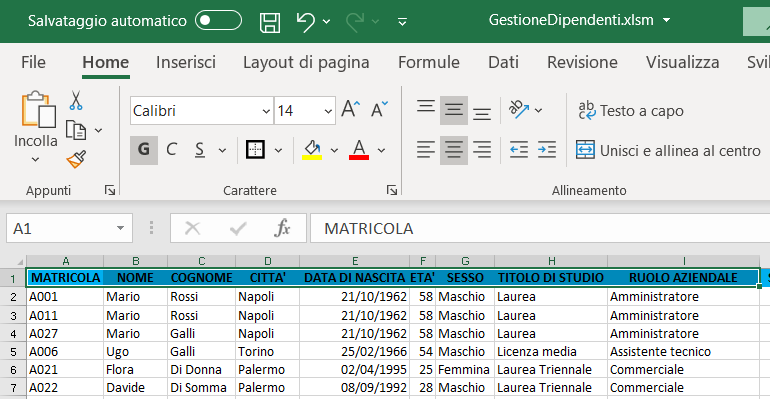
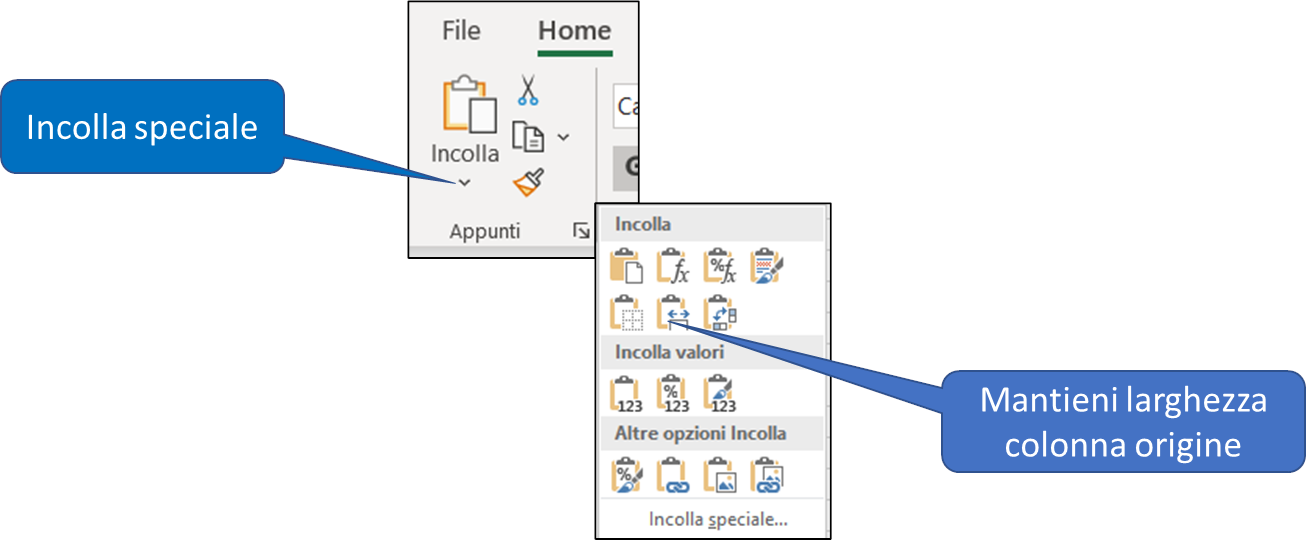
2) incollate le cella copiate nella cella P3, utilizzando il comando Incolla speciale (Mantieni larghezza colonna origine) come mostra l'immagine seguente:
COME CREARE L'AREA DI ESTRAZIONE
1) nella cella Z1 scrivete la parola ESTRAZIONE;
2) scegliete il menu Home;
3) selezionate le celle da Z1 ad AK1;
4) cliccate sul comando unisci e allinea al centro:
5) Successivamente impostate un colore a piacere, con il comando Colore riempimento;
Per completare l'area di ESTRAZIONE, dovete copiare tutte le colonne dell'elenco da A1 a L1 ed incollarle in Z3, con il comando Incolla speciale (Mantieni larghezza colonna origine) come mostra l'immagine seguente:
LABORATORIO 01
A. CREARE UNA TABELLA CON TUTTE LE DIPENDENTI LAUREATE
1) Inserite un nuovo foglio di lavoro, come indica l'immagine seguente:
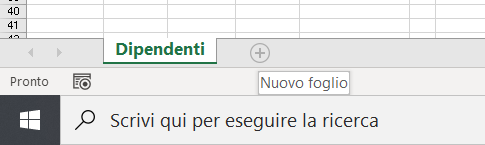
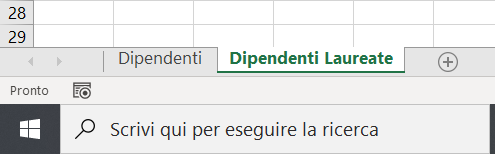
2) Doppio click sul nome del nuovo foglio ed inserite il nome Dipendenti Laureate, come mostra l'immagine seguente:
3) Nell'area dei criteri impostate la colonna Sesso=Femmina e Titolo di studio=Laurea, come mostra l'immagine seguente:

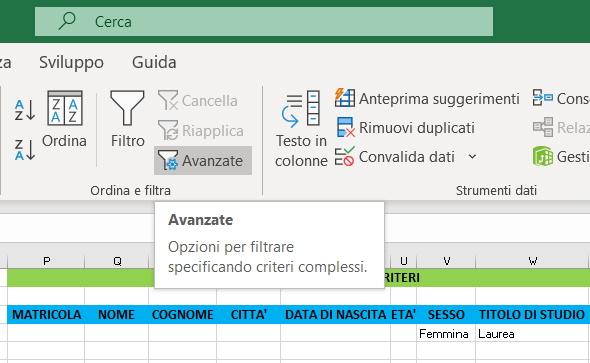
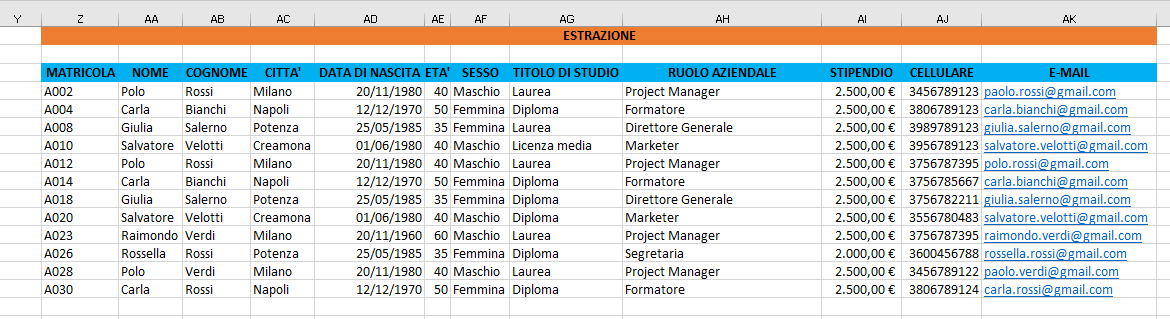
3) Posizionate il cursore nella cella A1, selezionate il menu Dati e cliccate sul comando Avanzate, come mostra l'immagine seguente:
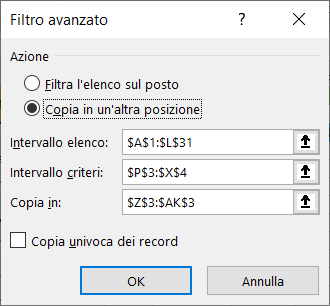
4) Nella scheda Filtro avanzato, selezionate l'opzione Copia in un'altra posizione ed inserite le coordinate dell'elenco, dell'area dei criteri, inclusa la riga in cui avete inserito le condizioni e dell'area di estrazione, includendo solo i nomi delle colonne, come mostra l'immagine seguente:
Per ottenere le coordinate delle tre aree potete anche usare il mouse. Cliccate sulla freccia a destra delle caselle di testo e selezionate con il mouse l'area corrispondente, come mostra l'immagine seguente:
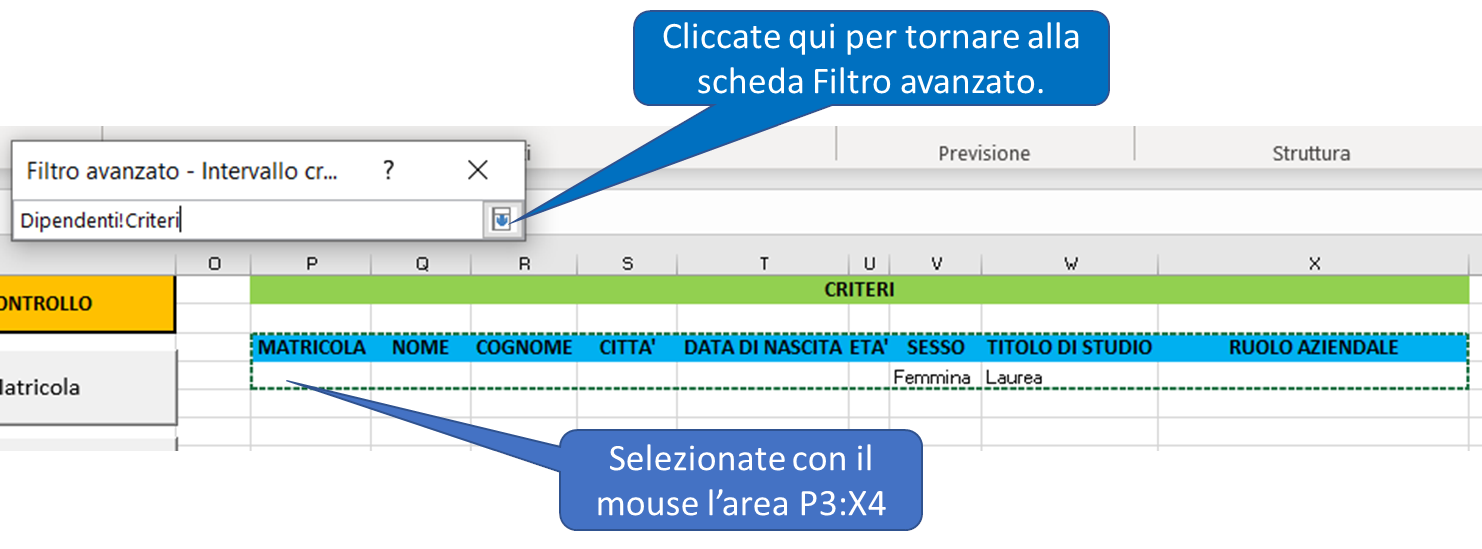
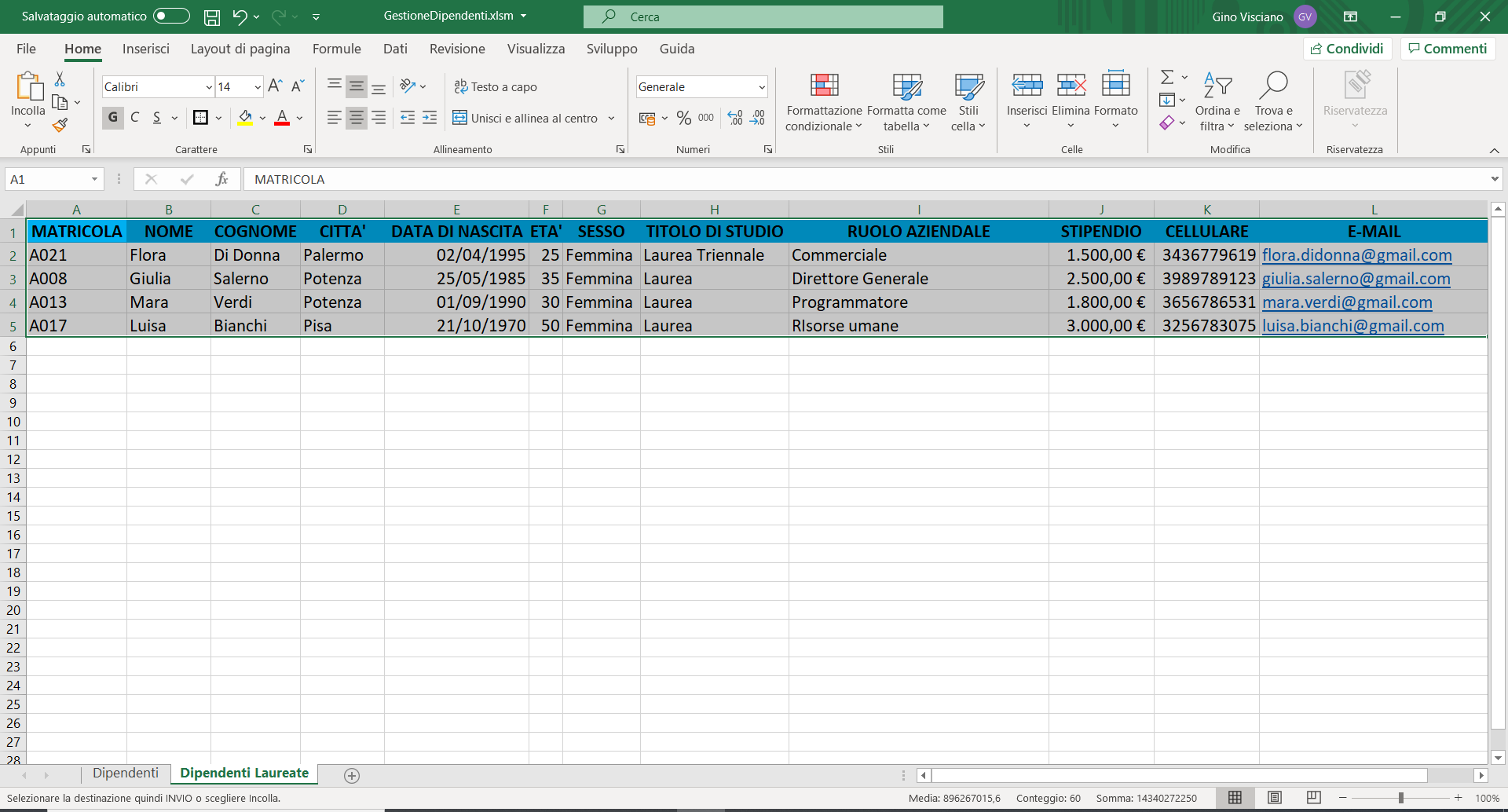
5) Per eseguire l'estrazione cliccate sul pulsante "OK". Tutti i dipendenti che soddisfano i criteri di selezione verranno aggiunti nell'area di estrazione, come mostra l'immagine seguente:

Per completare il laboratorio copiate tutta la tabella nel foglio di lavoro Dipendenti laureate, come mostra l'immagine seguente:
B. ESTRARRE TUTTI PROGRAMMATORI DIPLOMATI
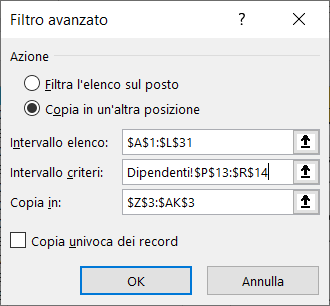
1) Nell'area dei criteri impostate la colonna Titolo di studio=Diploma e Ruolo aziendale=Programmatore, come mostra l'immagine seguente:

2) Posizionate il cursore nella cella A1, Selezionate il menu Dati e cliccate sul comando Avanzate;
3) Nella scheda Filtro avanzato, selezionate l'opzione Copia in un'altra posizione, controllate se le coordinate sono esatte e cliccate sul pulsante "OK", per estrarre i dati.

COME IMPOSTARE CRITERI PERSONALIZZATI AVANZATI
L'area dei CRITERI può contenere molte altre sezioni dove inserire condizioni per l'estrazione dei dati. Questa esigenza nasce quando volete applicare condizioni complesse che richiedono l'uso degli operatori logici AND ed OR.
Ricordate che se più condizioni sono associate da una logica AND il dato viene estratto se solo se tutte le condizioni sono vere.
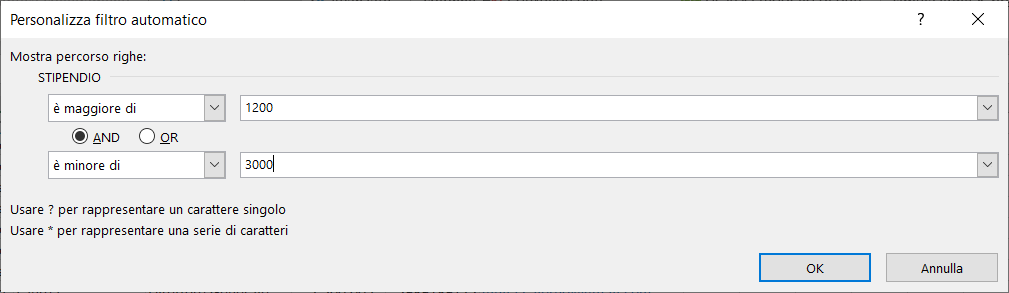
Ad esempio per estrarre tutti i dipendenti con uno stipendio maggiore di 1800,00 e minore di 3000,00 euro dovete utilizzare una logica AND, perché tutte è due le condizioni devono essere soddisfatte:
Stipendio>1800 AND Stipendio<3000.
In Excel per associare più condizioni con un operatore logico AND basta impostare le condizioni nel modo seguente:

Se più condizioni sono associate da una logica OR il dato viene estratto se almeno una delle condizioni è vera.
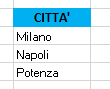
Ad esempio per estrarre i dipendenti di Milano, Napoli oppure Potenza dovete usare una logica OR, perché basta che almeno una delle condizioni sia esatta:
Città=Milano OR Città=Napoli OR Città=Potenza.
In Excel per associare più condizioni con un operatore logico OR basta impostare le condizioni nel modo seguente:
Potete anche associare tra loro più condizioni utilizzando contemporaneamente operatori logici AND ed OR. Ad esempio immaginate di voler estrarre dall'elenco i dipendenti di Milano, Napoli oppure Potenza, Programmatori e Laureati. Per ottenere questo risultato dovete applicare la condizione seguente:
(Città=Milano AND Titolo di studio=Laurea AND Ruolo Aziendale=Programmatore) OR (Città=Napoli AND Titolo di studio=Laurea AND Ruolo Aziendale=Programmatore) OR (Città=Potenza AND Titolo di studio=Laurea AND Ruolo Aziendale=Programmatore).
Questa condizione in Excel può essere impostata nel modo seguente:

LABORATORIO 02
A. ESTRARRE DALL'ELENCO TUTTI I DIPENDENTI CHE HANNO UNO STIPENDIO MAGGIORE DI €1800,00 E MINORE DI €3000,00
Per svolgere questo laboratorio, nell'area dei CRITERI dovete inserire la condizione seguente:
Per estrarre i dati, posizionate il cursore nella cella A1, selezionate il menu Dati e cliccate sul comando Avanzate.
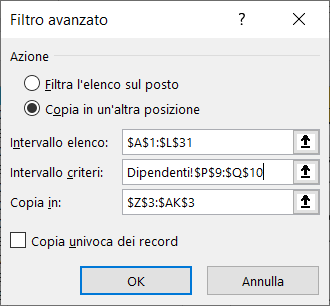
Nella scheda Filtro avanzato, selezionate l'opzione Copia in un'altra posizione ed inserite:
1) le coordinate dell'elenco;
2) le coordinate dell'area dei criteri che corrisponde alla condizione inserita;
3) le coordinate della riga d'intestazione nell'area di estrazione.
Alla fine cliccate sul pulsante "OK".
Le immagini seguenti mostrano le informazioni da inserire nella scheda Filtro avanzato ed il risultato dell'estrazione:
B. ESTRARRE DALL'ELENCO TUTTI I DIPENDENTI CHE HANNO UNO STIPENDIO MAGGIORE DI €1800,00 E MINORE DI €3000,00 E SONO FORMATORI
Per svolgere questo laboratorio, nell'area dei CRITERI dovete inserire la condizione seguente:

Per estrarre i dati, posizionate il cursore nella cella A1, selezionate il menu Dati e cliccate sul comando Avanzate.
Nella scheda Filtro avanzato, selezionate l'opzione Copia in un'altra posizione ed inserite:
1) le coordinate dell'elenco;
2) le coordinate dell'area dei criteri che corrisponde alla condizione inserita;
3) le coordinate della riga d'intestazione nell'area di estrazione.
Alla fine cliccate sul pulsante "OK".
Le immagini seguenti mostrano le informazioni da inserire nella scheda Filtro avanzato ed il risultato dell'estrazione:

C. ESTRARRE DALL'ELENCO TUTTI I DIPENDENTI CHE HANNO UNO STIPENDIO MAGGIORE DI €1800,00 E MINORE DI €3000,00 E SONO FORMATORI OPPURE PROJECT MANAGER
Per svolgere questo laboratorio, nell'area dei CRITERI dovete inserire la condizione seguente:

Per estrarre i dati, posizionate il cursore nella cella A1, selezionate il menu Dati e cliccate sul comando Avanzate.
Nella scheda Filtro avanzato, selezionate l'opzione Copia in un'altra posizione ed inserite:
1) le coordinate dell'elenco;
2) le coordinate dell'area dei criteri che corrisponde alla condizione inserita;
3) le coordinate della riga d'intestazione nell'area di estrazione.
Alla fine cliccate sul pulsante "OK".
Le immagini seguenti mostrano le informazioni da inserire nella scheda Filtro avanzato ed il risultato dell'estrazione:

D. ESTRARRE DALL'ELENCO TUTTI I DIPENDENTI DI MILANO, NAPOLI OPPURE POTENZA CHE SONO PROGRAMMATORI E LAUREATI
Per svolgere questo laboratorio, nell'area dei CRITERI dovete inserire la condizione seguente:
Per estrarre i dati, posizionate il cursore nella cella A1, selezionate il menu Dati e cliccate sul comando Avanzate.
Nella scheda Filtro avanzato, selezionate l'opzione Copia in un'altra posizione ed inserite:
1) le coordinate dell'elenco;
2) le coordinate dell'area dei criteri che corrisponde alla condizione inserita;
3) le coordinate della riga d'intestazione nell'area di estrazione.
Alla fine cliccate sul pulsante "OK".
Le immagini seguenti mostrano le informazioni da inserire nella scheda Filtro avanzato ed il risultato dell'estrazione:

COME ESTRARRE UNA COPIA UNIVICA DEI RECORD DA UN ELENCO
Due o più record sono uguali se contengono le stesse informazioni in tutte le colonne, la copia univoca dei record è La funzionalità che permette di estrarre da un elenco solo record distinti, eliminando i duplicati.
Nell'elenco seguente i record con matricola A001, A002 e A003 sono duplicati.

L'esempio seguente mostra la copia univoca dei record presenti nell'elenco precedente:

Questa funzionalità in Excel può essere applicata anche solo ad una o più colonne e questo permette di estrarre da un elenco informazioni molto utili.
Ad esempio, applicando la copia univoca dei record all'Elenco dei dipendenti, agendo solo su una o più colonne, è possibile estrarre, escludendo i duplicati, le seguenti informazioni:
1) Le città dei dipendenti;
2) I ruoli aziendali dei dipendenti;
3) I titoli di studio dei dipendenti.
Inoltre potreste confrontare gli stipendi dei dipendenti in relazione al loro ruolo aziendale oppure in relazione al ruolo aziendale, al titolo di studio ed al sesso.
LABORATORIO 03
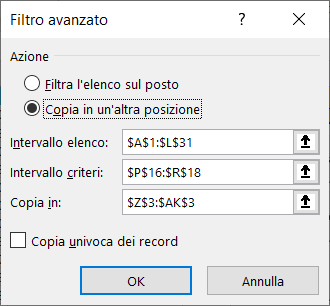
A. ESTRARRE DALL'ELENCO UNA COPIA UNIVOCA DELLE CITTA' DEI DIPENDENTI
1) Lasciando le intestazioni, pulite l'area dei CRITERI e l'area di ESTRAZIONE
2) Nell'area dei CRITERI, in corrispondenza della colonna CITTA' inserite come condizione un asterisco
3) Posizionate il cursore all'inizio dell'elenco dipendenti nella colonna matricola (cella A1)
4) Selezionate il menu Dati e cliccate sul comando Avanzate
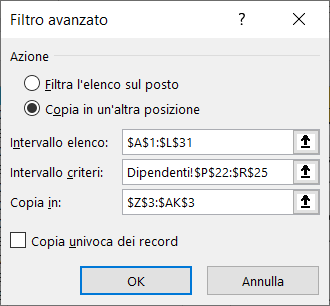
5) Nella scheda Filtro avanzato, selezionate l'opzione Copia in un'altra posizione ed inserite:
a) le coordinate dell'elenco;
b) le coordinate dell'area dei criteri che corrisponde alla colonna città e la cella in cui avete inserito l'asterisco;
c) le coordinate della colonna città nella riga d'intestazione nell'area di estrazione.
Alla fine, spuntate la voce Copia univoca dei record e cliccate sul pulsante "OK".
Le immagini seguenti mostrano le informazioni da inserire nella scheda Filtro avanzato ed il risultato dell'estrazione:

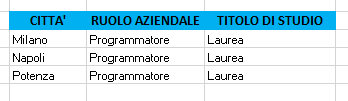
B. ESTRARRE DALL'ELENCO UNA COPIA UNIVOCA DEI RUOLI AZIENDALI DEI DIPENDENTI
1) Lasciando le intestazioni, pulite l'area dei CRITERI e l'area di ESTRAZIONE
2) Nell'area dei CRITERI, in corrispondenza della colonna RUOLO AZIENDALE inserite come condizione un asterisco
3) Posizionate il cursore all'inizio dell'elenco dipendenti nella colonna matricola (cella A1)
4) Selezionate il menu Dati e cliccate sul comando Avanzate
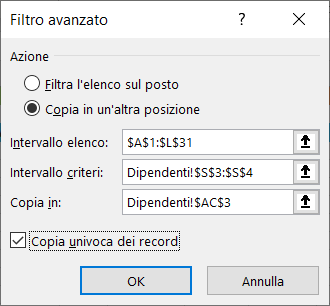
5) Nella scheda Filtro avanzato, selezionate l'opzione Copia in un'altra posizione ed inserite:
a) le coordinate dell'elenco;
b) le coordinate dell'area dei criteri che corrisponde alla colonna città e la cella in cui avete inserito l'asterisco;
c) le coordinate della colonna città nella riga d'intestazione nell'area di estrazione.
Alla fine, spuntate la voce Copia univoca dei record e cliccate sul pulsante "OK".
Le immagini seguenti mostrano le informazioni da inserire nella scheda Filtro avanzato ed il risultato dell'estrazione:
C. ESTRARRE DALL'ELENCO UNA COPIA UNIVOCA DEI TITOLI DI STUDIO DEI DIPENDENTI
1) Lasciando le intestazioni, pulite l'area dei CRITERI e l'area di ESTRAZIONE
2) Nell'area dei CRITERI, in corrispondenza della colonna TITOLO DI STUDIO inserite come condizione un asterisco
3) Posizionate il cursore all'inizio dell'elenco dipendenti nella colonna matricola (cella A1)
4) Selezionate il menu Dati e cliccate sul comando Avanzate
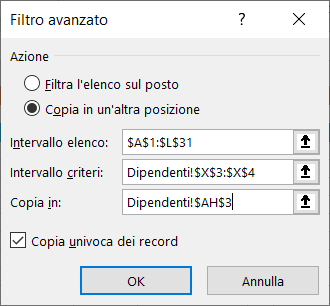
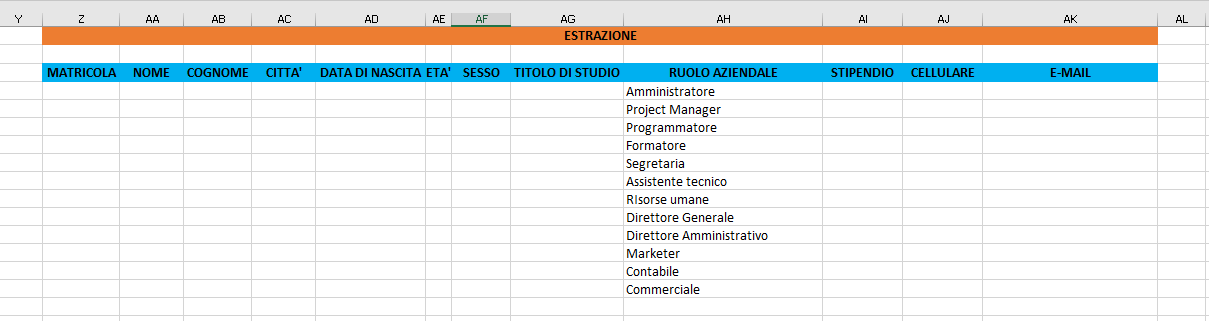
5) Nella scheda Filtro avanzato, selezionate l'opzione Copia in un'altra posizione ed inserite:
a) le coordinate dell'elenco;
b) le coordinate dell'area dei criteri che corrisponde alla colonna città e la cella in cui avete inserito l'asterisco;
c) le coordinate della colonna città nella riga d'intestazione nell'area di estrazione.
Alla fine, spuntate la voce Copia univoca dei record e cliccate sul pulsante "OK".
Le immagini seguenti mostrano le informazioni da inserire nella scheda Filtro avanzato ed il risultato dell'estrazione:
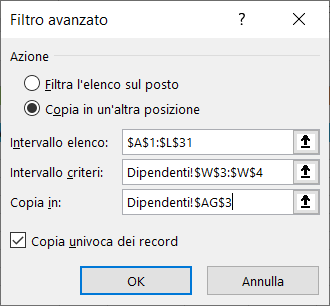

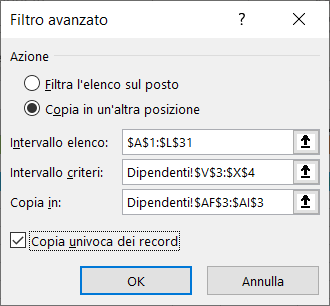
D. ESTRARRE DALL'ELENCO DEI DIPENDENTI UNA COPIA UNIVOCA DELLE SEGUENTI INFORMAZIONI: SESSO, TITOLI DI STUDIO, RUOLI AZIENDALI E STIPENDI
1) Lasciando le intestazioni, pulite l'area dei CRITERI e l'area di ESTRAZIONE
2) Nell'area dei CRITERI, in corrispondenza delle colonne SESSO, TITOLO DI STUDIO e RUOLO AZIENDALE inserite come condizione un asterisco
3) Posizionate il cursore all'inizio dell'elenco dipendenti nella colonna matricola (cella A1)
4) Selezionate il menu Dati e cliccate sul comando Avanzate
5) Nella scheda Filtro avanzato, selezionate l'opzione Copia in un'altra posizione ed inserite:
a) le coordinate dell'elenco;
b) le coordinate dell'area dei criteri che corrisponde alla colonna città e la cella in cui avete inserito l'asterisco;
c) le coordinate della colonna città nella riga d'intestazione nell'area di estrazione.
Alla fine, spuntate la voce Copia univoca dei record e cliccate sul pulsante "OK".
Le immagini seguenti mostrano le informazioni da inserire nella scheda Filtro avanzato ed il risultato dell'estrazione:
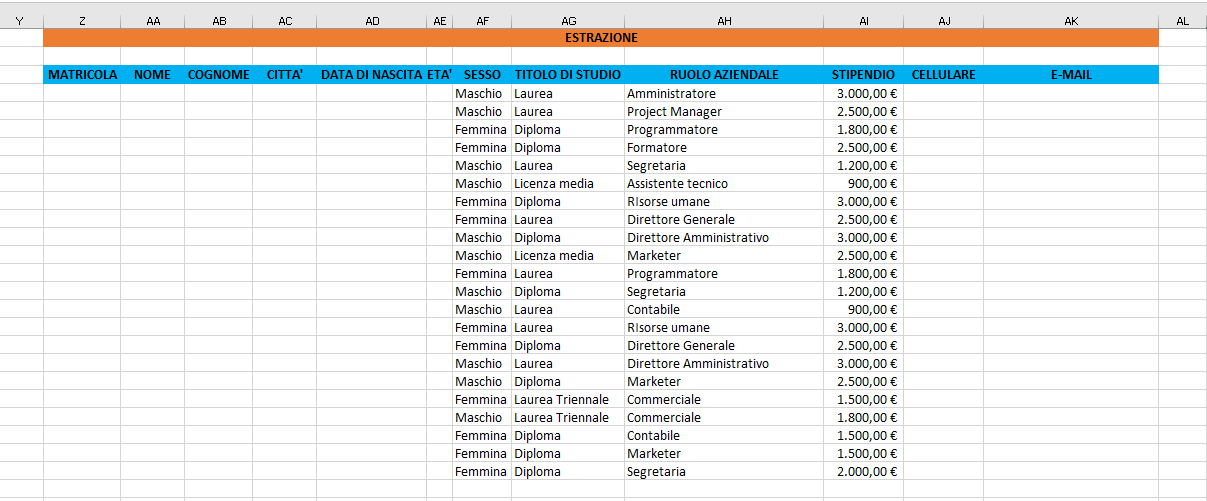
Nella prossima lezione imparerete a creare un cruscotto con informazioni statistiche per il supporto decisionale.
Per il download del file excel GestioneDipendenti.xlsx in formato zip clicca qui.
<< Lezione precedente Lezione successiva >> | Vai alla prima lezione
T U T O R I A L S S U G G E R I T I
- Impariamo Python giocando al "Solitario del ferroviere"
- Impariamo a programmare con JavaScript
- Laboratori di Logica di programmazione in C
- Introduzione alla Logica degli oggetti
- Ricominciamo ... dal Linguaggio SQL
- APP Mania
- Come sviluppare un Sito con Wordpress

Per informazioni e contatti: www.skillfactory.it
EDUCATIONAL GAMING BOOK (EGB) "H2O"
 Nell'era dello SMART LEARNING e di PYTHON i libri non si scrivono, ma si sviluppano, in questo modo chi studia, può sperimentare ed apprendere contemporaneamente; un libro con queste caratteristiche lo possiamo definire un Educational Gaming Book (EGB).
Nell'era dello SMART LEARNING e di PYTHON i libri non si scrivono, ma si sviluppano, in questo modo chi studia, può sperimentare ed apprendere contemporaneamente; un libro con queste caratteristiche lo possiamo definire un Educational Gaming Book (EGB).
"H2O" è un EGB che descrive tutte le caratteristiche dell'acqua, la sostanza formata da molecole di H2O, che attraverso il suo ciclo di vita garantisce la sopravvivenza di tutti gli esseri viventi del Pianeta.
L'obiettivo dell'EGB è quello di far conoscere ai giovani le proprietà dell'acqua, sotto molti aspetti uniche, per sensibilizzarli a salvaguardare un bene comune e raro, indispensabile per la vita.
Per il DOWNLOAD di "H2O" clicca qui.

Excel delle meraviglie Lezione 8 - Come lavorare con le Macro
![]() Gino Visciano |
Skill Factory - 28/05/2020 08:58:45 | in Tutorials
Gino Visciano |
Skill Factory - 28/05/2020 08:58:45 | in Tutorials
In questa lezione imparerete a lavorare con le Macro per automatizzare qualunque operazione fatta con il foglio elettronico.
Excel permette di creare applicazioni con il linguaggio Visual Basic, una Macro non è altro che la registrazione di tutti i comandi Visual Basic che servono per eseguire le operazioni richieste.
Per registrare una Macro dovete attivare il menu Sviluppo procedendo nel modo seguente:
1) Cliccate sul menu File in alto a sinistra;
2) Selezionate il comando Opzioni, che appare in basso a sinistra;
3) Nella scheda Opzioni di Excel, selezionate l'opzione Personalizzazione barra multifunzione;
4) Nella lista a destra aggiungete una spunta al menu Sviluppo, come mostra l'immagine seguente:
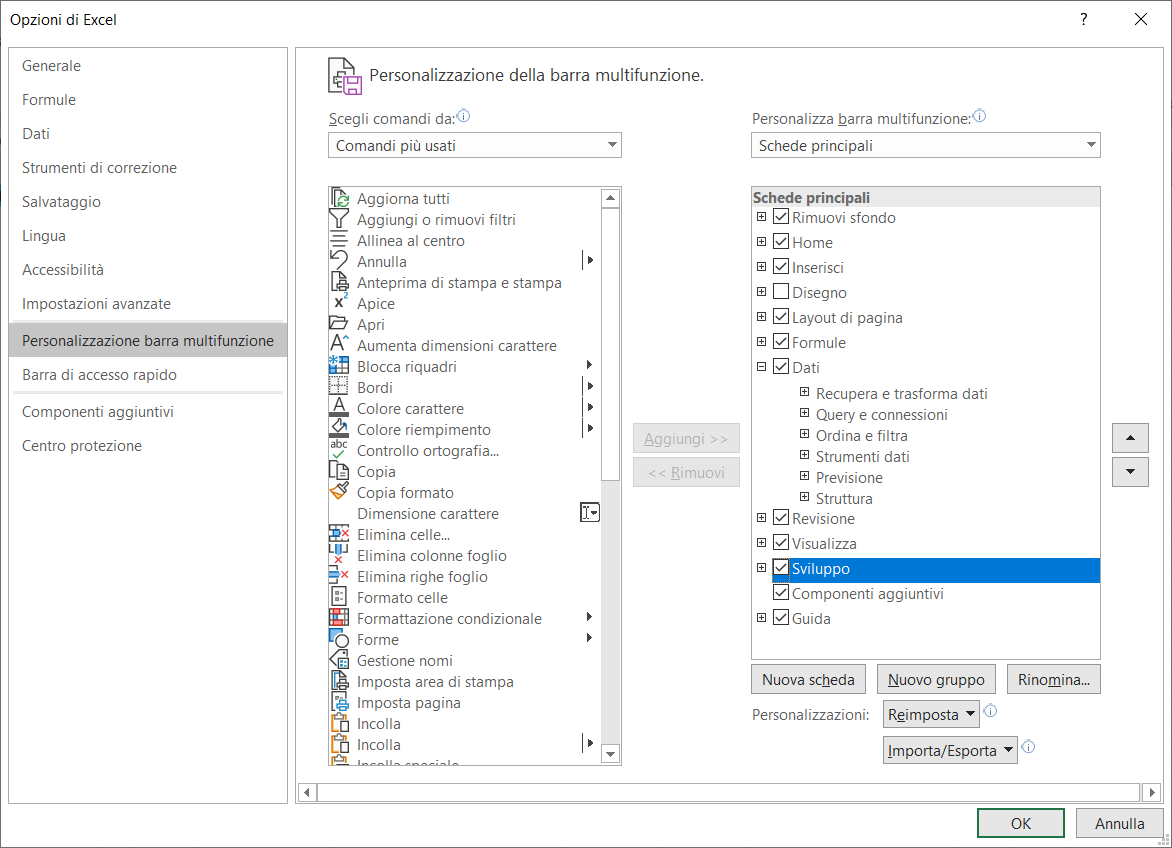
Dopo questa operazione tra le schede menu dovrebbe apparire la scheda Sviluppo, come mostra l'immagine seguente:

Nella prima sezione a sinistra trovate tutti i comandi per lavorare con le Macro.
COME REGISTRARE UNA MACRO
Prima di registrare una Macro dovete avere ben chiare tutte le operazioni che servono per svolgere l'attività richiesta, vi suggerisco di provare prima tutte le operazioni da associare alla Macro e solo successivamente procedere con la registrazione.
Nel nostro primo esempio, creiamo una Macro per ordinare l'elenco dei dipendeneti per Cognome, Nome ed Età:
1) Selezionate il menu Sviluppo e cliccate sul comando Registra macro, indicato nell'immagine seguente:

2) Nella scheda Registra macro inserite il nome della macro e come Tasto di scelta rapida inserite la lettera a, come mostra l'immagine seguente:
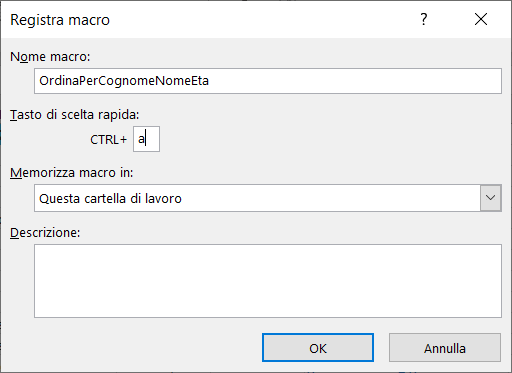
3) Per iniziare la registrazione cliccate sul pulsante OK.
Da questo momento in poi tutte le operazioni che farete verranno registrate dalla Macro, quindi attenti a non sbagliare, altrimenti dovrete cancellare la Macro e ripetere tutte le operazioni di nuovo.
Durante la registrazione per ordinare l'elenco dei dipendenti procedete nel modo seguente:
1) Posizionate il cursore sulla riga d'intestazione dell'elenco, nella prima colonna;
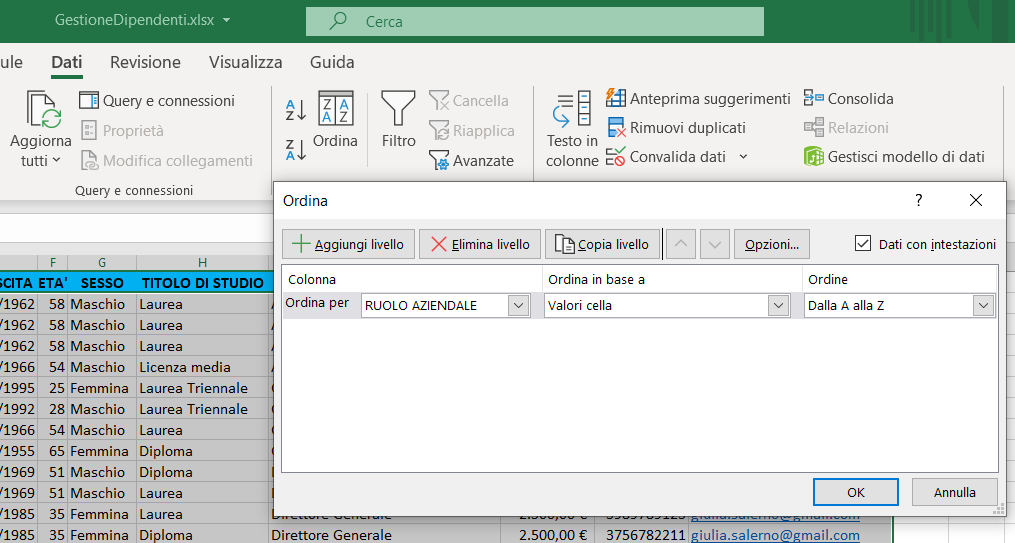
2) Selezionate il menu dati e cliccate sull'icona ordina, indicata di seguito:

3) Nella casella di selezione "Ordina per", scegliete la colonna cognome;
4) Successivamente per aggiungere anche le altre chiavi di ordinamento, usate il pulsante "+Aggiungi livello", come mostra l'immagine seguente:
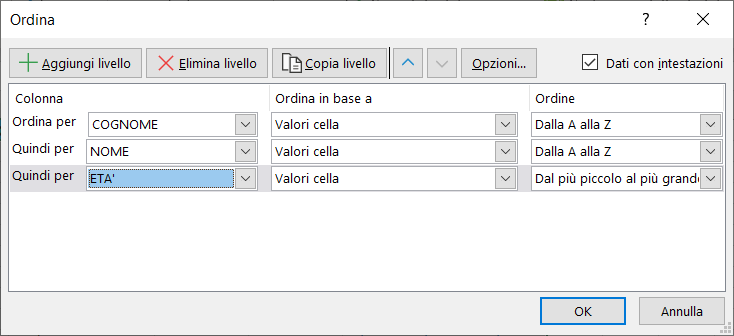
5) Per ogni chiave impostate l'ordine a destra ed infine cliccate sul pulsante "OK".
A questo punto potete interrompere la registrazione, selezionando di nuovo il menu Sviluppo e cliccando sul comando interrompi registrazione, indicato nell'immagine seguente:

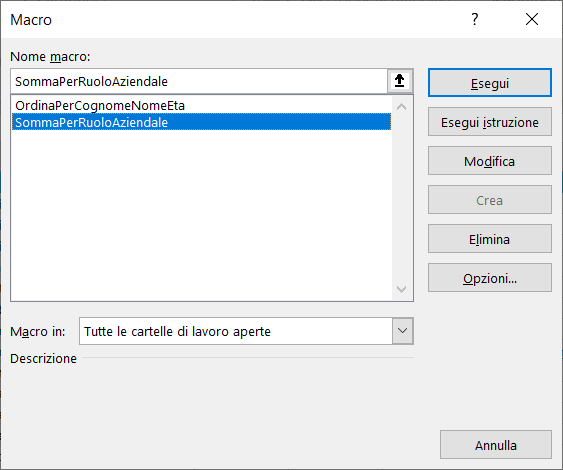
Per verificare se la Macro è stata registrata cliccate sul comando macro, indicato nell'immagine seguente:

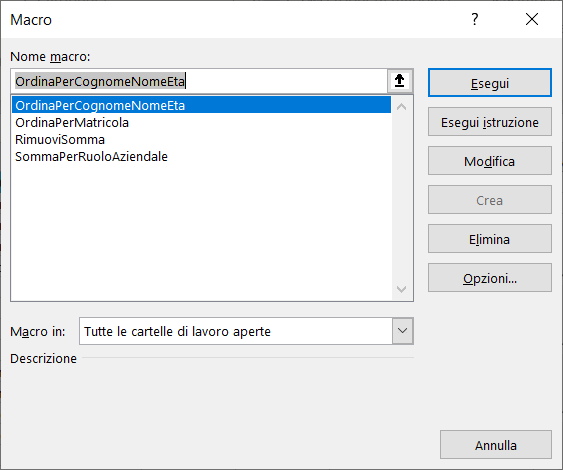
Viene visualizzata la scheda Macro che permette di gestire tutte le Macro create, ad esempio le potete sia eseguire, sia eliminare.
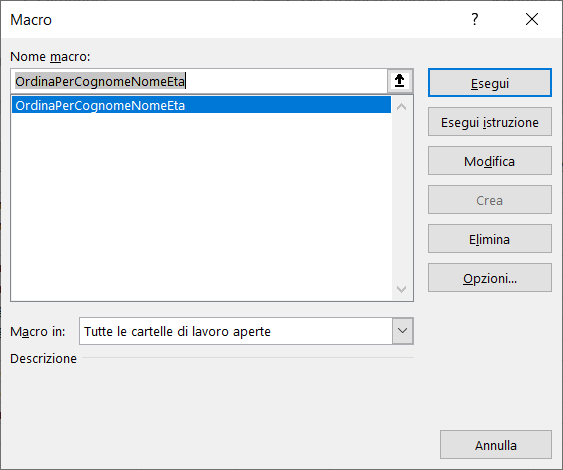
Per eseguire una Macro senza aprire la scheda Macro , potete usare i Tasti di scelta rapida, ad esempio per eseguire la Macro appena creata dovete premere contemporaneamente i tasti ctrl a.
Nel secondo esempio creiamo la Macro SommaPerRuoloAziendale.
1) Selezionate il menu Sviluppo e cliccate sul comando Registra macro:
2) Nella scheda Registra macro inserite il nome della macro e come tasto di scelta rapida inserite la lettera b, come mostra l'immagine seguente:
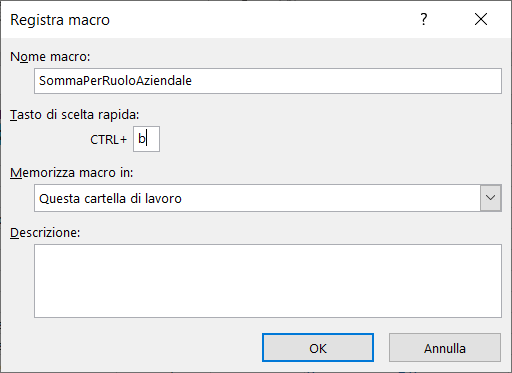
3) Per iniziare la registrazione cliccate sul pulsante OK.
Ricordate che da questo momento in poi qualunque operazione fate verrà registrata, quindi procedete nel modo seguente:

Per eseguire la Macro basta aprire la scheda Macro:
selezionarla e cliccare sul pulsante esegui come mostra l'immagine seguente:
Per eseguire la Macro appena creata, senza aprire la scheda Macro, potete usare i Tasti di scelta rapida ctrl b.
COME SALVARE UNA CARTELLA CHE CONTIENE MACRO
Per motivi di sicurezza, una cartella che contiene Macro bisogna salvarla nel formato "Cartella di lavoro con attivazione macro di Excel", come mostra l'immagine seguente:
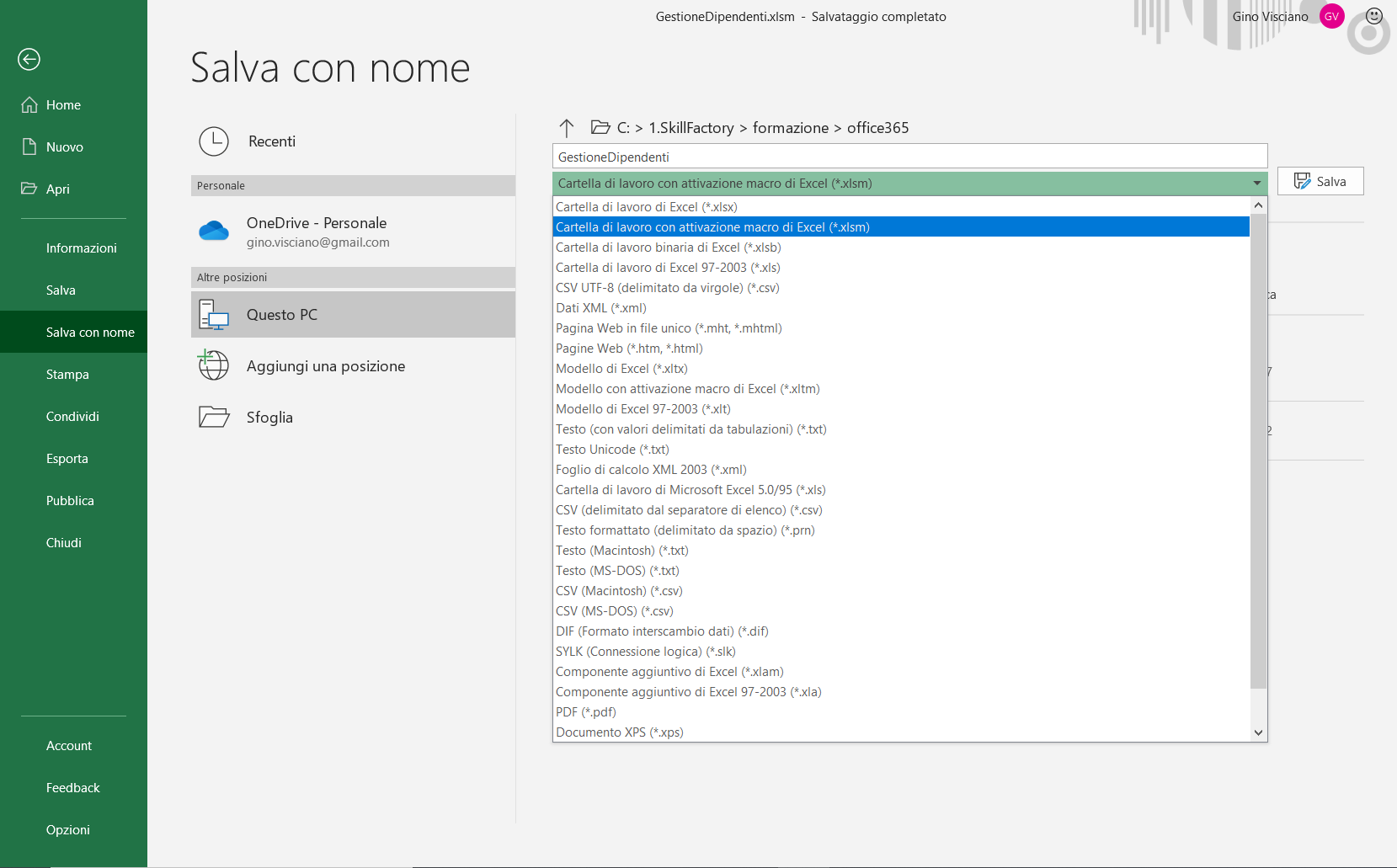
Un file che contiene Macro viene salvato con l'estension xlsm, a differenza di un file di Excel normale che ha l'estensione xlsx.
COME ASSOCIARE UNA MACRO AD UN PULSANTE

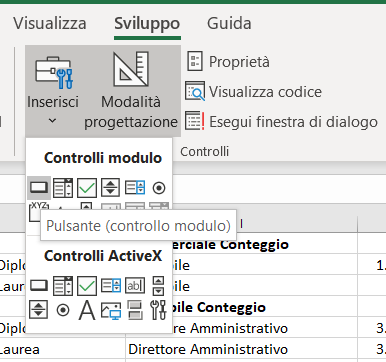
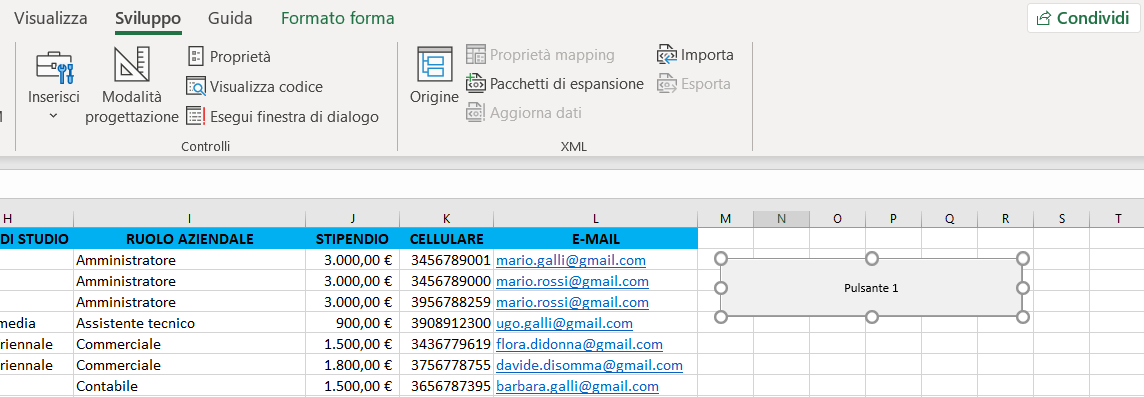
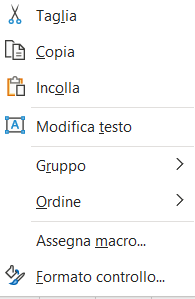
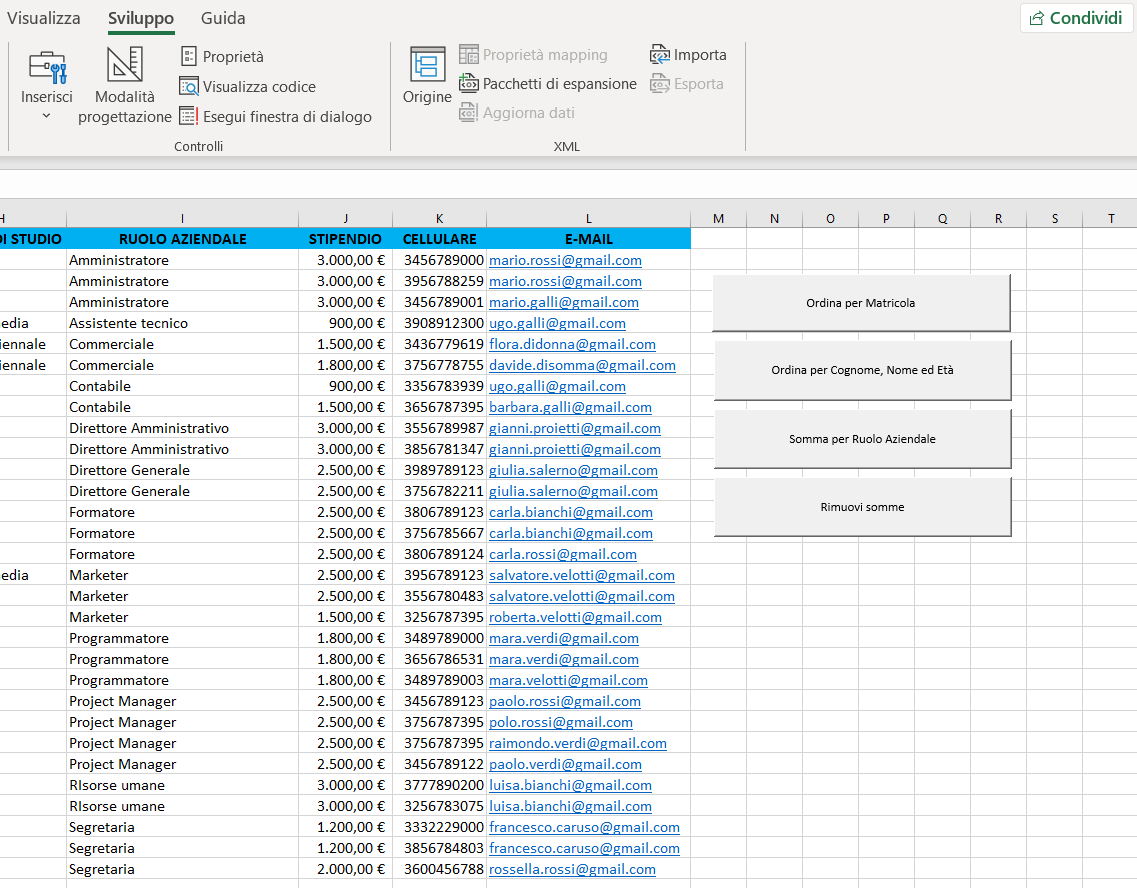
Per il download del file excel GestioneDipendenti.xlsm in formato zip clicca qui.
<< Lezione precedente Lezione successiva >> | Vai alla prima lezione
T U T O R I A L S S U G G E R I T I
- Impariamo Python giocando al "Solitario del ferroviere"
- Impariamo a programmare con JavaScript
- Laboratori di Logica di programmazione in C
- Introduzione alla Logica degli oggetti
- Ricominciamo ... dal Linguaggio SQL
- APP Mania
- Come sviluppare un Sito con Wordpress
EDUCATIONAL GAMING BOOK (EGB) "H2O"
Nell'era dello SMART LEARNING e di PYTHON i libri non si scrivono, ma si sviluppano, in questo modo chi studia, può sperimentare ed apprendere contemporaneamente; un libro con queste caratteristiche lo possiamo definire un Educational Gaming Book (EGB).
"H2O" è un EGB che descrive tutte le caratteristiche dell'acqua, la sostanza formata da molecole di H2O, che attraverso il suo ciclo di vita garantisce la sopravvivenza di tutti gli esseri viventi del Pianeta.
L'obiettivo dell'EGB è quello di far conoscere ai giovani le proprietà dell'acqua, sotto molti aspetti uniche, per sensibilizzarli a salvaguardare un bene comune e raro, indispensabile per la vita.
Per il DOWNLOAD di "H2O" clicca qui.
Dopo il lockdown, ripartono a Giugno 2 Skill Factory "Java Developer"! Formiamo 30 ragazzi da inserire presso i nostri partners di Napoli e Roma.
![]() Gino Visciano |
Skill Factory - 25/05/2020 19:52:46 | in Home
Gino Visciano |
Skill Factory - 25/05/2020 19:52:46 | in Home
 Sono aperte le iscrizione per 2 Skill Factory "Java Developer", l'obiettivo è quello di formare 30 programmatori junior da inserire a settembre presso i nostri partners di Napoli e Roma.
Sono aperte le iscrizione per 2 Skill Factory "Java Developer", l'obiettivo è quello di formare 30 programmatori junior da inserire a settembre presso i nostri partners di Napoli e Roma.
Una Skill Factory è un'esperienza professionale unica, che ti forma e ti trasmette tutta l'esperienza per entrare nel modo del lavoro. In modo concreto potrai apprendere le principali tecniche di programmazione, l'Object Oriented, UML ed il linguaggio SQL per progettare e gestire DBMS professionali come MySQL ed Oracle indispensabili per qualunque applicazione Java professionale. Imparerai a creare applicazione Web responsive con il framework Bootstrap ed utilizzerai Javascript e JQuery per inserire controlli di validazione. Durante il percorso di specializzazione finale realizzerai un vero E-Commerce, disegnato con il linguaggio UML e sviluppato con SPRING, il framwork per sviluppare applicazioni Java professionali più richiesto dalle aziende IT.
Una Skill Factory ha una durata di circa 40 giorni ed il 70% dei diplomati o laureati che partecipano ai nostri percorsi di specializzazione trovano lavoro presso uno dei nostri partners.
Le Skill Factory sono gratuite, perché sono sponsorizzate dai nostri partners IT che cercano risorse specializzate da inserire in azienda, possono accedere solo i giovani disoccupati, di età compresa tra i 19 e 32 anni, che danno la disponibilità ad entrare nel mondo del lavoro se completano il percorso con successo.
Per partecipare ad una Skill Factory è importante superare il test di ammissione, lo scopo del test è quello di verificare la predisposizione a svolgere il ruolo di programmatore.
Le attività didattiche e di laboratorio verranno svolte in modalità SMART LEARNING, attraverso TEAMS e Skillbook.it la nostra piattaforma di formazione in rete, dal lunedì al venerdì dalle 10,00 alle 12,00 e dalle 15,00 alle 17,00.
Se pensate di essere predisposti a svolgere il ruolo di programmatore e volete entrare al più presto nel mondo del lavoro, inviate il vostro cv all'indirizzo di posta: recruiting@skillfactory.it altrimenti registratevi su Skillbook e cliccate sul link:
Excel delle Meraviglie Lezione 7 - Come lavorare con un elenco di dati
![]() Gino Visciano |
Skill Factory - 13/05/2020 00:18:01 | in Tutorials
Gino Visciano |
Skill Factory - 13/05/2020 00:18:01 | in Tutorials
In questa lezione imparerete a lavorare con un elenco di dati utilizzando i comandi del menu Dati.
Per creare un elenco d'informazioni, è importante rispettare le seguenti regole:
1) l'elenco deve avere sempre una riga d'intestazione con i nomi delle colonne;
2) l'elenco dev'essere compatto, senza righe e colonne vuote;
3) se è possibile, iniziare l'elenco partendo dalla cella A1;
4) se è possibile, dedicare l'intero foglio di lavoro per la gestione dei dati dell'elenco, soprattutto se sono tanti;
5) a parte la riga d'intestazione, non inserire bordi al contenuto dell'elenco.
L'immagine seguente mostra un esempio di elenco di dati.
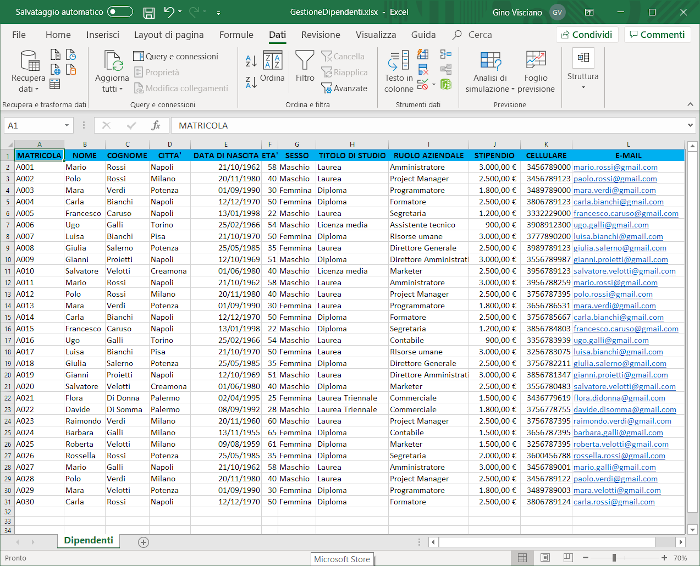
Come ordinare i dati di un elenco
Prima di procedere con l'ordinamento dei dati dell'elenco, dovete decidere quali sono le chiavi da utilizzare per l'ordinamento.
In questo esempio le chiavi potrebbero essere le seguenti:
A) Cognome, Nome ed Età;
B) Titolo di Studio, Cognome, Nome ed Età;
C) Città, Cognome, Nome ed Età;
D) Sesso, Cognome, Nome ed Età;
E) Ruolo Aziendale, Cognome, Nome ed Età;
F) Matricola.
La prima chiave si chiama primaria, perché l'elenco viene prima ordinato utilizzando questa chiave.
Se dopo l'ordinamento, in alcune righe la chiave primaria si ripete, queste righe vengono ordinate utilizzando la chiave seguente e così via fin quando l'elenco non risulta ordinato in base a tutte le chiavi indicate.
Attenzione se la chiave primaria di ordinamento non si ripete mai, come accade nel nostro esempio per la matricola, è inutile indicare ulteriori chiavi di ordinamento.
Una volta individuate la chiavi da utilizzare per l'ordinamento potete procedere nel modo seguente:
1) Posizionate il cursore sulla riga d'intestazione dell'elenco, nella prima colonna;
2) Selezionate il menu dati e cliccate sull'icona ordina, indicata di seguito:
3) Nella casella di selezione "Ordina per", scegliete la colonna cognome;
4) Successivamente per aggiungere anche le altre chiavi di ordinamento, usate il pulsante "+Aggiungi livello, come mostra l'immagine seguente:
5) Per ogni chiave impostate l'ordine a destra e cliccate sul pulsante "OK".
Per ordinare l'elenco con chiavi di ordinamento diverse, procedete nel modo seguente:
1) Posizionate il cursore sulla riga d'intestazione dell'elenco, nella prima colonna;
2) Selezionate il menu dati e cliccate sull'icona ordina, indicata di seguito:
3) Utilizzare il pulsate:
per eliminare le chiavi precedenti ed aggiungete le nuove chiavi di ordinamento.
Come filtrare i dati di un elenco
B) Città: Potenza;
C) Titolo di studio: Laurea;
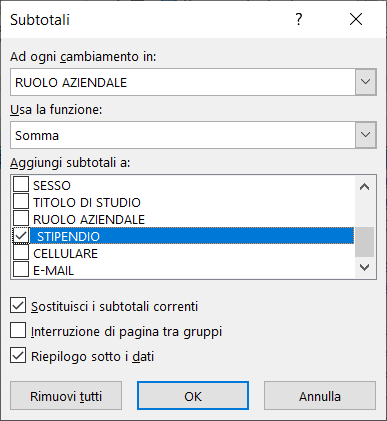
2) Selezionate il menu dati e cliccate sull'icona filtro, indicata di seguito:

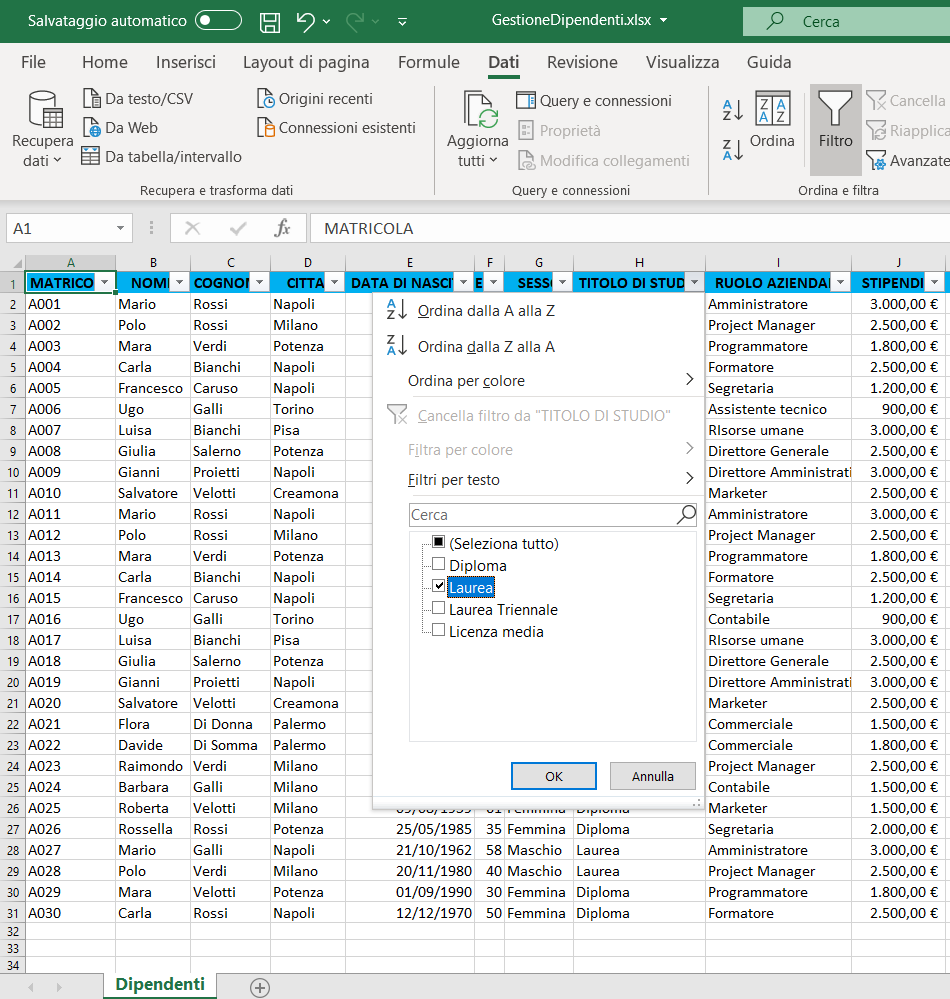
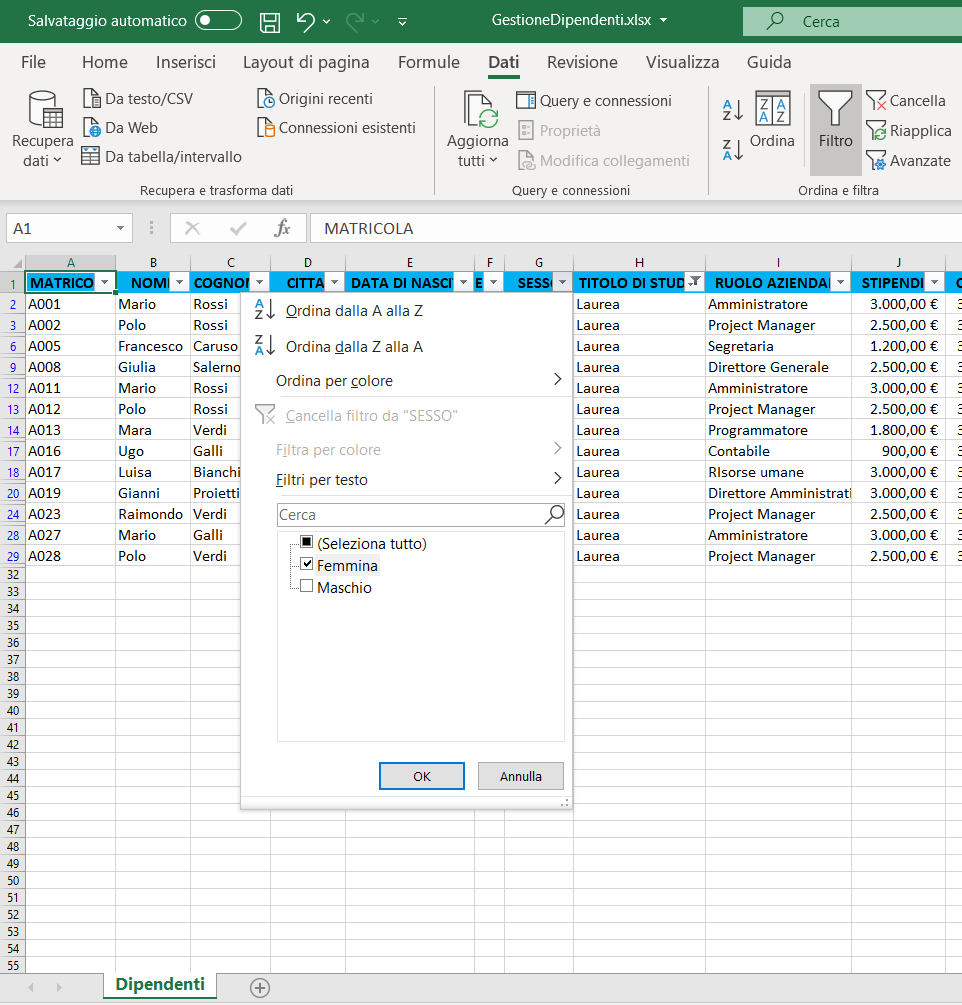
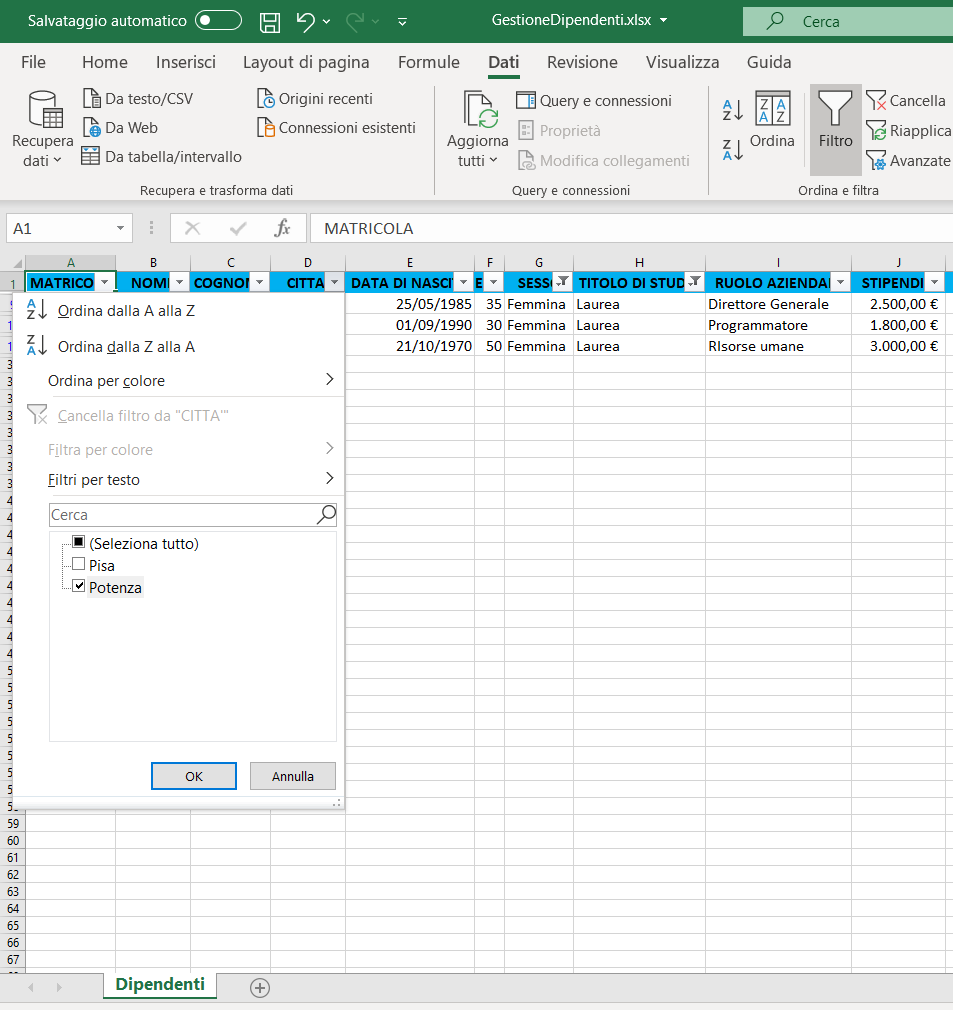
2) Selezionate il menu dati e cliccate sull'icona filtro, indicata di seguito:
3) Sulla destra di ogni colonna apparirà una freccia, cliccate sulla freccia corrispondente alla colonna Stipendio e scegliete le opzioni seguenti:
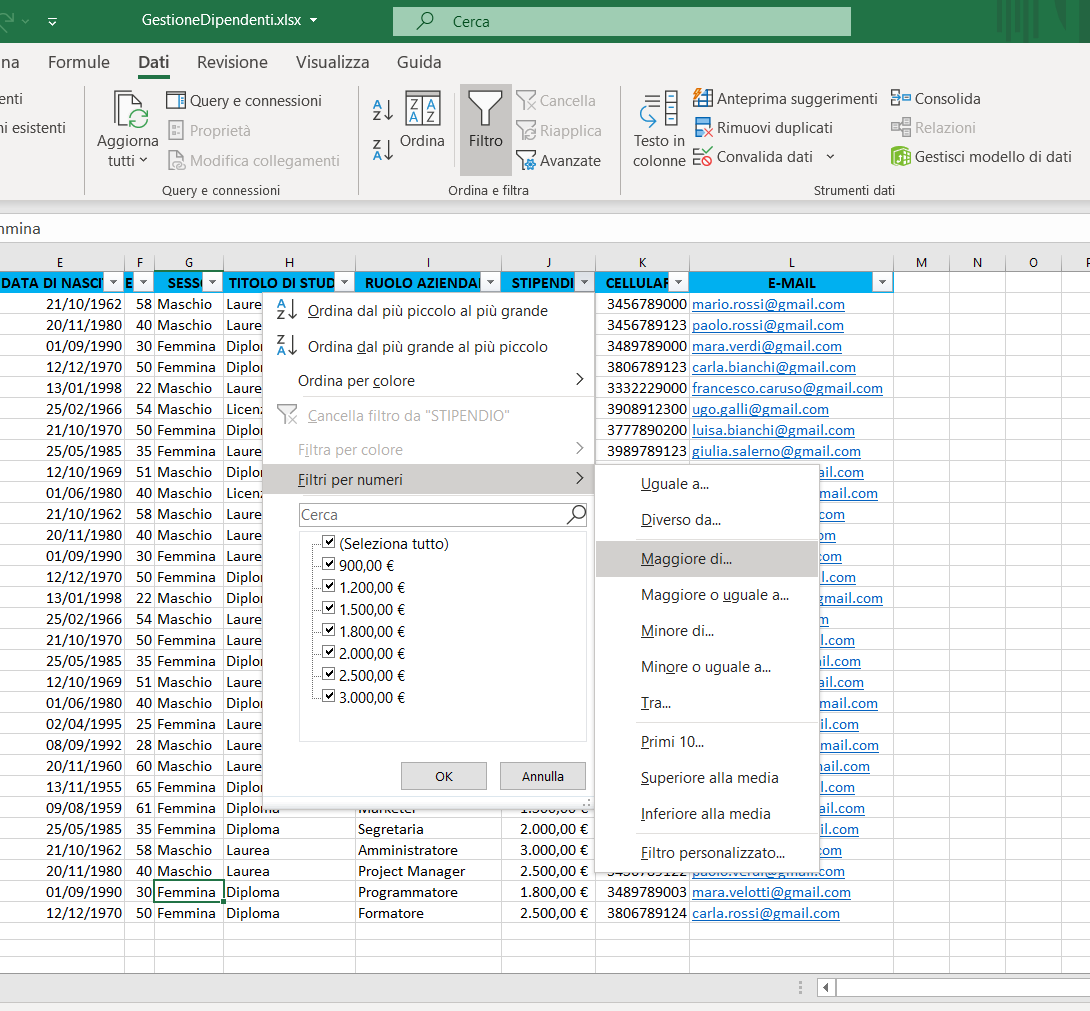
3) Qual è la colonna a cui applicare la funzione per il calcolo del subtotale.
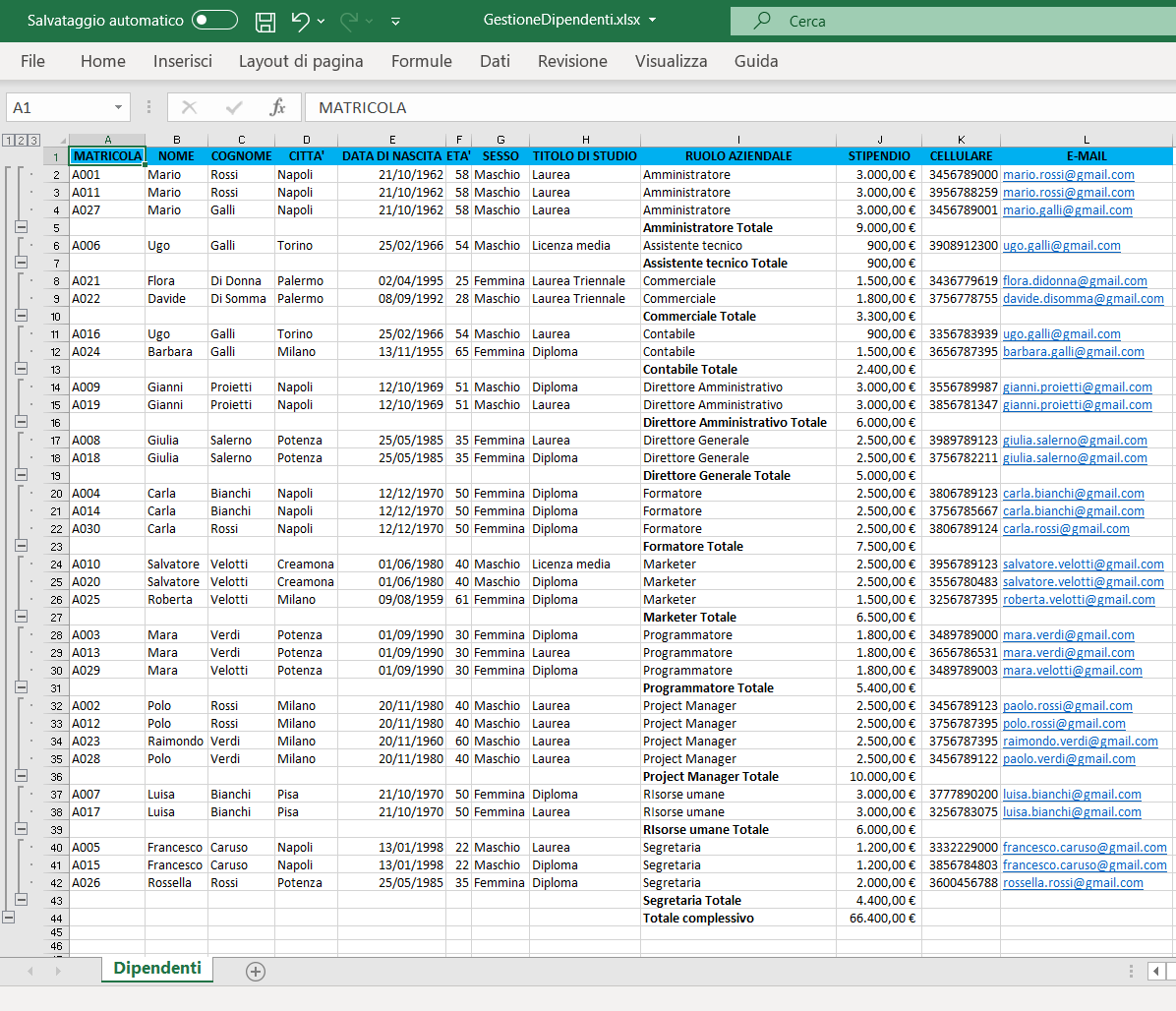
Per il download del file excel GestioneDipendenti.xlsx clicca qui.
<< Lezione precedente Lezione successiva >>
T U T O R I A L S S U G G E R I T I
Webinar "Come fare SMART LEARNING con SKILLBOOK e MICROSOFT TEAMS"
![]() Gino Visciano |
Skill Factory - 05/05/2020 09:15:44 | in Home
Gino Visciano |
Skill Factory - 05/05/2020 09:15:44 | in Home
 L'emergenza COVID-19 sta obbligando il mondo dell'Istruzione e della Formazione professionale a cambiare i modelli di apprendimento , basati principalmente sulla didattica in presenza, sostituendoli con modelli didattici di tipo digitale. All'improvviso la tecnologia diventa indispensabile per ridurre le distanze imposte dai diversi decreti del governo, che obbligano tutti a rispettare il distanziamento sociale, per evitare la diffusione del virus.
L'emergenza COVID-19 sta obbligando il mondo dell'Istruzione e della Formazione professionale a cambiare i modelli di apprendimento , basati principalmente sulla didattica in presenza, sostituendoli con modelli didattici di tipo digitale. All'improvviso la tecnologia diventa indispensabile per ridurre le distanze imposte dai diversi decreti del governo, che obbligano tutti a rispettare il distanziamento sociale, per evitare la diffusione del virus.
Questo scenario richiede che venga coperto al più presto il GAP sia culturale, sia tecnico, necessario per permettere a tutti di utilizzare correttamente gli strumenti che servono per fare formazione in rete.
 Il Webinar "Come fare SMART LEARNING con SKILLBOOK e MICROSOFT TEAMS", si pone l'obiettivo di fornire a tutti gli stakeholders che lavorano nel mondo dell'Istruzione e della Formazione professionale, una panoramica esaustiva delle metodologie e degli strumenti per collaborare e fare formazione in rete, utilizzando Skillbook e Microsoft Teams.
Il Webinar "Come fare SMART LEARNING con SKILLBOOK e MICROSOFT TEAMS", si pone l'obiettivo di fornire a tutti gli stakeholders che lavorano nel mondo dell'Istruzione e della Formazione professionale, una panoramica esaustiva delle metodologie e degli strumenti per collaborare e fare formazione in rete, utilizzando Skillbook e Microsoft Teams.
Skillbook è la piattaforma Asincrona, sviluppata nel 2010, dalla Skill Factory, per Informare, Reclutare, Selezionare, Formare ed Orientare i giovani diplomati e laurati verso il mondo del lavoro. Attraverso la Community Learning Skillbook, oltre 2000 giovani hanno già trovato un lavoro presso un'azienda italiana del settore ICT.
![]() Skillbook integrata con Microsoft Teams, diventa ancora più potente, perché può essere utilizzata anche in modalità Sincrona.
Skillbook integrata con Microsoft Teams, diventa ancora più potente, perché può essere utilizzata anche in modalità Sincrona.
Durante il Webinar, Gino Visciano, CEO della Skill Factory, che ha progettato e sviluppato, insieme al suo team, la piattaforma Skillbook, vi descriverà nel dettaglio tutte le potenzialità e le modalità per fare Smart Learning, con successo!
Per partecipare al Webinar gratuito, "Come fare SMART LEARNING con SKILLBOOK e MICROSOFT TEAMS", previsto per martedì 12 maggio 2020, dalle ore 16,00 alle ore 18,00, registrati su Skillbook, per ricevere l'invito di partecipazione direttamente dalla piattaforma Teams.
Se incontri difficoltà inviaci una e-mail al seguente indirizzo: sid@skillfactory.it.
A tutti i partecipanti verrà rilasciato un attestato che certifica gli argomenti acquisiti durante il Webinar, fondamentali per chi deve svolgere il ruolo di "Esperto di strumenti e metodologie digitali per lo Smart Learning".
 FILTRI
FILTRI


 Offerte di Lavoro
Offerte di Lavoro
 Post più recenti
Post più recenti
-

Full Stack Developer
07/05/2026
-
1° MAGGIO: FESTA DEL LAVORO E DELLA FORMAZIONE
01/05/2026
-
Operatore Amministrativo Contabile
09/04/2026
-
Tecnico Programmatore: Il Profilo più richiesto dai giovani che frequentano la nostra Academy
17/03/2026
-
6.L'Assicurazione della Qualità nell'IFP
24/01/2026
-
Skill Factory 2025: Un anno di formazione tra "Innovazione (AI), Qualità (EQAVET) e Politiche Attive del Lavoro (PAR GOL)"
30/12/2025
-
10.Intelligenza Artificiale: cosa cambia nel mondo del lavoro
21/12/2025
-
5.L’etica della formazione come responsabilità professionale
13/12/2025
-
4.Buona Formazione: "Come assicurare la Qualità della Formazione"
06/12/2025
-
Corso gratuito di 60 ore per creare le competenze digitali fondamentali (DIGCOMP2.2)
25/09/2025