





-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-





 Scheda Azienda
Scheda Azienda Eventi formazione
Eventi formazione Offerta formativa
Offerta formativa Lavora con noi
Lavora con noi
 Richiedi informazioni
Richiedi informazioni
Skill Factory
Tutte le categorie
TypeScript - Lezione 4: Tipi di Funzioni
![]() Gino Visciano |
Skill Factory - 03/07/2020 16:33:54 | in Tutorials
Gino Visciano |
Skill Factory - 03/07/2020 16:33:54 | in Tutorials
In questa lezione vedremo tutti i tipi di funzioni che si possono utilizzare in TypeScript.
Per creare una funzione in TypeScript dovete utilizzare la sintassi seguente:
function nomeFunzione(elenco argomenti):tipoValoreRestituito {
// Codice funzione
}
Se la funzione si comporta come una procedura , perché non restituisce nessun valore, come tipoValoreRestituito dovete usare il tipo void.

Ad esempio la funzione contaFinoADieci è di tipo void, perché è una procedura che visualizza un numero da 1 fino a 10:
function contaFinoADieci():void {
La parola chiave let indica che la variabile x può essere usata solo nel blocco for, al di fuori del blocco for non è visibile. Per usare la x anche al di fuori del blocco for dovete usare la parola chiave var.
Anche la funzione contaFinoAMax è una procedura, ma attraverso l'argomento max permette di visualizzare un numero da 1 ad un valore predefinito.
function contaFinoAMax(max:number):void {
Quando la funzione restituisce un valore attraverso il comando return, il tipoValoreRestituito deve essere dello stesso tipo, come mostra l'esempio seguente:
function divisione(dividendo:number, divisore:number):number {
DIFFERENZA TRA FUNZIONI CON PASSAGGIO PER VALORE E PASSAGGIO PER RIFERIMENTO
Le funzioni sono task di programmazione che eseguono operazioni specifiche quando vengono eseguite.
Se necessario possono ricevere argomenti in input e restituire un argomento come output, naturalmente se non sono di tipo void.
L'immagine seguente mostra il comportamento di una funzione che riceve n argomenti in ingresso (input) e ne restituisce uno in uscita (output).

Block box significa che se una funzione riceve in input gli stessi argomenti, fornisce sempre lo stesso risultato come output.
Gli argomenti delle funzioni, sia in input, sia in output, possono essere passati per valore oppure per riferimento.
Quando passate un argomento per valore state passando il contenuto di una variabile.
Quando il passaggio avviene per riferimento state passando l'indirizzo di un array oppure di un oggetto in cui sono contenuti i valori.
Questa differenza è molto importante perché se il passaggio degli argomenti avviene per valore, utilizzate una copia dei valori originali, mentre se il passaggio degli argomenti avviene per riferimento, attraverso l'indirizzo lavorate direttamente con i valori degli array o degli oggetti originali.
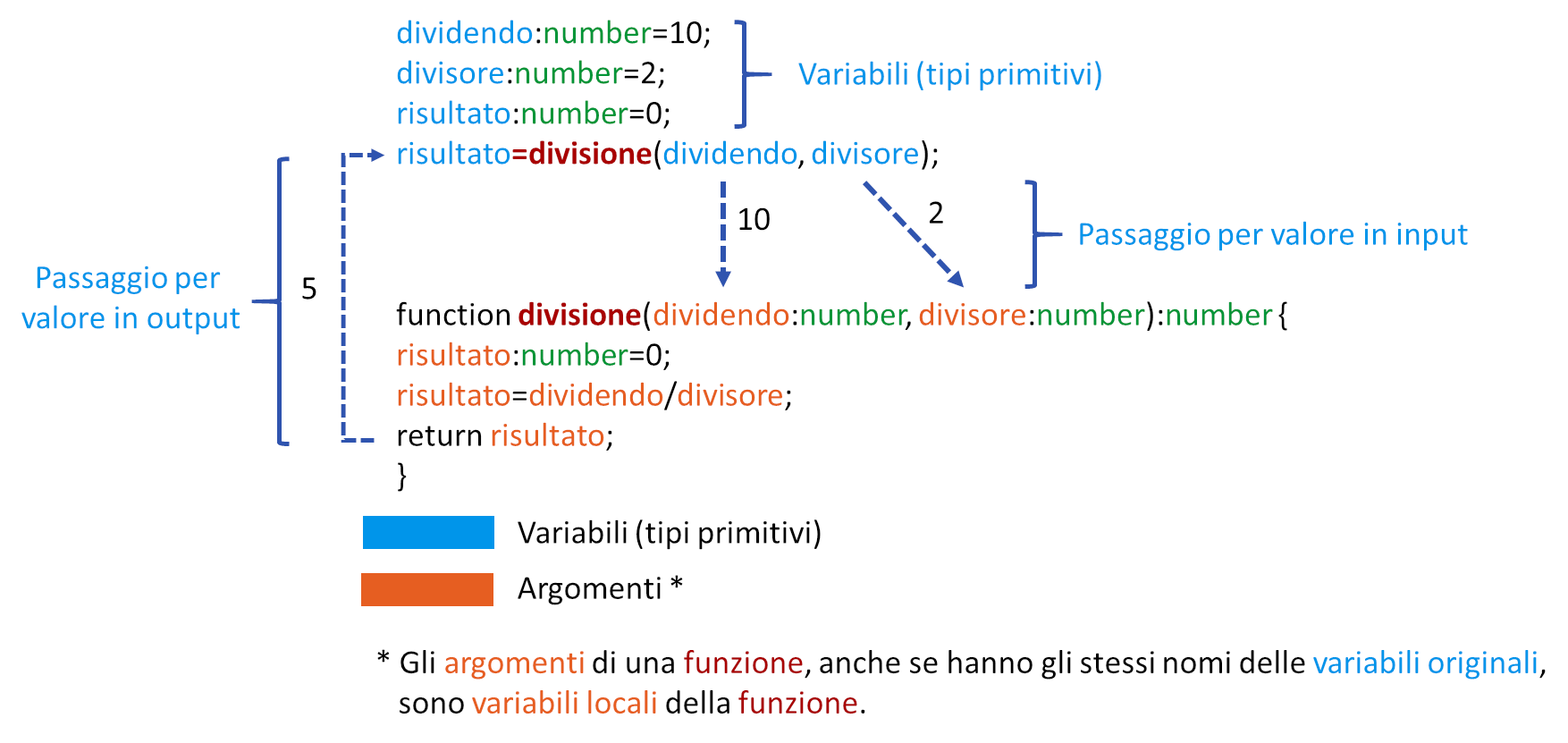
L'immagine seguente descrive un esempio di passaggio per valore, in questo caso gli argomenti della funzione divisione ricevono una copia del contenuto delle variabili dividendo e divisore.
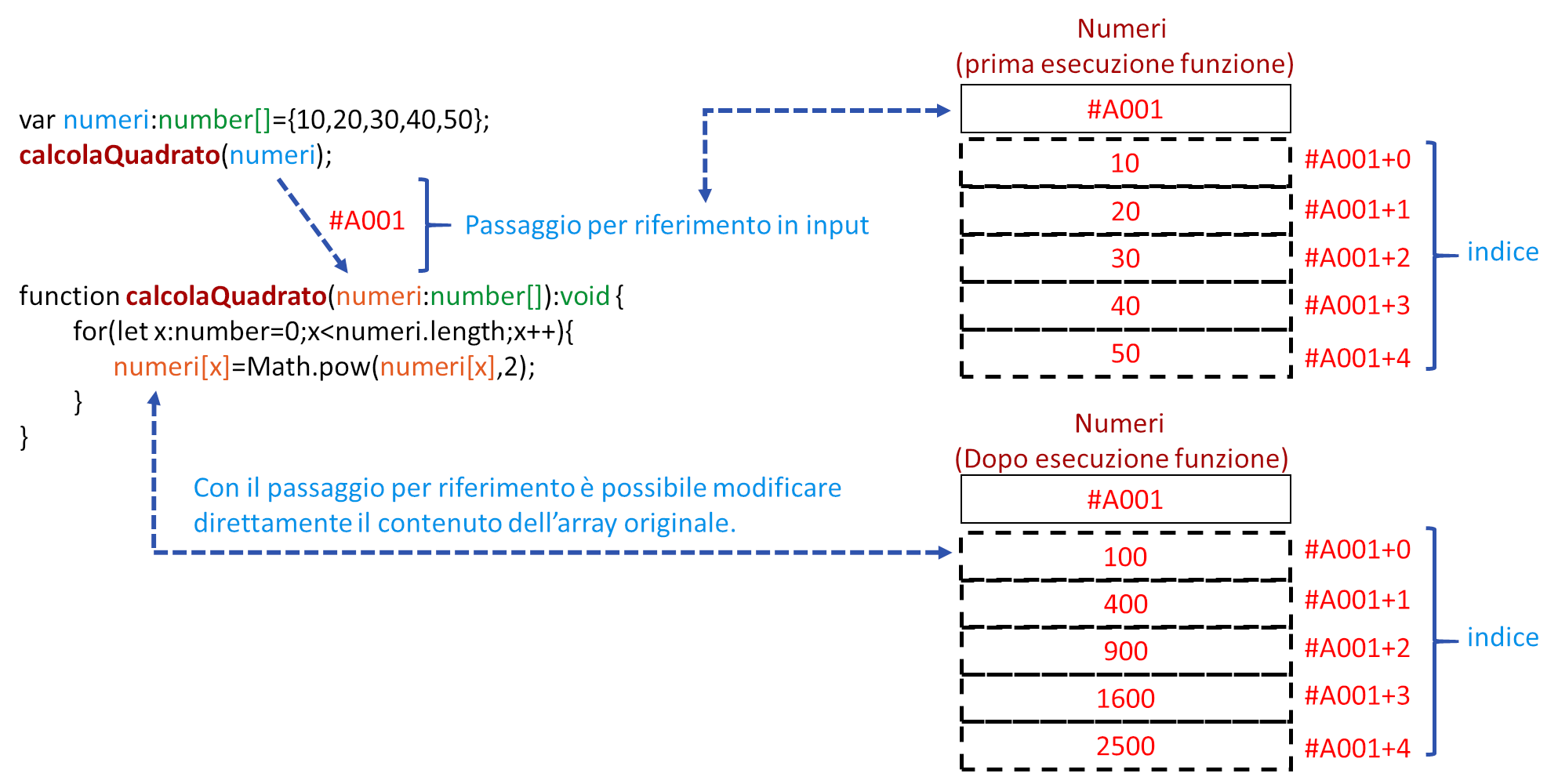
L'immagine seguente descrive un esempio di passaggio per riferimento, in questo caso l'argomento della funzione calcolaQuadrato riceve una copia del riferimento (indirizzo) dell'array di interi numeri, attraverso il riferimento può modificare direttamente il contenuto dell'array.
Esempio 1
L'esempio seguente mostra che il passaggio per valore permette di copiare il contenuto della variabile originale nella variabile indicata come argomento. Modificando il contenuto della variabile indicata come argomento della funzione, il contenuto della variabile originale non cambia:
// passaggio_per_valore.ts
Funzione modificaValore, valore passato:10
Funzione modificaValore, valore modificato:20
Modulo, valore dopo l'esecuzione della funzione modificaValore:10
Con il passaggio per valore, per modificare il contenuto della variabile originale dovete usare il comando return, come mostra l'esempio seguente:
Esempio 2
Funzione modificaValore, valore passato:10
Funzione modificaValore, valore modificato:20
Modulo, valore dopo l'esecuzione della funzione modificaValore:20
Esempio 3
L'esempio seguente mostra che il passaggio per riferimento permette di copiare l'indirizzo di un array o di un oggetto nella variabile indicata come argomento. Attraverso il riferimento è possibile modificare direttamente il valore della variabile originale:
Funzione modificaValore, valore passato:10
Funzione modificaValore, valore modificato:20
Modulo, valore dopo l'esecuzione della funzione modificaValore:20
FUNZIONI ANONIME
In TypeScript le funzioni possono essere passate come argomenti ad altre funzioni, utilizzando il loro riferimento.
In questo caso non passate un'informazione, ma un comportamento.
Una funzione che riceve in input il riferimento di una funzione viene chiamata funzione superiore.
Le funzioni anonime sono funzioni che non hanno un nome e possono essere eseguite attraverso il loro riferimento.
Questo tipo di funzione può anche essere passata come argomento ad funzione superiore.
L'esempio seguente mostra come si crea ed esegue una funzione anonima, utilizzando il metodo log che in questo caso è la funzione superiore.
FUNZIONI LAMBDA
Le funzioni lambda sono particolari tipi di funzioni anonime, quindi anch'esse possono essere passate come argomenti alle funzione superiori.
La sintassi per creare le funzioni lambda è leggermente diversa da quella usata per le funzioni anonime, perché al posto della parola chiave function si usa l'operatore freccia "=>", come mostra l'esempio seguente:
var rifPerimetro=(latoA:number,latoB:number,latoC:number):number => {
---------------------------------------------------------------------------------------
Attenzione, le funzioni lambda e le funzioni anonime, se sono composte da una sola riga di comando, possono essere implementate senza usare le parentesi graffe e senza indicare il return, come mostra l'esempio seguente:
var rifPerimetro=(latoA:number,latoB:number,latoC:number):number => latoA+latoB+latoC;
FUNZIONI RICORSIVE
In TypeScript le funzioni sono ricorsive, cioè possono chiamare se stesse. Questa caratteristica è molto importante perché la ricorsività permette di simulare il comportamento di un ciclo while al contrario.
Per capire l'utilità della ricorsività delle funzioni facciamo alcuni esempi.
Esempio 4
Visualizzare il contenuto di una array d'interi partendo dall'ultimo valore al primo.
A) Soluzione utilizzando un while.
15
5
70
30
80
8
25
10
2
B) Soluzione utilizzando una funzione ricorsiva.
8,15
7,5
6,70
5,30
4,80
3,8
2,25
1,10
0,2
Esempio 5
Calcolare il fattoriale di un numero intero N.
Il fattoriale di un numero intero N è dato dal prodotto di tutti i valori compresi tra 1 ad N, ad esempio il fattoriale di 3 = 1 * 2 * 3 = 6.
A) Soluzione utilizzando un while.
B) Soluzione utilizzando una funzione ricorsiva.
Attenzione, per convenzione, il fattoriale di 0 = 1.
FUNZIONI CON ARGOMENTI OPZIONALI
In TypeScript si possono creare funzioni con argomenti opzionali, per rendere l'argomento di una funzione opzionale basta inserire un "?" dopo il nome dell'argomento, come mostra l'esempio seguente:
function infoFiguraGeometrica(tipoFigura:string, valoreUno:number,valoreDue?:number,valoreTre?:number){...}
La dichiarazione della funzione infoFiguraGeometrica indica che gli argomenti tipoFigura:string, valoreUno:number, sono obbligatori e gli argomenti valoreDue?:number,valoreTre?:number sono opzionali.
L'attributo length dell'interfaccia arguments permette do conoscere il numero di argomenti passati ad una funzione con argomenti opzionali.
Esempio 6
----------------------------------------------------------------------
Tipo figura:Cerchio
Raggio :10
Perimetro :62.83185307179586
Area :314.1592653589793
---------------------------------------
Tipo figura:Quadrato
Lato :20
Perimetro :80
Area :400
---------------------------------------
Tipo figura:Rettangolo
Lati :10 5
Perimetro :30
Area :50
---------------------------------------
Tipo figura:Triangolo
Lati :10 20 20
Perimetro :50
Area :96.82458365518542
Un argomento opzionale a cui non viene passato nulla contiene il valore undefined, come mostra l'esempio seguente:
Non hai fornito argomenti
a=undefined
b=undefined
Argomenti:1
Hai fornito due argomenti
a=10
b=undefined
Argomenti:2
Hai fornito due argomenti
a=10
b=20
Per passare ad una funzione con argomenti opzionali, gli argomenti richiesti, utilizzando i nomi degli argomenti, dovete usare un'interfaccia e passare gli argomenti alla funzione con la notazione JSON, come mostra l'esempio seguente:
---------------------------------------------------------------------
Non hai fornito argomenti {}
a=undefined
b=undefined
Hai fornito un solo l'argomento b {a:10}
a=10
b=undefined
Hai fornito un solo l'argomento a {b:20}
a=undefined
b=20
Hai fornito due argomenti {a:10,b:20}
a=10
b=20
FUNZIONI CON ARGOMENTI REST
In TypeScript un altro modo per creare funzioni con argomenti opzionali è quello di utilizzare l'operatore "..." chiamato REST. L'argomento preceduto dall'operatore REST diventa un array che contiene i valori di tutti gli argomenti passati, come mostrano gli esempi seguenti:
Esempio 7
----------------------------------------------------------------------
Tipo figura:Cerchio
Raggio :10
Perimetro :62.83185307179586
Area :314.1592653589793
---------------------------------------
Tipo figura:Quadrato
Lato :20
Perimetro :80
Area :400
---------------------------------------
Tipo figura:Rettangolo
Lati :10 5
Perimetro :30
Area :50
---------------------------------------
Tipo figura:Triangolo
Lati :10 20 20
Perimetro :50
Area :96.82458365518542
Esempio 8
number:10.5
string:Rossi
boolean:true
object:Mario,Rossi,Milano,5/12/1990,Maschio
Nella prossima lezione iniziamo a parlare di Object Oriented in TypeScript, introducendo le Classi e gli Oggetti.
<< Lezione precedente Lezione successiva >> | Vai alla prima lezione
T U T O R I A L S S U G G E R I T I
- Impariamo Python giocando al "Solitario del ferroviere"
- Impariamo a programmare con JavaScript
- Laboratori di Logica di programmazione in C
- Introduzione alla Logica degli oggetti
- Ricominciamo ... dal Linguaggio SQL
- APP Mania
- Come sviluppare un Sito con Wordpress
- Excel delle meraviglie
EDUCATIONAL GAMING BOOK (EGB) "H2O"
 Nell'era dello SMART LEARNING e di PYTHON i libri non si scrivono, ma si sviluppano, in questo modo chi studia, può sperimentare ed apprendere contemporaneamente; un libro con queste caratteristiche lo possiamo definire un Educational Gaming Book (EGB).
Nell'era dello SMART LEARNING e di PYTHON i libri non si scrivono, ma si sviluppano, in questo modo chi studia, può sperimentare ed apprendere contemporaneamente; un libro con queste caratteristiche lo possiamo definire un Educational Gaming Book (EGB).
"H2O" è un EGB che descrive tutte le caratteristiche dell'acqua, la sostanza formata da molecole di H2O, che attraverso il suo ciclo di vita garantisce la sopravvivenza di tutti gli esseri viventi del Pianeta.
L'obiettivo dell'EGB è quello di far conoscere ai giovani le proprietà dell'acqua, sotto molti aspetti uniche, per sensibilizzarli a salvaguardare un bene comune e raro, indispensabile per la vita.
Per il DOWNLOAD di "H2O" clicca qui.

TypeScript - Lezione 3: Array (CRUD - JSON -ANALISI DATI)
![]() Gino Visciano |
Skill Factory - 26/06/2020 09:16:19 | in Tutorials
Gino Visciano |
Skill Factory - 26/06/2020 09:16:19 | in Tutorials
In questa lezione approfondiamo la gestione degli array, introducendo le principali tecniche di CRUD.

Come abbiamo già visto nella lezione precedente, un array è un contenitore dinamico d'informazioni, per poterlo usare in TypeScript lo dovete prima dichiarare:
var nominativi:string[];
Le parentesi quadre dopo il tipo differenziano gli array dalle variabili. Dopo aver dichiarato un array lo dovete sempre inizializzare come mostrano gli esempi seguenti:
var nominativi:string[];
nominativi=[]; // Inizializzazione di un array vuoto
oppure
var nominativi:string[];
nominativi=['Mario Rossi','Paola Verdi']; // Inizializzazione di un array con due nominativi.
Potete anche dichiarare in inizializzare contemporaneamente:
var nominativi:string[]=[]; // Dichiarazione ed inizializzazione di un array vuoto
oppure
var nominativi:string[]=['Mario Rossi','Paola Verdi']; // Dichiarazione ed inizializzazione di un array con due nominativi
CREATE (INSERIMENTO)
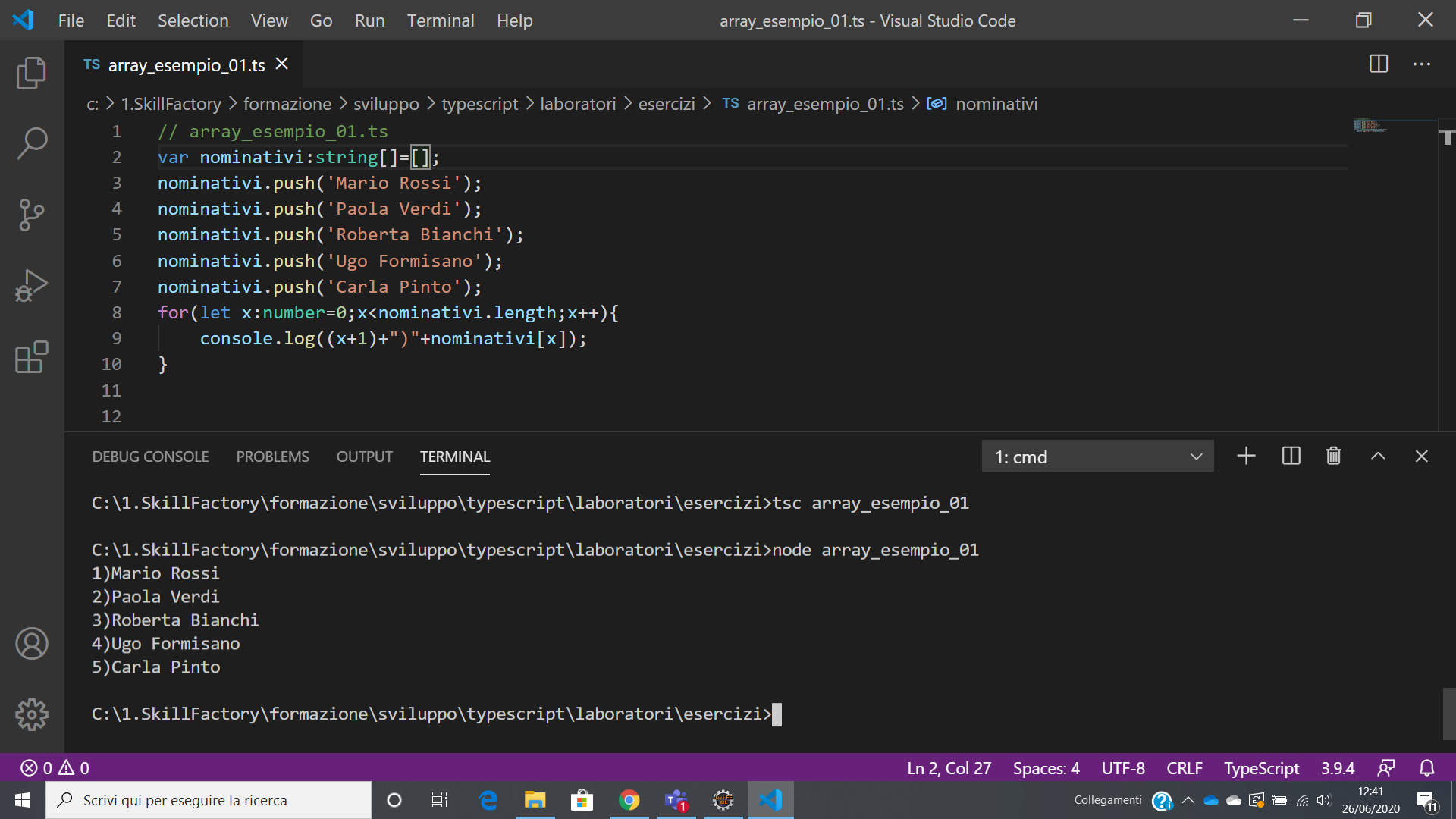
Per aggiungere le informazioni richieste in un array dovete usare il metodo push:
var nominativi:string[]=[]; // Dichiarazione ed inizializzazione di un array vuoto
nominativi.push('Mario Rossi');
nominativi.push('Paola Verdi');
READ (LETTURA)
Per leggere il contenuto di un elemento di un array, dovete conoscere la sua posizione ed indicarla attraverso un indice che corrisponde ad un valore numerico compreso tra 0 ed n-1, dove n è il numero totale di elementi nell'array.
Attenzione il primo elemento di un array corrisponde all'indice 0, l'ultimo all'indice n-1, come mostra l'esempio seguente:
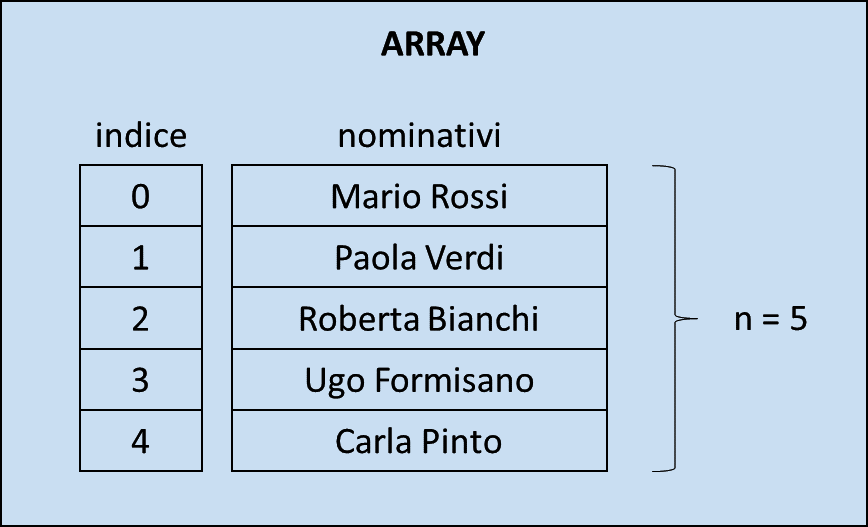
Esempio 1
UPDATE (MODIFICA)
Per modificare il contenuto di un elemento di un array basta sostituire semplicemente il vecchio valore con quello nuovo, come indica l'esempio seguente:
nominativi[3]='Pietro Morra"; // Sostituiamo Ugo Formisano con Pietro Morra
Esempio 2
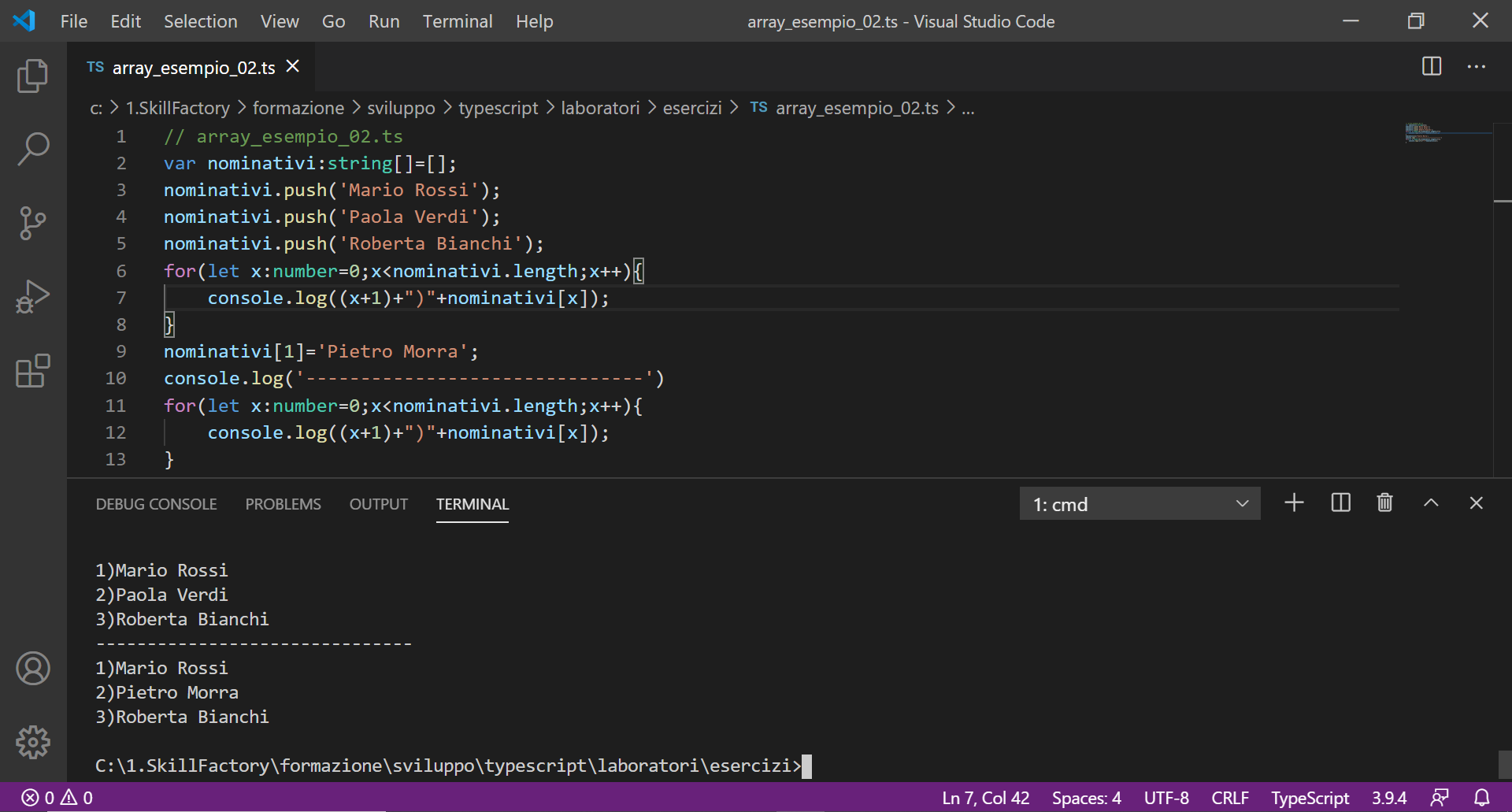
DELETE (ELIMINA)
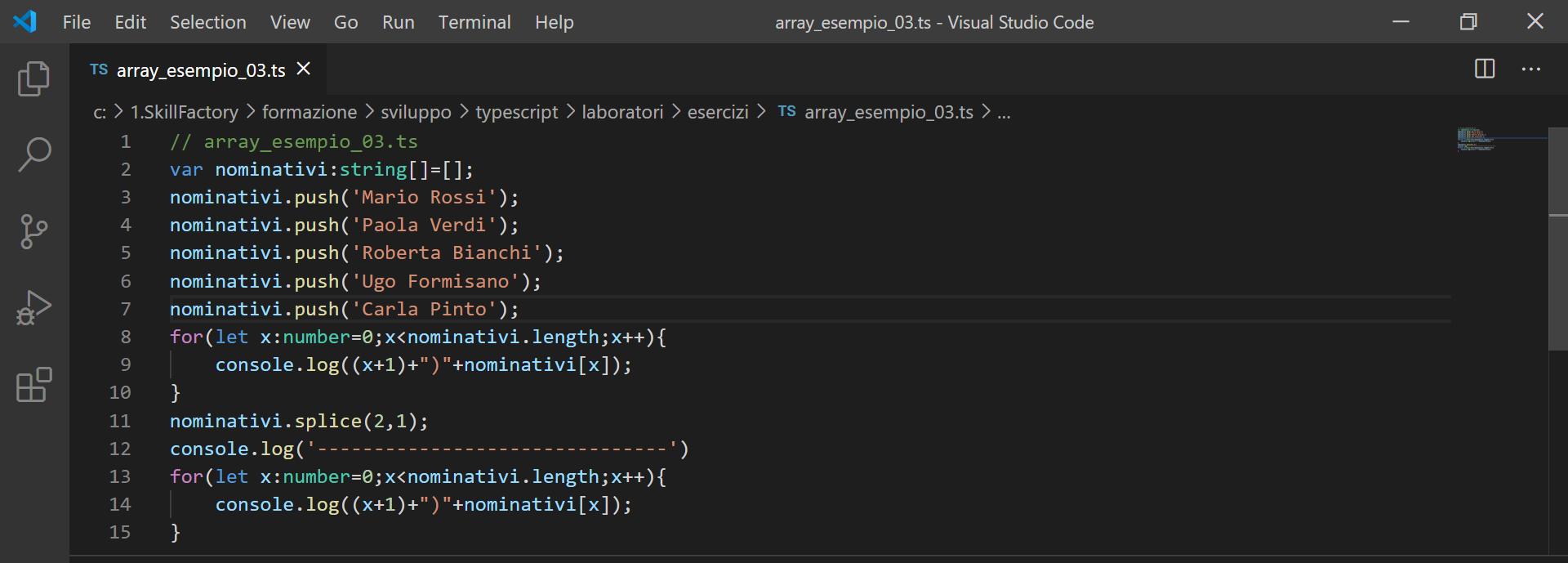
Per eliminare uno o più elementi da un array dovete usare il metodo splice, fornendo l'indice del primo elemento e quanti elementi volete cancellare, come mostra l'esempio seguente:
nominativi.splice(2,1); // l'indice 2 indica il 3° elemento dell'array, il valore 1 indica che vogliamo cancellare solo quello
oppure
nominativi.splice(2,2); // l'indice 2 indica il 3° elemento dell'array, il valore 2 indica che vogliamo cancellare il 3° ed il 4° elemento dell'array
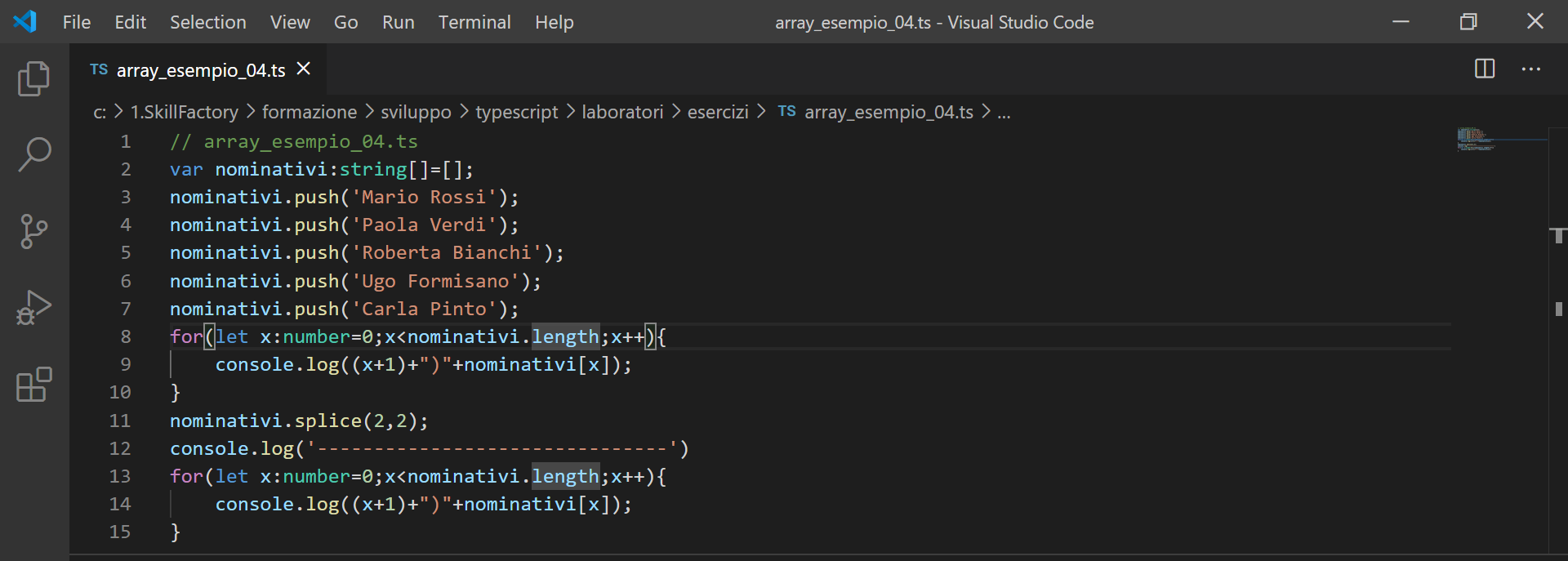
oppure
nominativi.splice(2); // l'indice 2 indica il 3° elemento dell'array, non avendo indicato quanti elementi eliminare vengono cancellati tutti gli elementi dell'array dal 3° in poi
Esempio 3
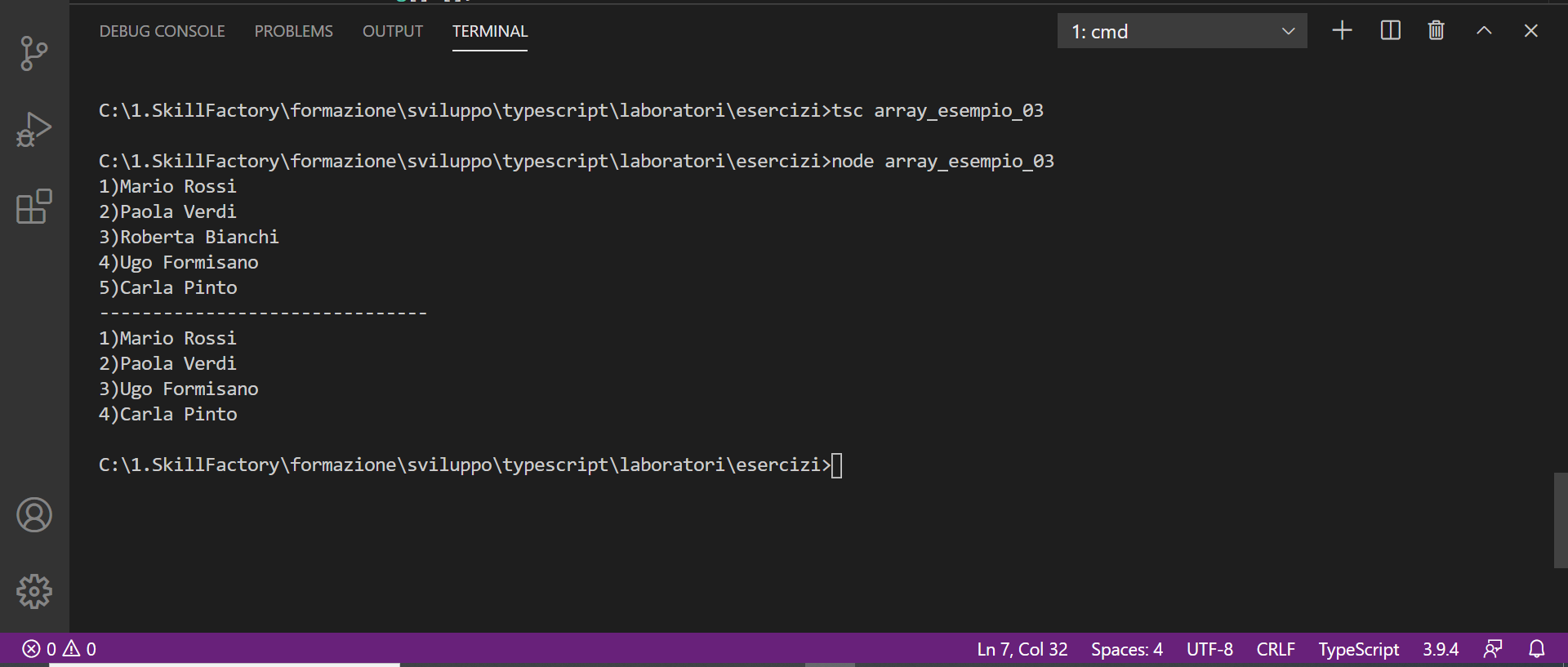
Esempio 4
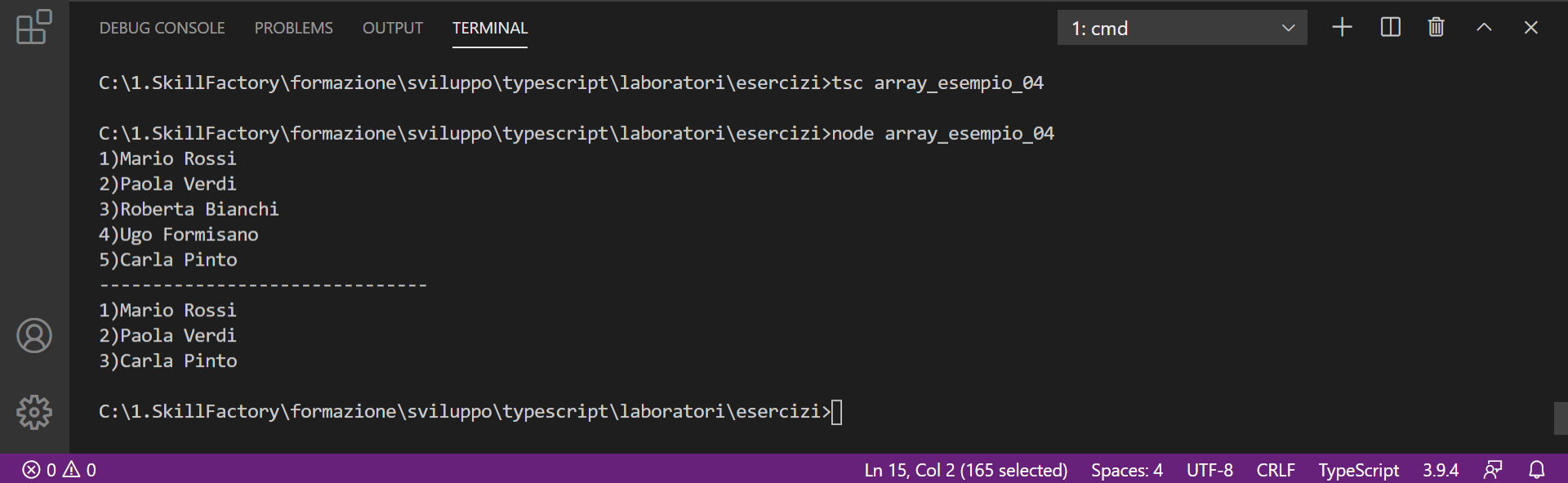
Se il valore cercato viene trovato il metodo indexOf ritorna l'indice dell'elemento in cui il valore è stato trovato, altrimenti ritorna -1.
var interi:number[]=[10,20,30];
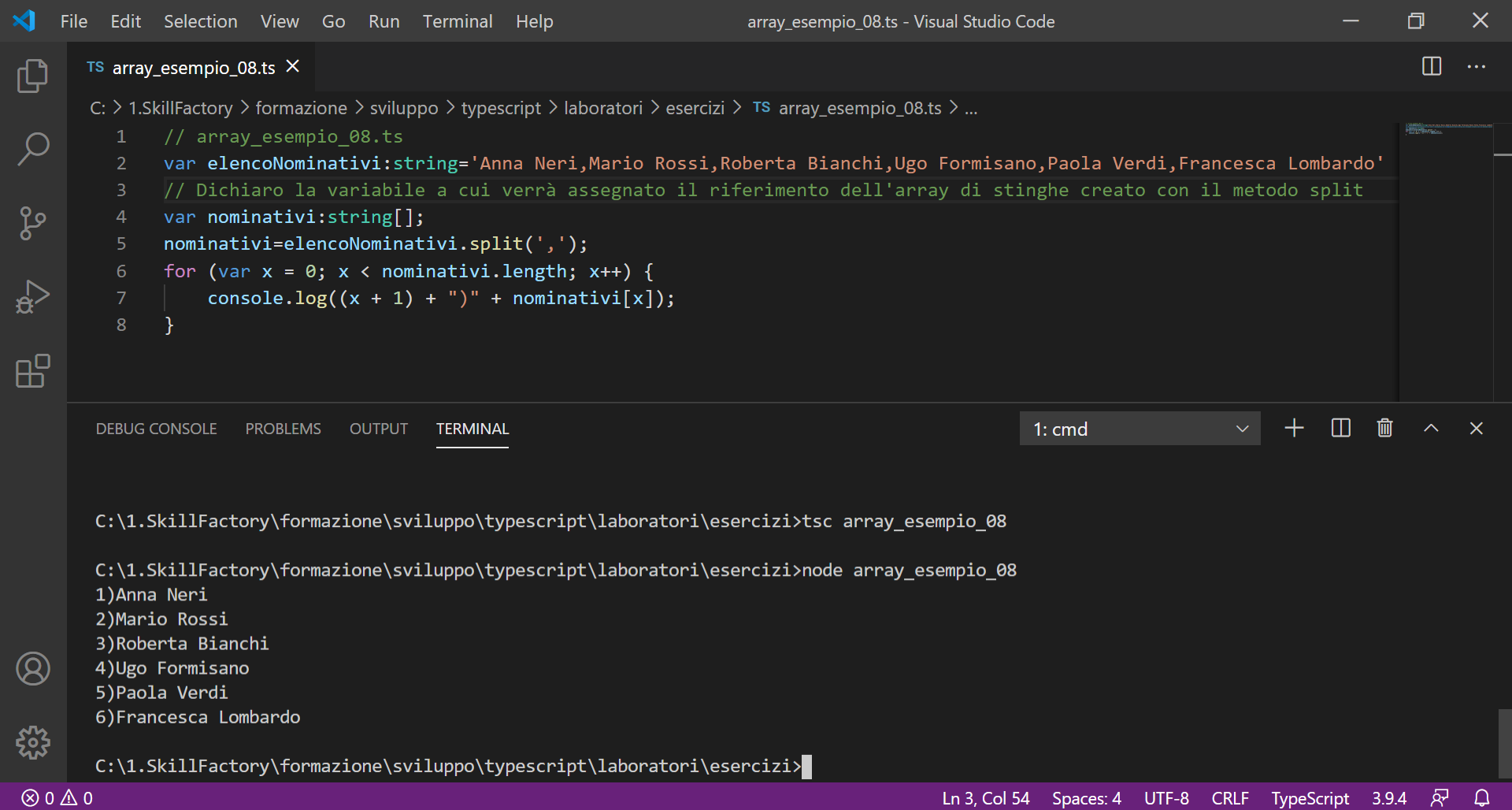
2)Mario Rossi
3)Paola Verdi
4)Roberta Bianchi
5)Ugo Formisano
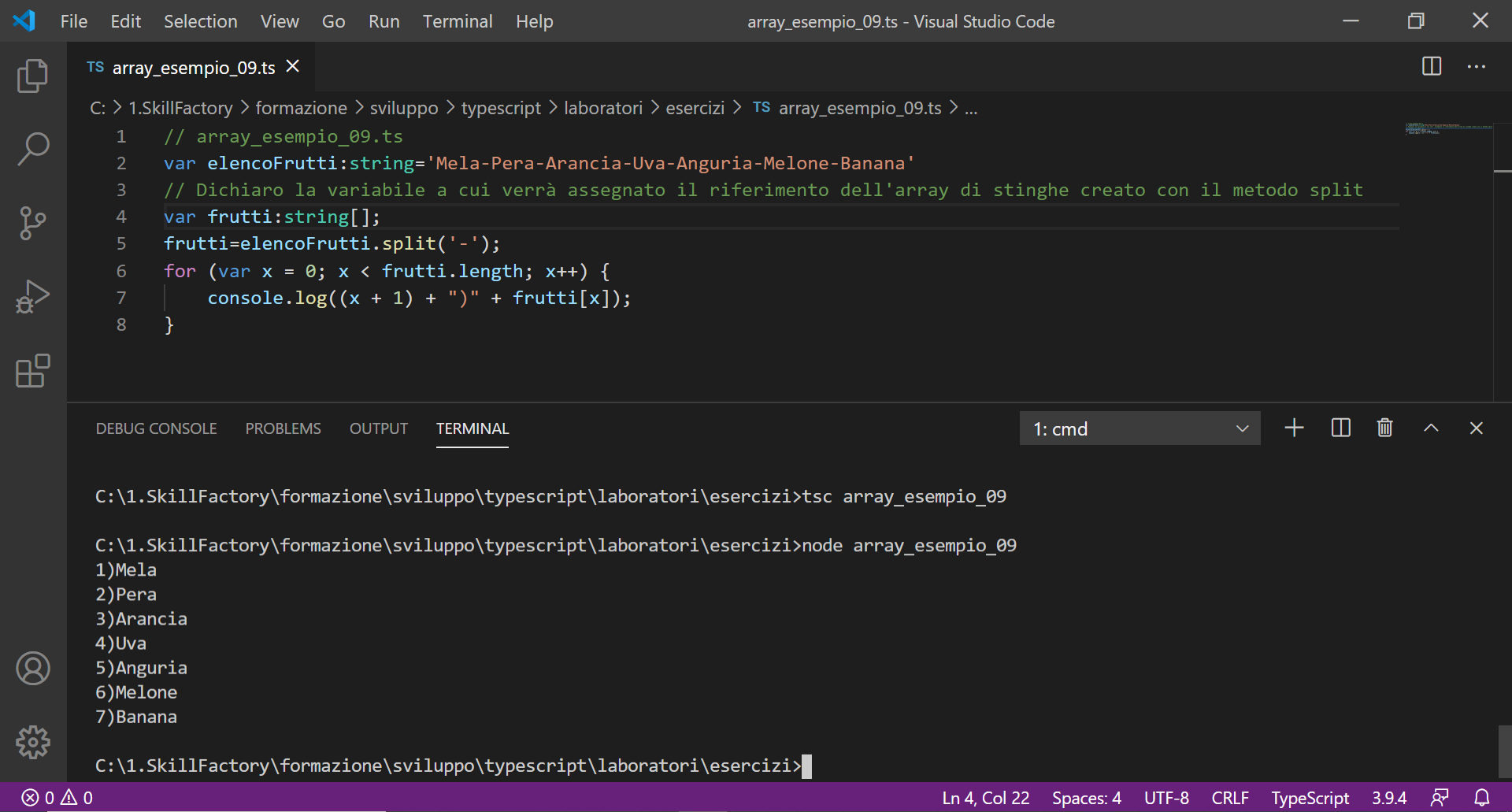
2)Roberta Bianchi
3)Paola Verdi
4)Mario Rossi
5)Carla Pinto
2)Ugo Formisano
3)Roberta Bianchi
4)Paola Verdi
5)Mario Rossi
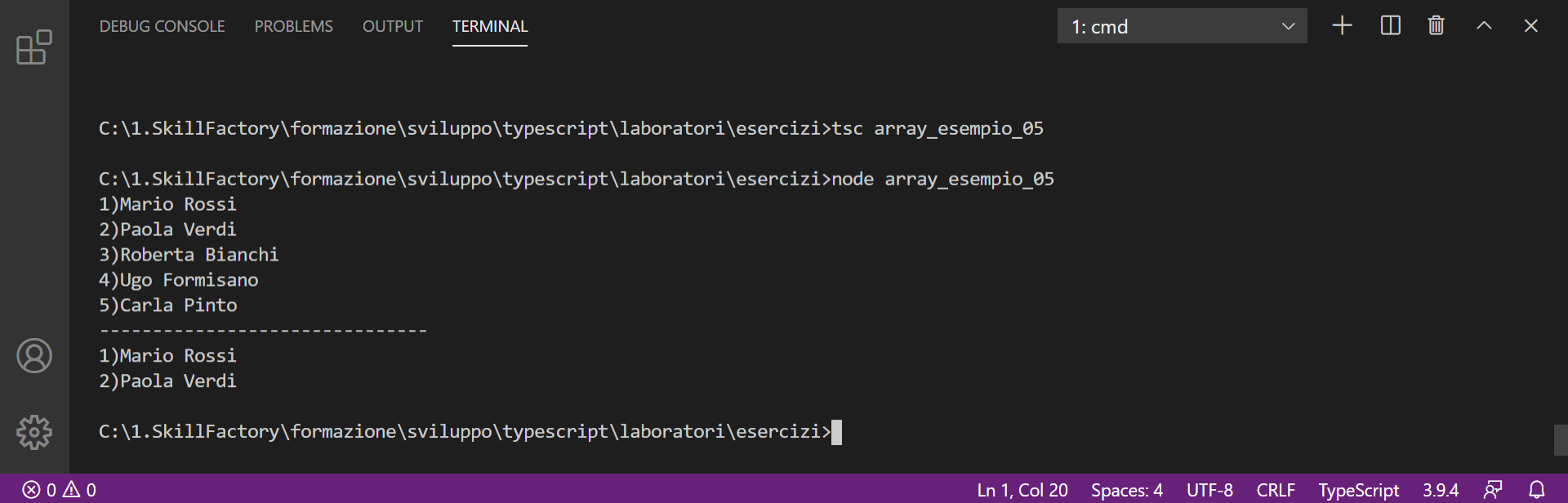
Attenzione, la dichiarazione:
var nominativiDue:string[];
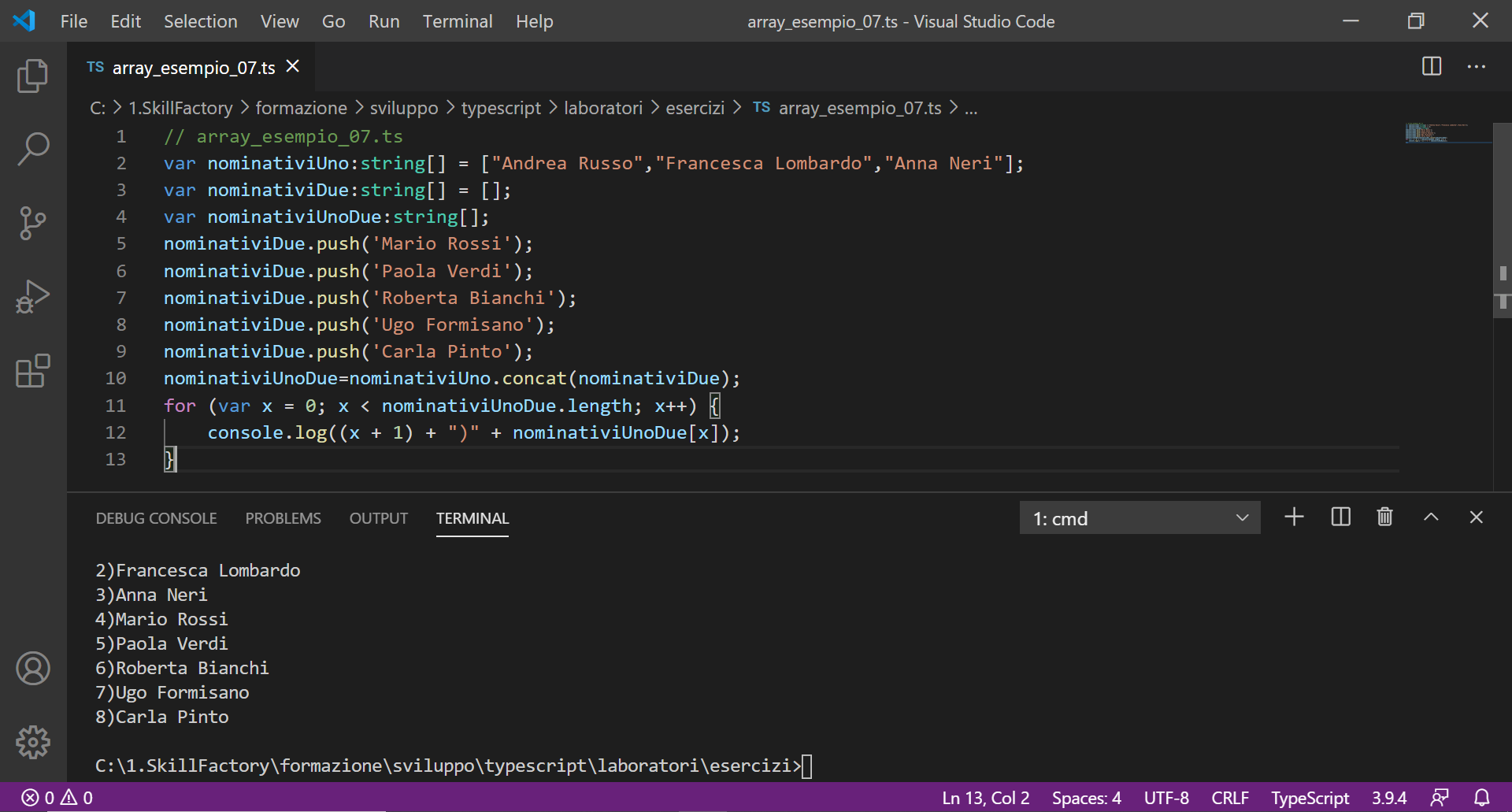
var nominativiUnoDue:string[];
20
30
40
50
Attenzione se l'operazione che volte svolgere è composta da una sola istruzione potete evitare di usare le parentesi graffe, altrimenti sono obbligatorie.
2) 20
3) 30
4) 40
5) 50
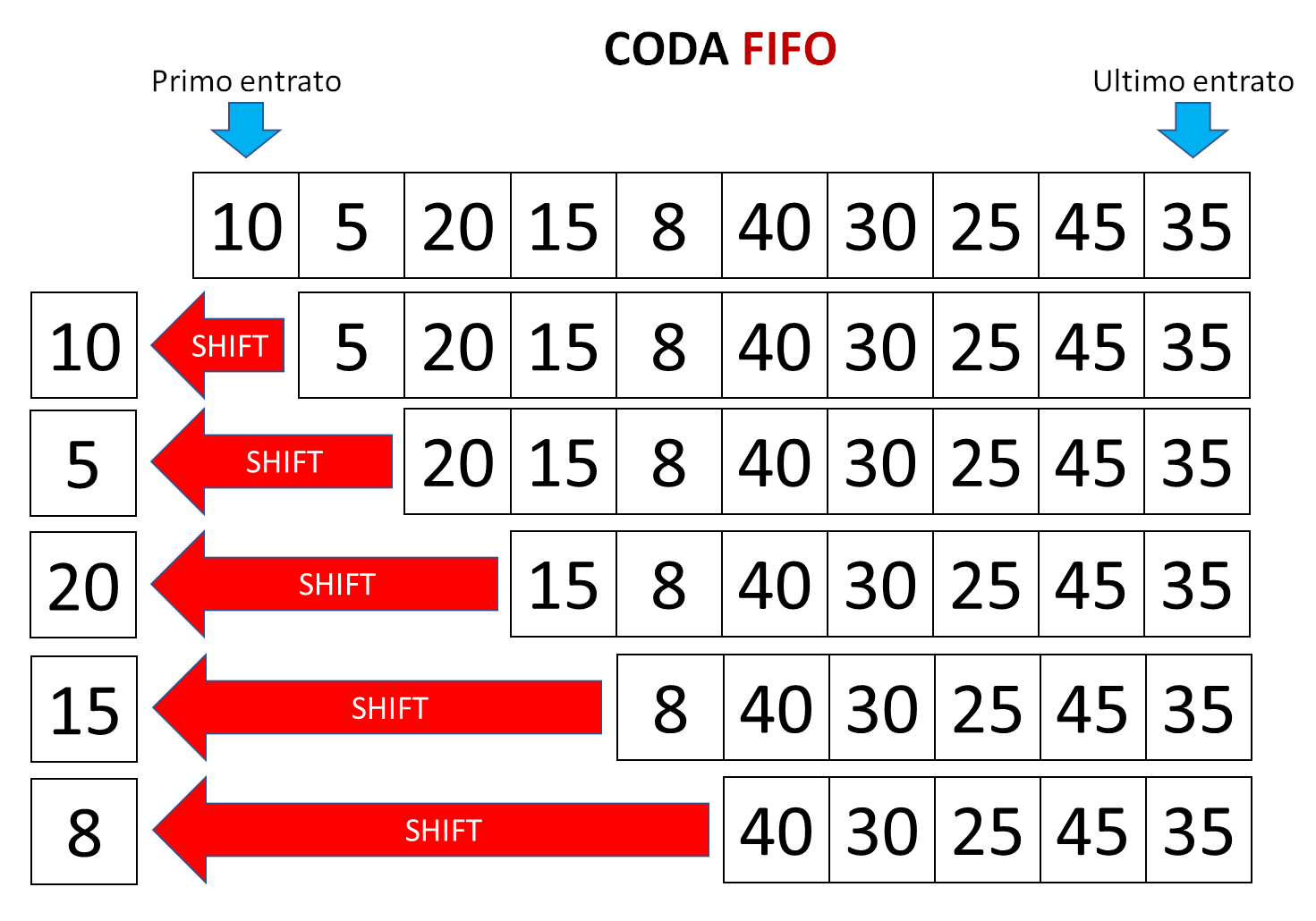
10<--5,20,15,8,40,30,25,45,35
5<--20,15,8,40,30,25,45,35
20<--15,8,40,30,25,45,35
15<--8,40,30,25,45,35
8<--40,30,25,45,35
40<--30,25,45,35
30<--25,45,35
25<--45,35
45<--35
35<--
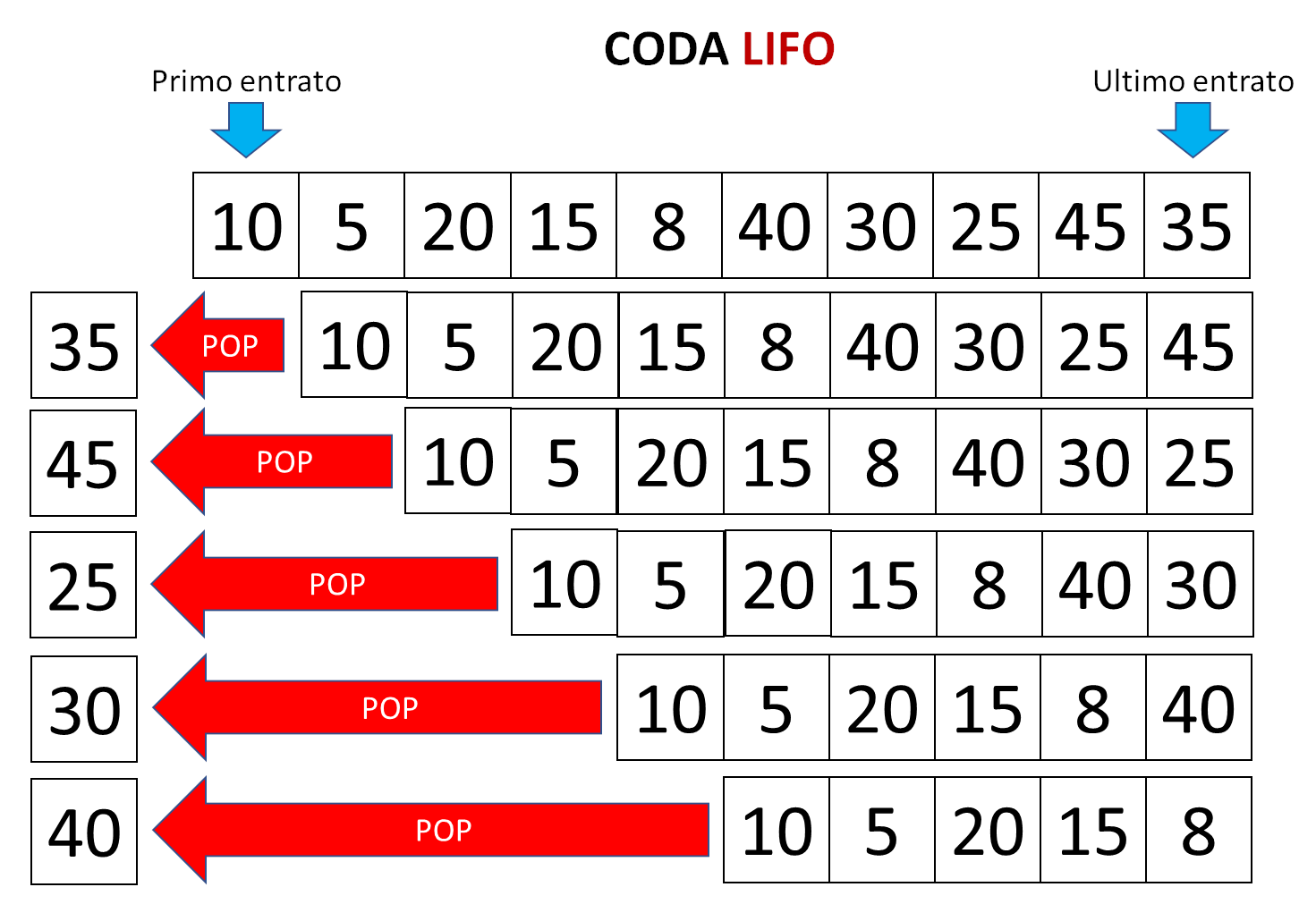
45<--10,5,20,15,8,40,30,25
25<--10,5,20,15,8,40,30
30<--10,5,20,15,8,40
40<--10,5,20,15,8
8<--10,5,20,15
15<--10,5,20
20<--10,5
5<--10
10<--
id: 1,
nome: 'Paola',
cognome: 'Verdi',
luogoDiNascita: 'Roma',
dataDiNascita: 1990-10-04T23:00:00.000Z,
sesso: true,
codiceFiscale: 'pllvrd90l05l234f',
titoliDiStudio: [ 'Diploma', 'Laurea' ]
}
{
id: 2,
nome: 'Marco',
cognome: 'Rossi',
luogoDiNascita: 'Napoli',
dataDiNascita: 1996-01-04T23:00:00.000Z,
sesso: false,
codiceFiscale: 'mrcrss96l01l256g',
titoliDiStudio: [ 'Diploma', 'Laurea Triennale', 'Laurea Magistrale' ]
}
{
id: 3,
nome: 'Carla',
cognome: 'Rossini',
luogoDiNascita: 'Pesaro',
dataDiNascita: 1990-10-14T23:00:00.000Z,
sesso: true,
codiceFiscale: 'crlrss90f10l324a',
titoliDiStudio: [ 'Diploma', 'Laurea Triennale' ]
}
{
id: 4,
nome: 'Roberta',
cognome: 'Bianchi',
luogoDiNascita: 'Firenze',
dataDiNascita: 2000-03-19T23:00:00.000Z,
sesso: false,
codiceFiscale: 'rbtbnc00f03p259b',
titoliDiStudio: [ 'Diploma' ]
}
{
id: 5,
nome: 'Ugo',
cognome: 'Formisano',
luogoDiNascita: 'Salerno',
dataDiNascita: 2002-07-27T22:00:00.000Z,
sesso: false,
codiceFiscale: 'gggfrm07r28m260p',
titoliDiStudio: [ 'Diploma', 'Laurea Magistrale' ]
}
id: 1,
nome: 'Paola',
cognome: 'Verdi',
luogoDiNascita: 'Roma',
dataDiNascita: 1990-10-04T23:00:00.000Z,
sesso: true,
codiceFiscale: 'pllvrd90l05l234f',
titoliDiStudio: [ 'Diploma', 'Laurea' ]}
15
33
53
67
91
65
79
35
L'argomento del metodo filter è una funzione lambda, una funzione anonima che riceve come argomenti di volta in volta, tutti i valori dell'array e ritorna solo quelli dispari:
// Funzione lambda
(numero:number) => {
if(numero%2!=0){
return numero; // Aggiunge al nuovo array solo i valori che soddisfano la condizione
}
}
Il simbolo => è detto freccia, si usa per associare gli argomenti della funzione lambda all'implementazione.
VISUALIZZA IL TOTALE DEI NUMERI DISPARI
La funzione lambda del metodo reduce, viene eseguita per ogni elemento dell'array. Il primo argomento della funzione è un accumulatore, conserva il valore del calcolo precedente, mentre il secondo argomento, corrisponde al valore corrente dell'array.
CALCOLA IL CUBO DEI VALORI DELL'ARRAY
125
3375
27000
35937
8000
148877
300763
474552
729000
753571
941192
343000
274625
493039
1728
2744
5832
42875
512000
TOTALE DEL CUBO DEI NUMERI PARI DELL'ARRAY
=>somma+numero);
VISUALIZZA L'ETA' MEDIA DELLE DONNE CON LAUREA INSERITE NELL'ARRAY
femmineLaureate.length;
Età media:25.75
Nella prossima lezione vedremo tutti i tipi di funzioni disponibili in TypeScript.
<< Lezione precedente Lezione successiva >> | Vai alla prima lezione
T U T O R I A L S S U G G E R I T I
- Impariamo Python giocando al "Solitario del ferroviere"
- Impariamo a programmare con JavaScript
- Laboratori di Logica di programmazione in C
- Introduzione alla Logica degli oggetti
- Ricominciamo ... dal Linguaggio SQL
- APP Mania
- Come sviluppare un Sito con Wordpress
- Excel delle meraviglie
EDUCATIONAL GAMING BOOK (EGB) "H2O"
Nell'era dello SMART LEARNING e di PYTHON i libri non si scrivono, ma si sviluppano, in questo modo chi studia, può sperimentare ed apprendere contemporaneamente; un libro con queste caratteristiche lo possiamo definire un Educational Gaming Book (EGB).
"H2O" è un EGB che descrive tutte le caratteristiche dell'acqua, la sostanza formata da molecole di H2O, che attraverso il suo ciclo di vita garantisce la sopravvivenza di tutti gli esseri viventi del Pianeta.
L'obiettivo dell'EGB è quello di far conoscere ai giovani le proprietà dell'acqua, sotto molti aspetti uniche, per sensibilizzarli a salvaguardare un bene comune e raro, indispensabile per la vita.
Per il DOWNLOAD di "H2O" clicca qui.
TypeScript - Lezione 2: Tipi di dati.
![]() Gino Visciano |
Skill Factory - 10/06/2020 16:07:16 | in Tutorials
Gino Visciano |
Skill Factory - 10/06/2020 16:07:16 | in Tutorials
TypeScript a differenza di Javascript, permette di dichiarare le variabili con 3 tipi di dati primitivi:
- number (interi e decimali);
- string (caratteri alfanumerici);
- boolean (true e false).
L'esempio seguente mostra come si dichiarano e si assegnano valori alle variabili in TypeScript:
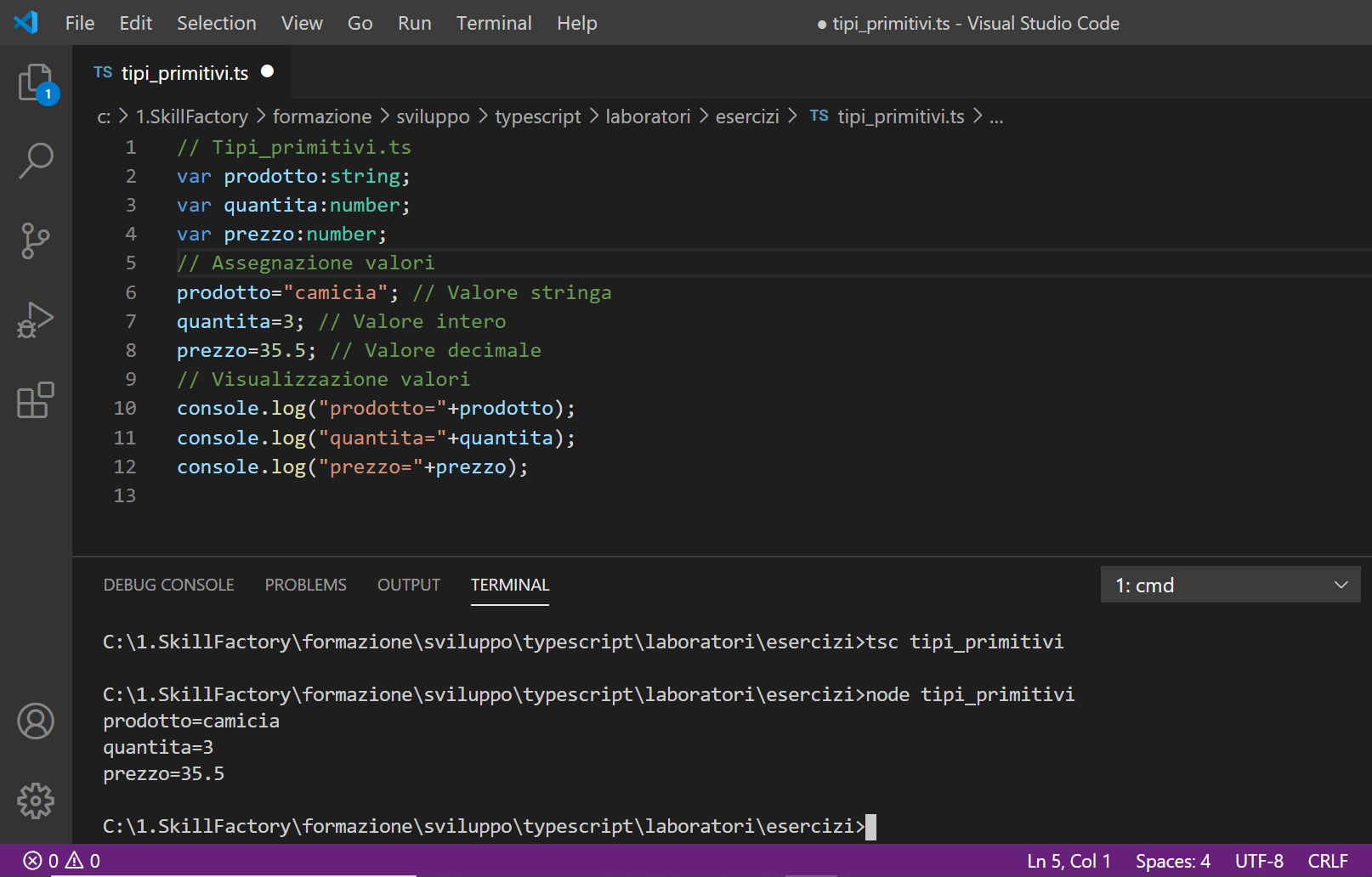
Il comando var rende la variabile di tipo globale nel modulo in cui viene dichiarata.
COME DICHIARARE UNA VARIABILE A CUI ASSEGNARE QUALUNQUE TIPO DI VALORE
Una variabile a cui si può assegnare qualunque tipo di valore è di tipo "Variant".
In TypeScript il tipo "Variant" corrisponde al tipo di dato any.
Ad esempio alle variabili seguenti potete assegnare qualunque tipo di valore:
// Dichiarazione
var valoreQualunqueUno:any;
var valoreQualunqueDue:any;
var valoreQualunqueTre:any;
var valoreQualunqueQuattro:any;
// Inizializzazione
valoreQualunqueUno=30;
valoreQualunqueDue=10.80;
valoreQualunqueTre:any="Arancione"
valoreQualunqueQuattro=true;
// Visualizzazione
console.log(valoreQualunqueUno);
console.log(valoreQualunqueDue);
console.log(valoreQualunqueTre);
console.log(valoreQualunqueQuattro)
COME DICHIARARE UNA VARIABILE DI TIPO DATA
In TypeScript il tipo data non è un tipo di dato primitivo, ma una classe.
Per riconoscere se un tipo di dato è primitivo oppure è una classe è semplice, i nomi dei tipi primitivi sono minuscoli mentre le classi iniziano sempre con una lettere maiuscola, come mostra l'esempio seguente:
var nome:string // Tipo di dato primitivo
var dataDiNascita:Date //Tipo Classe
Le variabili di tipo classe, possono contenere sia valori, sia funzioni, chiamate metodi, che servono per fare operazioni sul valori memorizzati. Le variabile di tipo classe sono chiamate oggetti e si inizializzano con il comando new, come mostra l'esempio seguente:
var gg=number; // Variabile
var mm=number; // Variabile
var aaaa=number; // Variabile
var dataDiNascita=new Date("10/05/1990"); // Oggetto perché oltre ai valori può contienere anche metodi
gg=dataDiNascita.getData(); // Uso di un metodo che fornisce il giorno della data inserita
mm=dataDiNascita.getMonth(); // Uso di un metodo che fornisce il mese della data inserita
aaaa=dataDiNascita.gerFullYear(); // Uso di un metodo che fornisce l'anno della data inserita
console.log(gg+"/"+mm+"/"+aaaa);
COME LAVORARE CON GLI ARRAY
In TypeScript gli array si dichiarano come le variabili, l'unica differenza è che al tipo di dato , sia di tipo primitivo, sia di tipo classe, dovete aggiungere una coppia di parentesi quadre, come mostra l'esempio seguente:
var valori:number[]; // Array di tipo number, può contenere molti valori interi oppure decimali
Per dichiarare un array vuoto dovete usare la sintassi seguente:
var valori:number[]=[]; // Dichiarazione e inizializzazione
oppure
var valori:number[]; // Dichiarazione
valori=[]; // Inizializzazione
Per assegnare dei valori ad un array potete usare la sintassi seguente:
var valori:number[]=[10,5,20,15,30]; // Dichiarazione e inizializzazione
oppure
var valori:number[]; // Dichiarazione
valori=[10,5,20,15,30]; // Inizializzazione
Dopo aver dichiarato ed inizializzato un array, per aggiungere nuovi valori, dovete usare il metodo push():
valori.push(50);
valori.push(40);
valori.push(35);
valori.push(25);
valori.push(45);
Tutti i valori di un array sono identificati da un indice numerico. Il primo valore corrisponde all'indice 0, l'ultimo valore corrisponde all'indice n-1, dove n è il numero di valori inserito nell'array.
L'attributo length contiene il numero di valori inseriti in un array (n).
Per visualizzare il contenuto di un array potete utilizzare un ciclo for, come mostra l'esempio seguente:
for(let x:number=0;x<valori.length;x++){
console.log(valori[x]);
}


// valori_inserimento.ts
var valori:number[]=[10,5,20,15,30];
valori.push(50);
valori.push(40);
valori.push(35);
valori.push(25);
valori.push(45);
for(let x:number=0;x<valori.length;x++){
console.log(valori[x]);
}
Salvate il file con il nome valori_inserimento.ts:
tsc valori_inserimento
node valori_inserimento
---------- OUTPUT ----------
Valori inseriti:10
10
5
20
15
30
50
40
35
25
45
Per modificare una valore inserito in un array dovete prima conoscere in quale posizione si trova (indice) e successivamente lo potete sostituire con il nuovo valore.
Esempio 2
// nominativi_modifica.ts
var nominativi:string[]=[];
nominativi.push("Paola Rossi");
nominativi.push("Ugo Verdi");
nominativi.push("Mara Bianchi");
nominativi.push("Marco Borriello");
nominativi.push("Roberta Di Donna");
for(let x:number=0;x<nominativi.length;x++){
console.log((x+1)+") "+nominativi[x]);
}
nominativi[4]="Carla Miranda"; // Modifica dell'ultimo (quinto) elemento dell'array con indice=4
for(let x:number=0;x<nominativi.length;x++){
console.log((x+1)+") "+nominativi[x]); // (x+1) +")" permette di ottenere un elenco numerato
}
tsc nominativi_modifica
node nominativi_modifica
---------- OUTPUT ----------
Nominativi inseriti:5
1) Paola Rossi
2) Ugo Verdi
3) Mara Bianchi
4) Marco Borriello
5) Roberta Di Donna
Nominativi inseriti:5
1) Michela De Pretis
2) Ugo Verdi
3) Francesco Ferrara
4) Marco Borriello
5) Carla Miranda
Per eliminare un valore inserito in un array, dovete usare il metodo splice(indice,quanti), dove:
indice=posizione nell'array da dove iniziare ad eliminare;
quanti=quanti valori eliminare partendo dalla posizione indice.
Esempio 3
// nominativi_elimina.ts
var nominativi:string[]=[];
nominativi.push("Paola Rossi");
nominativi.push("Ugo Verdi");
nominativi.push("Mara Bianchi");
nominativi.push("Marco Borriello");
nominativi.push("Roberta Di Donna");
for(let x:number=0;x<nominativi.length;x++){
console.log((x+1)+") "+nominativi[x]);
}
nominativi.splice(2,1) // Elimina il terzo nominativo dall'array
for(let x:number=0;x<nominativi.length;x++){
console.log((x+1)+") "+nominativi[x]);
}
---------- COMPILAZIONE ED ESECUZIONE ----------
tsc nominativi_elimina
node nominativi_elimina
---------- OUTPUT ----------
Nominativi inseriti:5
1) Paola Rossi
2) Ugo Verdi
3) Mara Bianchi
4) Marco Borriello
5) Roberta Di Donna
Nominativi inseriti:4
1) Paola Rossi
2) Ugo Verdi
3) Marco Borriello
4) Roberta Di Donna
COME CREARE UN TIPO CLASSE PER ISTANZIARE OGGETTI
Un tipo classe è un tipo di dato definito dal programmatore, si differenzia dai tipi primitivi number, string e boolean, perché permette di memorizzare più informazioni contemporaneamente, come avviene per le strutture in C.
Le classi a differenza delle strutture, possono contenere anche funzioni, chiamate metodi, che permettono di eseguire operazioni sulle informazioni memorizzate.

I costruttori sono funzioni come i metodi che si usano durante la creazione degli oggetti (istanza) e servono per inizializzare i suoi attributi.
valoreDue:tipo; // Attributo = variabile globale
// tipo è void se il metodo non restituisce (return) un valore, altrimenti corrisponde al tipo del valore restituito
metodoDue():tipo{
// Attenzione a differenza degli altri metodi il costruttore non può restituire valori, quindi non dovete indicare il tipo restituito
2) I nomi degli attributi, dei metodi e dei costruttori, hanno sempre la prima parola minuscola, se sono composti da più parole, le successive iniziano con la lettera maiuscola:valoreUno e metodoUno;
3) Quando create un costruttore, a differrenza dei metodi, non dovete indicare i tipo restituito.
personaUno=Nome oggetto che permette di memorizzare valori negli attributi ed eseguire operazioni eseguendo i metodi;
new=comando che crea in memoria l'oggetto. Questa operazione è detta istanza;
Persona()=Costruttore, metodo utilizzato per inizializzare gli attributi dell'oggetto.
// Dichiarazione della Classe da utilizzare come tipo per istanziare oggetti
// gestione_persone.ts
class Persona{
nome:string;
cognome:string;
luogoDiNascita:string;
dataDiNascita:Date;
sesso:boolean;
toString():string{
var gg:number=this.dataDiNascita.getDate();
var mm:number=this.dataDiNascita.getMonth()+1;
var aaaa:number=this.dataDiNascita.getFullYear();
var dataValore:string=gg+"/"+mm+"/"+aaaa;
var sessoValore:string="";
if(this.sesso){
sessoValore="Maschio";
} else{
sessoValore="Femmina"
}
return this.nome+","+this.cognome+","+this.luogoDiNascita+","+dataValore+","+sessoValore;
}
constructor(){} // In questo caso il costruttore non contiene codice d'inizializzazione, verrà usato solo per istanziare oggetti di tipo Persona
}
// Istanza di tre oggetti di tipo Persona
var personaUno:Persona=new Persona();
var personaDue:Persona=new Persona();
var personaTre:Persona=new Persona();
personaUno.nome="Mario";
personaUno.cognome="Rossi";
personaUno.luogoDiNascita="Milano";
//Mese, Giorno e Anno
personaUno.dataDiNascita=new Date("12/5/1990");
personaUno.sesso=true;
personaDue.nome="Paola";
personaDue.cognome="Verdi";
personaDue.luogoDiNascita="Napoli";
//Mese, Giorno e Anno
personaDue.dataDiNascita=new Date("9/10/1998");
personaDue.sesso=false;
personaTre.nome="Roberta";
personaTre.cognome="Bianchi";
personaTre.luogoDiNascita="Roma";
//Mese, Giorno e Anno
personaTre.dataDiNascita=new Date("1/12/1995");
personaTre.sesso=false;
console.log(personaUno.toString());
console.log(personaDue.toString());
console.log(personaTre.toString());
---------- COMPILAZIONE ED ESECUZIONE ----------
tsc gestione_persone
node gestione_persone
---------- OUTPUT ----------
Mario,Rossi,Milano,5/12/1990,Maschio
Paola,Verdi,Napoli,10/9/1998,Femmina
Roberta,Bianchi,Roma,12/1/1995,Femmina
Esempio 5
//rettangolo.ts
class Rettangolo {
latoA:number;
latoB:number;
getPerimetro():number{
return 2*(this.latoA+this.latoB);
}
getArea():number{
return this.latoA*this.latoB;
}
constructor(latoA:number,latoB:number){
this.latoA=latoA;
this.latoB=latoB;
}
}
var rettangolo:Rettangolo=new Rettangolo(10,20);
console.log("Perimetro:"+rettangolo.getPerimetro());
console.log("Area:"+rettangolo.getArea());
---------- COMPILAZIONE ED ESECUZIONE ----------
tsc rettangolo
node rettangolo
---------- OUTPUT ----------
Perimetro:60
Area:200
COME LAVORARE CON UNA STRUTTURA JSON (JavaScript Object Notation)
In TypeScript una struttura JSON può essere definita come una variabile multivalore.
JSON è il nuovo formato testo (NOSQL) per organizzare dati, indipendente dal linguaggio di programmazione usato, molto utile per scambiare dati tra applicazioni scritte con linguaggi di programmazione diversi.
JSON è il formato di raccolta ed organizzazione dei dati più usato nel mondo dei Big Data, dove è molto diffuso l'uso di database NOSQL, come MONGODB, che usano strutture JSON al posto delle classiche tabelle usate nei database SQL (Relazionali).
Per dichiarare una struttura JSON, dovete indicare in una coppia di parentesi graffe tutte le variabili che la compongono, come mostra l'esempio seguente:
var persona:{id:number, nome:string, cognome:string, luogoDiNascita:string, dataDiNascita:Date,sesso:boolean, codiceFiscale:string, titoliDiStudio:string[]};
Esempio 6
// gestione_persone_json_01.ts
var personaUno:{id:number, nome:string, cognome:string, luogoDiNascita:string, dataDiNascita:Date,sesso:boolean, codiceFiscale:string, titoliDiStudio:string[]}; // Dichiarazione di una struttura JSON
var personaDue:{id:number, nome:string, cognome:string, luogoDiNascita:string, dataDiNascita:Date,sesso:boolean, codiceFiscale:string, titoliDiStudio:string[]}; // Dichiarazione di una struttura JSON
personaUno={id:1,nome:"Paola",cognome:"Verdi",luogoDiNascita:"Roma",dataDiNascita:new Date("10/05/1990"),sesso:true,codiceFiscale:"pllvrd90l05l234f",titoliDiStudio:["Diploma","Laurea"]}; // Assegnazione dei dai ad una struttura JSON
personaDue={id:2,nome:"Marco",cognome:"Rossi",luogoDiNascita:"Napoli",dataDiNascita:new Date("1/5/1996"),sesso:false,codiceFiscale:"mrcrss96l01l256g",titoliDiStudio:["Diploma","Laurea Triennale","Laurea Magistrale"]}; // Assegnazione dei dai ad una struttura JSON
console.log(personaUno);
console.log(personaDue);
---------- COMPILAZIONE ED ESECUZIONE ----------
tsc gestione_persone_json_01
node gestione_persone_json_01
---------- OUTPUT ----------
{
id: 1,
nome: 'Paola',
cognome: 'Verdi',
luogoDiNascita: 'Roma',
dataDiNascita: 1990-10-04T23:00:00.000Z,
sesso: true,
codiceFiscale: 'pllvrd90l05l234f',
titoliDiStudio: [ 'Diploma', 'Laurea' ]
}
{
id: 2,
nome: 'Marco',
cognome: 'Rossi',
luogoDiNascita: 'Napoli',
dataDiNascita: 1996-01-04T23:00:00.000Z,
sesso: false,
codiceFiscale: 'mrcrss96l01l256g',
titoliDiStudio: [ 'Diploma', 'Laurea Triennale', 'Laurea Magistrale' ]
}
L'output mostra i dati delle due persone secondo la convenzione JSON.
COME CREARE UN'INTERFACCIA PER DICHIARARE UNA STRUTTURA JSON (JavaScript Object Notation)
Per dichiarare una struttura JSON, potete anche usare un'interfaccia che contiene le dichiarazioni di tutte le variabili che la compongono.
Per creare un'interfaccia, dovete usare la parola chiave interface, come mostra l'esempio seguente:
interface PersonaJSON{
id:number,
nome:string,
cognome:string,
luogoDiNascita:string,
dataDiNascita:Date,
sesso:boolean,
codiceFiscale:string,
titoliDiStudio:string[]
}
In questo caso avete creato il tipo di dato PersonaJSON, che serve per dichiarare strutture JSON che contengono le informazioni inserite nell'interfaccia.
Esempio 7
// gestione_persone_json_02.ts
interface PersonaJSON{
id:number,
nome:string,
cognome:string,
luogoDiNascita:string,
dataDiNascita:Date,
sesso:boolean,
codiceFiscale:string,
titoliDiStudio:string[]
}
var personaUno:PersonaJSON;
var personaDue:PersonaJSON;
personaUno={id:1,nome:"Paola",cognome:"Verdi",luogoDiNascita:"Roma",dataDiNascita:new Date("10/05/1990"),sesso:true,codiceFiscale:"pllvrd90l05l234f",titoliDiStudio:["Diploma","Laurea"]};
personaDue={id:2,nome:"Marco",cognome:"Rossi",luogoDiNascita:"Napoli",dataDiNascita:new Date("1/5/1996"),sesso:false,codiceFiscale:"mrcrss96l01l256g",titoliDiStudio:["Diploma","Laurea Triennale","Laurea Magistrale"]};
console.log(personaUno);
console.log(personaDue);
---------- COMPILAZIONE ED ESECUZIONE ----------
tsc gestione_persone_json_02
node gestione_persone_json_02
---------- OUTPUT ----------
{
id: 1,
nome: 'Paola',
cognome: 'Verdi',
luogoDiNascita: 'Roma',
dataDiNascita: 1990-10-04T23:00:00.000Z,
sesso: true,
codiceFiscale: 'pllvrd90l05l234f',
titoliDiStudio: [ 'Diploma', 'Laurea' ]
}
{
id: 2,
nome: 'Marco',
cognome: 'Rossi',
luogoDiNascita: 'Napoli',
dataDiNascita: 1996-01-04T23:00:00.000Z,
sesso: false,
codiceFiscale: 'mrcrss96l01l256g',
titoliDiStudio: [ 'Diploma', 'Laurea Triennale', 'Laurea Magistrale' ]
}
Esempio 8
// gestione_persone_json_03.ts
interface PersonaJSON{
id:number,
nome:string,
cognome:string,
luogoDiNascita:string,
dataDiNascita:Date,
sesso:boolean,
codiceFiscale:string,
titoliDiStudio:string[]
}
var persone:PersonaJSON[]=[]; // Array si strutture JSON di tipo PersonaJSON
persone.push({id:1,nome:"Paola",cognome:"Verdi",luogoDiNascita:"Roma",dataDiNascita:new Date("10/05/1990"),sesso:true,codiceFiscale:"pllvrd90l05l234f",titoliDiStudio:["Diploma","Laurea"]});
persone.push({id:2,nome:"Marco",cognome:"Rossi",luogoDiNascita:"Napoli",dataDiNascita:new Date("1/5/1996"),sesso:false,codiceFiscale:"mrcrss96l01l256g",titoliDiStudio:["Diploma","Laurea Triennale","Laurea Magistrale"]});
persone.push({id:3,nome:"Ugo",cognome:"Bianchi",luogoDiNascita:"Milano",dataDiNascita:new Date("7/9/2000"),sesso:false,codiceFiscale:"uggbnc00q07l246e",titoliDiStudio:["Diploma","Laurea Triennale"]});
for(let x:number=0;x<persone.length;x++){
console.log(persone[x]);
}
---------- COMPILAZIONE ED ESECUZIONE ----------
tsc gestione_persone_json_03
node gestione_persone_json_03
---------- OUTPUT ----------
{
id: 1,
nome: 'Paola',
cognome: 'Verdi',
luogoDiNascita: 'Roma',
dataDiNascita: 1990-10-04T23:00:00.000Z,
sesso: true,
codiceFiscale: 'pllvrd90l05l234f',
titoliDiStudio: [ 'Diploma', 'Laurea' ]
}
{
id: 2,
nome: 'Marco',
cognome: 'Rossi',
luogoDiNascita: 'Napoli',
dataDiNascita: 1996-01-04T23:00:00.000Z,
sesso: false,
codiceFiscale: 'mrcrss96l01l256g',
titoliDiStudio: [ 'Diploma', 'Laurea Triennale', 'Laurea Magistrale' ]
}
{
id: 3,
nome: 'Ugo',
cognome: 'Bianchi',
luogoDiNascita: 'Milano',
dataDiNascita: 2000-07-08T22:00:00.000Z,
sesso: false,
codiceFiscale: 'uggbnc00q07l246e',
titoliDiStudio: [ 'Diploma', 'Laurea Triennale' ]
}
Nella prossima lezione approfondiremo la conoscenza degli array.
<< Lezione precedente Lezione successiva >> | Vai alla prima lezione
T U T O R I A L S S U G G E R I T I
- Impariamo Python giocando al "Solitario del ferroviere"
- Impariamo a programmare con JavaScript
- Laboratori di Logica di programmazione in C
- Introduzione alla Logica degli oggetti
- Ricominciamo ... dal Linguaggio SQL
- APP Mania
- Come sviluppare un Sito con Wordpress
- Excel delle meraviglie
EDUCATIONAL GAMING BOOK (EGB) "H2O"
Nell'era dello SMART LEARNING e di PYTHON i libri non si scrivono, ma si sviluppano, in questo modo chi studia, può sperimentare ed apprendere contemporaneamente; un libro con queste caratteristiche lo possiamo definire un Educational Gaming Book (EGB).
"H2O" è un EGB che descrive tutte le caratteristiche dell'acqua, la sostanza formata da molecole di H2O, che attraverso il suo ciclo di vita garantisce la sopravvivenza di tutti gli esseri viventi del Pianeta.
L'obiettivo dell'EGB è quello di far conoscere ai giovani le proprietà dell'acqua, sotto molti aspetti uniche, per sensibilizzarli a salvaguardare un bene comune e raro, indispensabile per la vita.
Per il DOWNLOAD di "H2O" clicca qui.
TypeScript - Lezione 1: Come iniziare.
![]() Gino Visciano |
Skill Factory - 05/06/2020 22:53:20 | in Tutorials
Gino Visciano |
Skill Factory - 05/06/2020 22:53:20 | in Tutorials
 TypeScript è il nuovo linguaggio di programmazione creato nel 2012 dalla Microsoft, che permette anche ai programmatori di applicazioni front-end (client-side) di sviluppare con il paradigama Object Oriented, in modo molto simile a Java e C#.
TypeScript è il nuovo linguaggio di programmazione creato nel 2012 dalla Microsoft, che permette anche ai programmatori di applicazioni front-end (client-side) di sviluppare con il paradigama Object Oriented, in modo molto simile a Java e C#.
Le applicazioni sviluppate con TypeScript quando vengono compilate, sono tradotte in JavaScript e possono essere eseguite con Node.js oppure possono essere importate in una pagina HTML.
TypeScript è il linguaggio usato da Angular, il framework più utilizzato per creare applicazioni Web, quindi se lo conoscete sarà più semplice impareare ad usarlo.
COME INSTALLARE TYPESCRIPT
Per iniziare a sviluppare con TypeScript dovete prima installare Node.js:
1) collegatevi all'indirizzo: https://node.js/it/download ed eseguite il download di Node.js;
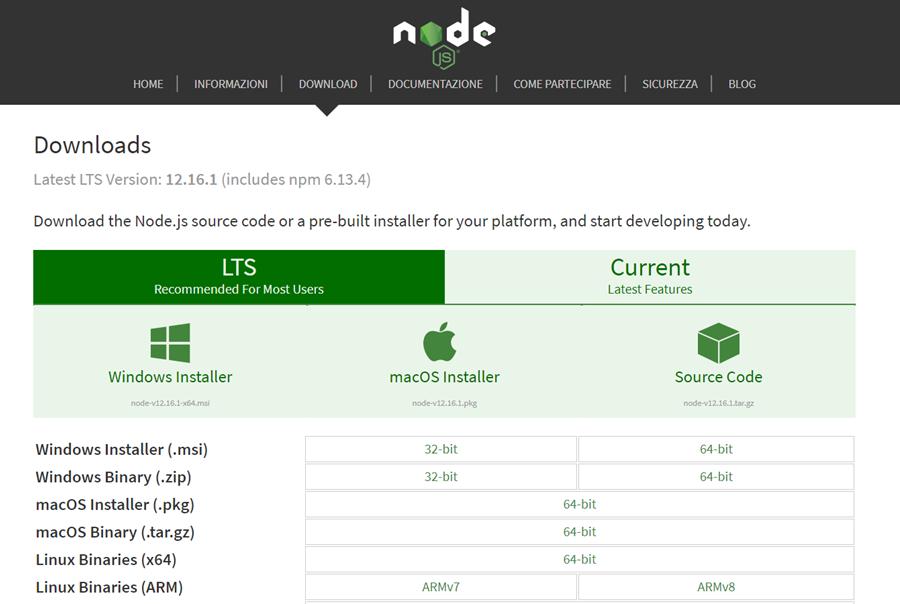
2) dopo il download eseguite il file di setup per installare Node.js;

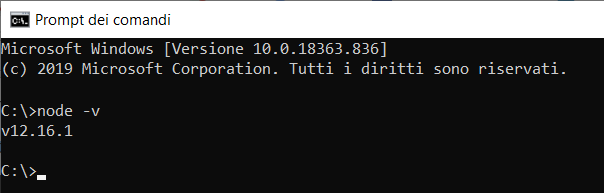
3) al completamento per verificare se Node.js è stato installato correttamente usate il comando node -v:
Dopo l'installazione di Node.js, potete installare TypeScript il comando:
npm install -g typescript
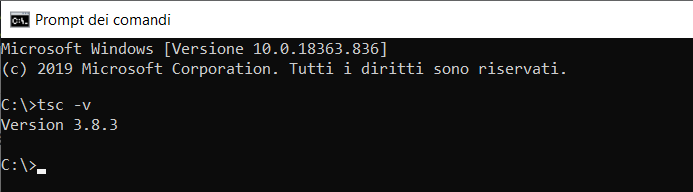
Per verificare se TypeScript è stato installato correttamente usate il comando tsc -v:
COME INSTALLARE L'IDE (INTEGRATED DEVELOPMENT ENVIRONMENT)
Per sviluppare applicazioni con TypeScript vi suggerisco di utilizzare Visual Studio Code, l'ambiente di sviluppo integrato creato da Microsoft, molto semplice da usare e molto performante.
Per installare Visual Studio Code procedete nel modo seguente:
1) collegatevi al sito: https://code.visualstudio.com;
2) dopo il download eseguite il file di setup per installare Visual Studio Code;
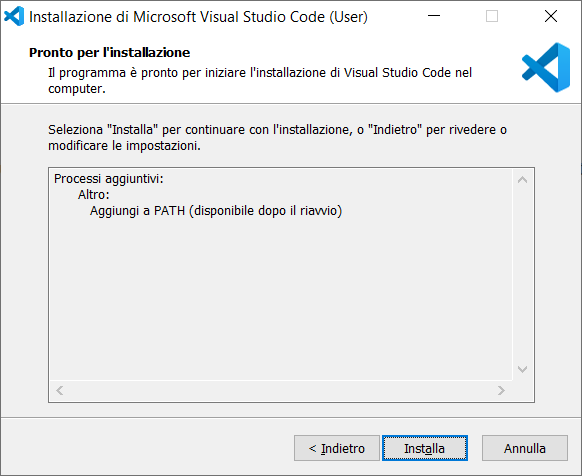
3) per avviare Visual Studio Code fate doppio click sull'icona:
Visual Studio Code
COME CREARE ED ESEGUIRE LA PRIMA APPLICAZIONE TYPESCRIPT
Per testare l'installazione di TypeScript, su C: create una nuova cartella e chiamatela esercizi_ts.
Avviate Visual Studio Code ed aprite un nuovo file, come mostra l'immagine seguente:
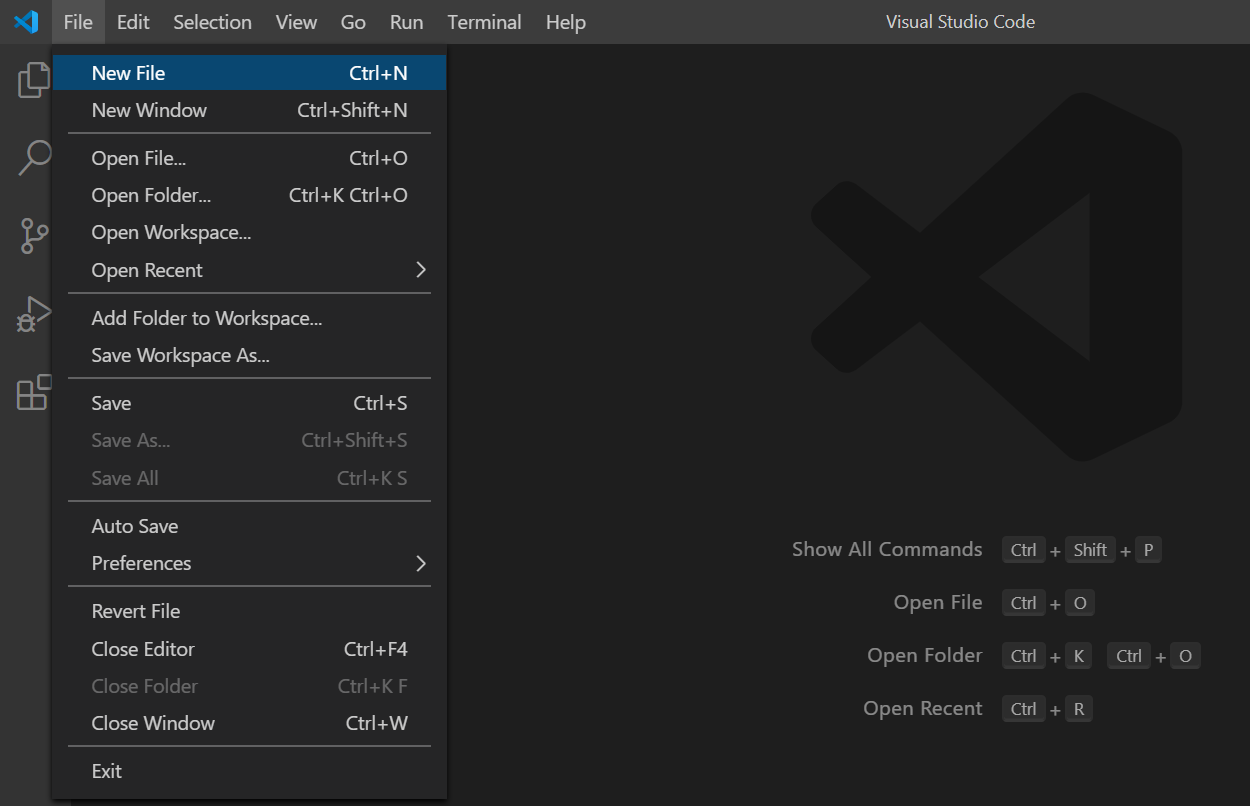
Per creare un nuovo file potete anche usare i tasti Ctrl+N.
All'interno del file scrivete l'istruzione seguente:
console.log("Hello World!");
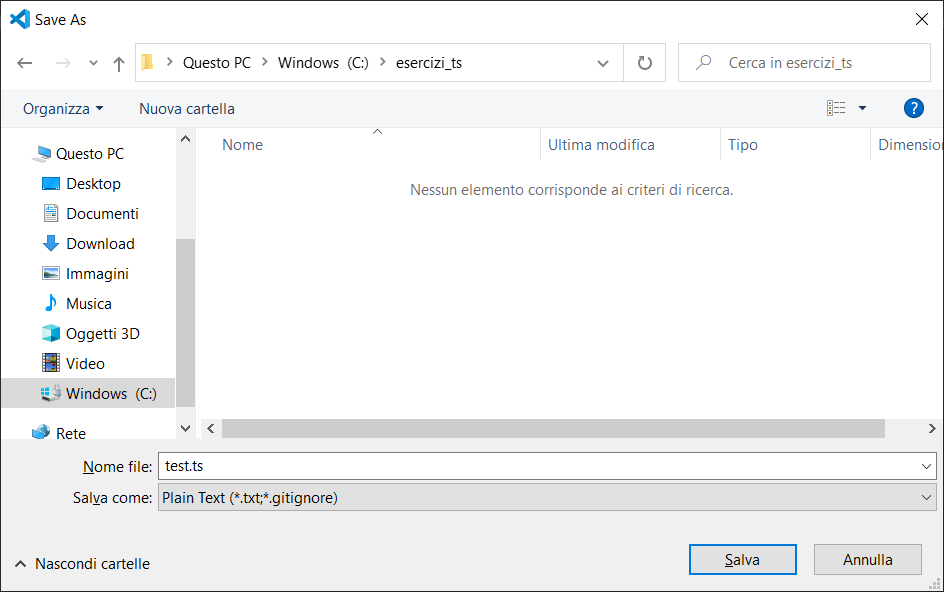
Per salvare il file usate i tasti Ctrl+S oppure usate il menu File, chiamate il file test.ts, come mostra l'immagine seguente:
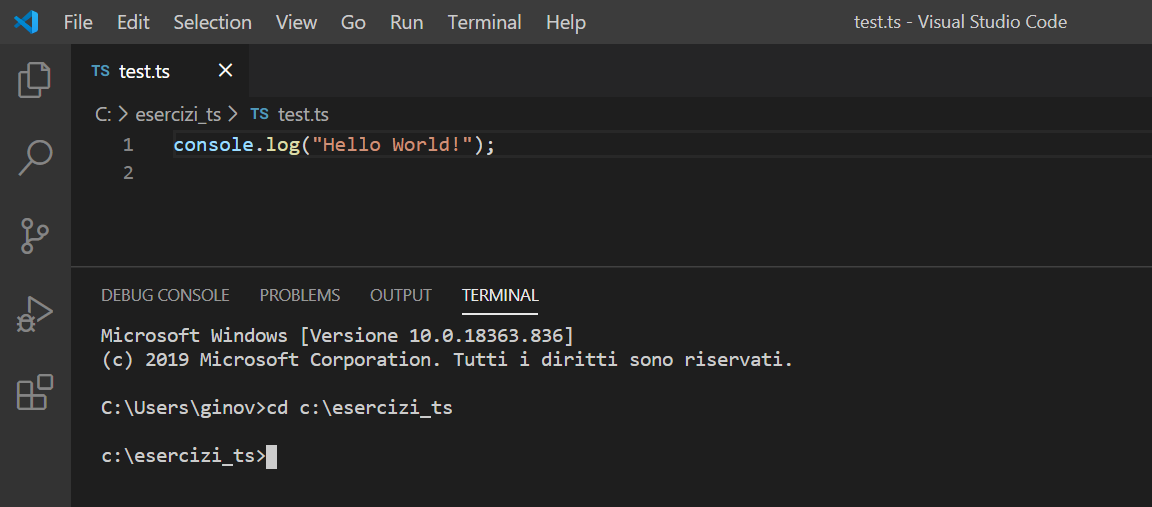
Per compilare ed eseguire il programma test.ts, attivate il terminale con i tasti Ctrl +ò oppure usate il menu Terminal e spostatevi nella cartella c:\esercizi_ts, con il comando cd c:\esercizi_ts come mostra l'immagine seguente:
Per eseguire un programma scritto in TypeScript lo dovete prima compilare, con il comando tsc, come mostra l'esempio seguente:
tsc test.ts
La compilazione è semplicemente la traduzione in linguaggio JavaScript, del programma scritto in TypeScript, quindi dopo la compilazione nella cartella c:\esercizi_ts verrà aggiunto anche il file test.js con il codice JavaScript.
A questo punto ottenuto il file JavaScript, lo potete eseguire con il comando:
node test
L'immagine seguente mostra il risultato dell'esecuzione:
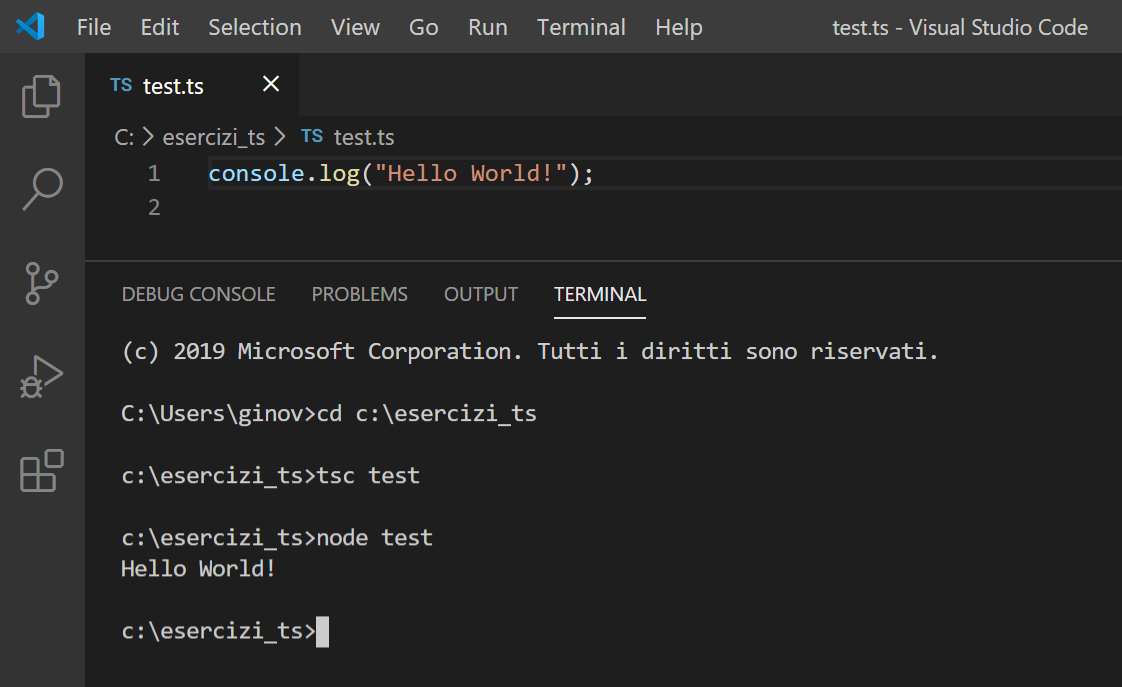
Nella prossima lezione vedremo i tipi di dati di TypeScript.
T U T O R I A L S S U G G E R I T I
- Impariamo Python giocando al "Solitario del ferroviere"
- Impariamo a programmare con JavaScript
- Laboratori di Logica di programmazione in C
- Introduzione alla Logica degli oggetti
- Ricominciamo ... dal Linguaggio SQL
- APP Mania
- Come sviluppare un Sito con Wordpress
- Excel delle meraviglie
EDUCATIONAL GAMING BOOK (EGB) "H2O"
Nell'era dello SMART LEARNING e di PYTHON i libri non si scrivono, ma si sviluppano, in questo modo chi studia, può sperimentare ed apprendere contemporaneamente; un libro con queste caratteristiche lo possiamo definire un Educational Gaming Book (EGB).
"H2O" è un EGB che descrive tutte le caratteristiche dell'acqua, la sostanza formata da molecole di H2O, che attraverso il suo ciclo di vita garantisce la sopravvivenza di tutti gli esseri viventi del Pianeta.
L'obiettivo dell'EGB è quello di far conoscere ai giovani le proprietà dell'acqua, sotto molti aspetti uniche, per sensibilizzarli a salvaguardare un bene comune e raro, indispensabile per la vita.
Per il DOWNLOAD di "H2O" clicca qui.
Il COVID-19 sembra meno aggressivo è il risultato del Lockdown oppure ci sono delle causa naturali che ci obbligano a stare in guardia?
![]() Gino Visciano |
Skill Factory - 03/06/2020 07:47:36 | in Home
Gino Visciano |
Skill Factory - 03/06/2020 07:47:36 | in Home
 A tenere banco in questi giorni sono le parole del primario del San Raffaele, Alberto Zangrillo, che ha definito il Covid "morto dal punto di vista clinico".
A tenere banco in questi giorni sono le parole del primario del San Raffaele, Alberto Zangrillo, che ha definito il Covid "morto dal punto di vista clinico".
Osservando le statistiche, i dati sembrano dargli ragione, perché sia il numero di morti che i contagiati sono diminuiti e in 8 regioni non c'è nessun nuovo caso.
Ma la minore aggressività del virus è il risultato del lockdown oppure ci sono delle causa naturali?
Probabilmente gli effetti negativi del virus sono stati attenuati da cause naturali e quindi sarebbe opportuno non abbassare la guardia.
La spiegazione potrebbe essere di tipo astronomico!
Durante i mesi estivi l'altezza del Sole rispetto all'orizzonte aumenta, raggiungendo il punto massimo il 21 giugno, giorno del solstizio d'estate.
In questo periodo i raggi del sole raggiungono la Terra quasi in modo perpendicolare e sono molto intensi.
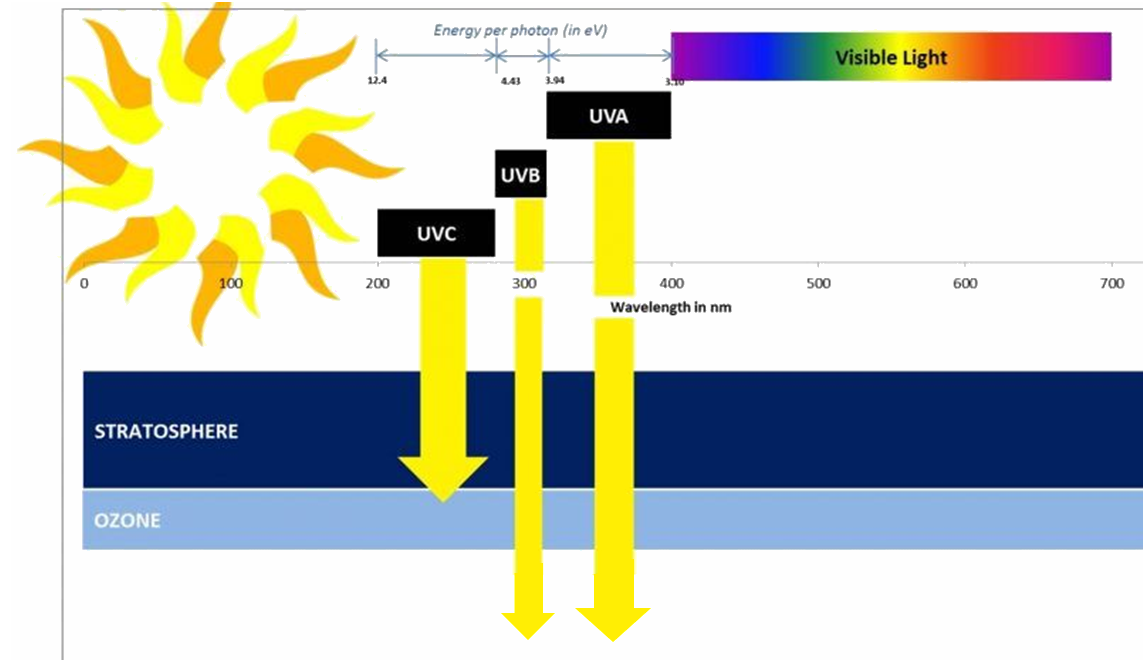
La radiazione solare è composta da diverse frequenze delle spettro delle onde elettromagnetiche ed oltre alla radiazione visibile (luce), emette anche raggi ultravioletti (UV).
Lo spettro UV, ha una lunghezza d’onda compresa tra i 200 e i 400 nm (nanometro) ed è altamente efficace ad eliminare dall’ambiente batteri e virus, limitando la trasmissione aerea di questi patogeni ed agenti infettivi.
L'uso dei raggi ultravioletti è molto diffuso nei laboratori per sterilizzare gli strumenti e le apparecchiature mediche.
Questo spiegherebbe anche perché nelle città molto inquinate gli effetti del COVID sono molto maggiori. L'ozono è lo scudo del Pianeta contro alcuni tipi di raggi ultravioletti provenienti dal Sole, gli ossidi di azoto (NOx), emessi principalmente dal traffico, dalla produzione di energia, dalla produzione di calore per i processi produttivi e per il riscaldamento degli ambienti, aumentano la concentrazione di ozono nell'atmosfera.
Le reazioni che portano alla formazione dell'Ozono nell'ambiente, generano anche piccole quantità di altre sostanze ossidanti che formano la miscela chiamata usualmente smog fotochimico, di cui l'ozono è comunque la componente principale.
L'alta quantità di smog fotochimico oltre a bloccare i raggi UV letali per gli esseri viventi, potrebbe bloccare anche quelle frequenze che invece sono letali solo per i virus ed i batteri, favorendo la loro diffusione.
Se questa ipotesi fosse giusta, dobbiamo sperare che durante i mesi estivi il virus venga distrutto completamente dai raggi UV, altrimenti è possibile che durante i mesi invernali, attenuandosi l'effetto dei raggi UV, il virus ritorni ad essere aggressivo come prima.
 FILTRI
FILTRI


 Offerte di Lavoro
Offerte di Lavoro
 Post più recenti
Post più recenti
-

Full Stack Developer
07/05/2026
-
1° MAGGIO: FESTA DEL LAVORO E DELLA FORMAZIONE
01/05/2026
-
Operatore Amministrativo Contabile
09/04/2026
-
Tecnico Programmatore: Il Profilo più richiesto dai giovani che frequentano la nostra Academy
17/03/2026
-
6.L'Assicurazione della Qualità nell'IFP
24/01/2026
-
Skill Factory 2025: Un anno di formazione tra "Innovazione (AI), Qualità (EQAVET) e Politiche Attive del Lavoro (PAR GOL)"
30/12/2025
-
10.Intelligenza Artificiale: cosa cambia nel mondo del lavoro
21/12/2025
-
5.L’etica della formazione come responsabilità professionale
13/12/2025
-
4.Buona Formazione: "Come assicurare la Qualità della Formazione"
06/12/2025
-
Corso gratuito di 60 ore per creare le competenze digitali fondamentali (DIGCOMP2.2)
25/09/2025