





-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-





 Scheda Azienda
Scheda Azienda Eventi formazione
Eventi formazione Offerta formativa
Offerta formativa Lavora con noi
Lavora con noi
 Richiedi informazioni
Richiedi informazioni
Skill Factory
Categoria: Formazione e lavoro
Formiamo e assumiamo programmatori APEX in ambito Salesforce, partecipa anche tu alla Skill Factory "Apex Developer"
![]() Gino Visciano |
Skill Factory - 27/10/2020 00:04:04 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 27/10/2020 00:04:04 | in Formazione e lavoro
CHE COS'E' SALESFORCE
 Salesforce è nato nel 1999 a San Francisco, è un CRM basato sul Cloud. CRM è l'acronimo di "Customer Relationship Management" (Gestione delle relazioni con i clienti), permette di gestire le informazioni più importanti sui clienti e migliorare l'efficienza delle vendite.
Salesforce è nato nel 1999 a San Francisco, è un CRM basato sul Cloud. CRM è l'acronimo di "Customer Relationship Management" (Gestione delle relazioni con i clienti), permette di gestire le informazioni più importanti sui clienti e migliorare l'efficienza delle vendite.
Con un'unica piattaforma è possibile vendere, fornire assistenza, fare marketing, collaborare, analizzare il comportamento dei clienti e molto altro ancora.
Le principali funzionalità offerte da Salesforce sono:
- Gestione contatti dei clienti;
- Report e dashboard per una panoramica aziendale in tempo reale;
- Gestione trattative;
- Gestione dei lead (potenziali clienti);
- Integrazione con le principali applicazioni email;
- Gestione dei partner;
- Condivisione di file;
- Offrire dati analitici più approfonditi;
- Identificare modelli di comportamento e tendenze su cui agire;
- Analizzare le interazioni dei clienti con canali, messaggi e contenuti.
CHE COS'E' IL CLOUD COMPUTING
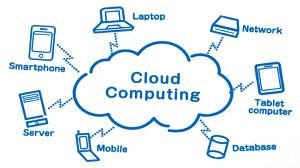 I servizi di questa potente piattaforma sono disponibili attraverso Internet, in cloud, quindi chiunque può dimensionare il CRM alle proprie esigenze aziendali, perché sono disponibili diverse soluzioni per piccole, medie e grandi aziende.
I servizi di questa potente piattaforma sono disponibili attraverso Internet, in cloud, quindi chiunque può dimensionare il CRM alle proprie esigenze aziendali, perché sono disponibili diverse soluzioni per piccole, medie e grandi aziende.
Il cloud computing permette di distribuire servizi di calcolo, come server, risorse di archiviazione, database, rete, software, analisi e intelligence, attraverso Internet, offrendo la possibilità di pagare solo per i servizi cloud usati, permettendoti di risparmiare sui costi operativi. L'infrastruttura cloud è scalabile e in modo più efficiente permette di dimensionare le risorse in base all'evoluzione delle esigenze aziendali.
CHE COS'E' APEX
Apex è Il linguaggio di programmazione usato per personalizzare Salesforce, è un linguaggio fortemente tipizzato ed orientato agli oggetti, che consente di eseguire istruzioni di controllo del flusso e delle transazioni su un server con piattaforma Lightning in combinazione con le chiamate all'API Lightning Platform. Mediante una sintassi dall'aspetto simile a Java e dal funzionamento simile alle procedure memorizzate in un database, Apex consente agli sviluppatori di aggiungere una logica applicativa alla maggior parte degli eventi di sistema, compresi i clic sui pulsanti, gli aggiornamenti dei record correlati e le pagine Visualforce.
Apex Code può essere avviato da richieste di servizi Web e da trigger per gli oggetti.
COME PARTECIPARE ALLA SKILL FACTORY "APEX DEVELOPER"
Per partecipare alla Skill Factory "Apex Developer", dovete aver completato gli studi (diploma o laurea), essere disoccupati, avere un'età compresa tra i 19 e 28 anni se diplomati, fino a 32 anni solo se laureati in discipline tecniche o scientifiche oppure se già programmi in Java e vuoi migliorare la tua posizione di lavoro.
Se completi con successo questa Skill Factory, è richiesta la disponibilità immediata a lavorare presso uno dei nostri partners IT di Napoli con le seguenti modalità di collaborazione:
Tirocinio e successivamente Apprendistato oppure contratto a tempo indeterminato se non è applicabile l'apprendistato.
Per partecipare ai test di selezione invia il tuo curriculum all'indirizzo mail: recruitng@skillfactory.it, entro l' 11 novembre 2020.
Sei già connesso a www.skillbook.it, clicca qui per inviare il tuo cv elettronico.
MODALITA' DIDATICHE DELLA SKILL FACTORY "APEX DEVELOPER"
La Skill Factory "Apex Developer" è gratuita ed ha una durata di 240 ore, dal 16 novembre 2020 all' 8 gennaio 2021.
Le attività didattiche verranno svolte in modalità FAD attraverso le piattaforme www.skillbook.it e Microsoft Teams.
Contenuti
Progettazione e sviluppo Database con SQL
Fondamenti di logica di programmazione con JAVA
Java Object Oriented
Panoramica su Salesforce
Apex
ISCRIVITI AL NOSTRO CANALE YOUTUBE
Per apprendente velocemente le competenze che ti servono per partecipare alla Skill Factory "Apex Developer", segui i corsi pubblicati sul nostro canale YouTube "Skill Factory channel".
Per iscriverti al canale devi essere in possesso di un account Google, se non hai ancora un account clicca qui.
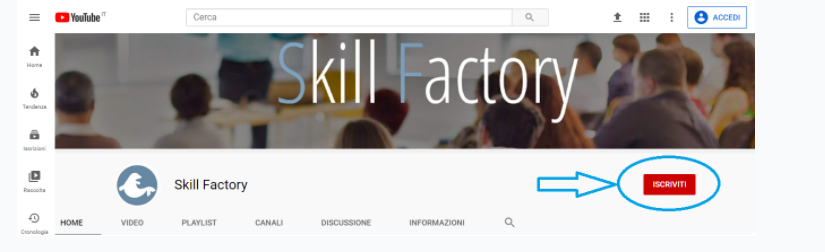
Se sei già in possesso di un account Google, prosegui nel modo seguente:
1) Collegati al tuo account Gmail
2) Vai sul sito ufficiale di YouTube
3) Cliccare su Accedi
4) Inserisci user e password del tuo account Google
5) Clicca sul pulsante seguente:

6) Per iscriverti clicca sul pulsante indicato
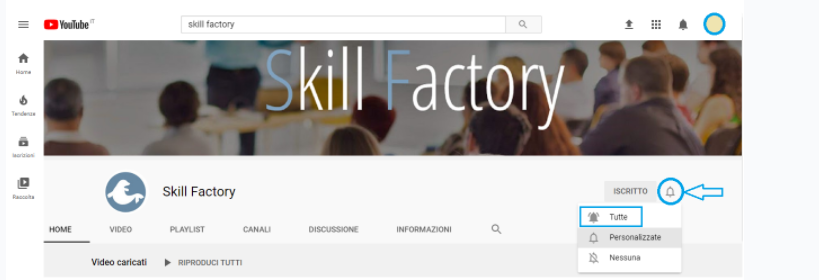
7) Non dimenticare di attivare le notifiche
Buona formazione!

Ad ottobre, in partnership con KEYTECH, parte la Skill Factory SAP Essential, in modalità Smart Learning. L'attività di formazione è fondamentale per chi vuole lavorare in una media o grande azienda.
![]() Gino Visciano |
Skill Factory - 05/10/2020 23:06:01 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 05/10/2020 23:06:01 | in Formazione e lavoro
CHE COS'E' SAP
 SAP è il più noto ERP, diffusissimo tra le medie e grandi aziende. Se hai studiato economia e gestione aziendale, la conoscenza di un Enterprise Resource Planning come SAP è un prerequisito importante per poter lavorare in un'azienda che gestisce processi di business come le vendite, gli acquisti, la gestione del magazzino, la finanza, la contabilità, ecc.
SAP è il più noto ERP, diffusissimo tra le medie e grandi aziende. Se hai studiato economia e gestione aziendale, la conoscenza di un Enterprise Resource Planning come SAP è un prerequisito importante per poter lavorare in un'azienda che gestisce processi di business come le vendite, gli acquisti, la gestione del magazzino, la finanza, la contabilità, ecc.
SAP offre opportunità di lavoro anche ai laureati con qualunque tipo di specializzazione informatica, perché possono imparare a programmare con ABAP il linguaggio di programmazione che permette di personalizzare i sistemi SAP oppure possono imparare ad usare SAP Fiori la suite di web app rivolta a tutte quelle aziende che manifestano l’esigenza di un monitoraggio e una gestione completa anche da remoto, attraverso l'uso di Smartphone e Tablet.
Per coloro che vogliono diventare professionisti nel settore della Business Intelligence, SAP offre strumenti di analisi che permettono di supportare le aziende a prendere decisioni rapide e sicure.
SKILL FACTORY SAP ESSENTIAL
La Skill Factory SAP Essential, in partenza ad ottobre, in modalità smart learning, si pone l'obiettivo di introdurre laureati, laureandi o diplomati al mondo degli ERP e conoscere le caratteristiche fondamentali del sistema SAP, indispensabili per qualunque tipo di specializzazione futura.
Prevede i moduli seguenti:

SAP Overview
Definizione di un ERP; Il sistema SAP e la sua evoluzione; Moduli Sap; Landascape Sap; Customizing; Linguaggi di programmazioni Utilizzati; Definizione ed Utilizzo di una CR; Figure Professionali Sap; Metodologia ASAP; Fasi di Un Progetto Sap.
SAP Basis
Sap GUI; Puntamenti Sap; Navigazione Landascape, Creazione Utenza, Creazione di una CR, Trasporto di una CR.
SAP FI
Introduzione Modulo FI; Anagrafica Fornitori, Anagrafica Clienti, Anagrafica Conti coge, Registrazione Fattura Passiva; Registrazione Fattura Attiva, Registrazione Incassi, Registrazione Pagamenti; Visualizzazione delle scritture contabili sul Giornale Bollato; Cenni sul Customizing.
Le attività sincrone, erogate in presenza (Virtual Class), si terranno il LUNEDI', il MERCOLEDI' ed il VENERDI' dalle ore 10,00 alle ore 12,00.
Le attività di laboratorio verranno svolte in modalità asincrona, con supporto tecnico attraverso la piattaforma skillbook.it.
SCHEDA SKILL FACTORY SAP ESSENTIAL
Livello: BASE
Modalità didattica: SMART LEARNING
Virtual class: 40 ore (Sincrona)
Laboratorio: 40 ore (Asincrono)
Supporto didattico: Videolezioni
Destinatari: Laureati, Laureandi oppure Diplomati che vogliono diventare programmatori ABAP
Quorum: 6 iscritti
Competence Partner: KEYTECH
Docente: Dario Cirillo
Per la valutazione del livello di apprendimento sono previste le seguenti attività:
1) Esame di certificazione sulla piattaforma skillbook.it.
2) Prova di laboratorio individuale
3) Colloquio con Competence Partner KEYTECH
Il risultati di tutte le attività di verifica svolte, verranno indicati nell' ATTESTATO DI PARTECIPAZIONE .
A fine percorso, per tutti i partecipanti, è prevista un'attività di ORIENTAMENTO di un'ora, gestita dagli esperti della Skill Factory, con l'obiettivo di evidenziare i possibili sviluppi futuri e le opportunità offerte dal mondo della formazione e del lavoro.
Prezzo: 390 iva inclusa
Per informazioni e prenotazioni chiamare al numero 3270870141 dalle ore 9,00 alle ore 12,00 oppure invia una mail a segreteria@skillfactory.it.
COMPETENCE PARTNER

Keytech è una società di Consulenza e Formazione che supporta i clienti nei progetti di trasformazione tecnologica. L'azienda nel corso degli anni ha acquisito una grossa esperienza nell’implementazione di Sistemi Informativi e nell’Analisi dei processi di business, utilizzando le più evolute tecnologie SAP.
Attualmente è impegnata in progetti ad alto contenuto tecnologico, nei seguenti settori: Manufacturing, Food & Beverage, Pharma, Consumer Business e Aerospace & Defense, Public Sector.
Per maggiori informazioni clicca qui.
CURRICULUM DOCENTE
DARIO CIRILLO, consulente e formatore Sap.
Da diversi anni si occupa di progetti Sap per clienti come Enel ed Acea.
Ha maturato una grande esperienza nel settore amministrativo, contabile e fiscale e dal 2019 è responsabile della SAP Academy del società KEYTECH.
Progetta ed eroga i seguenti corsi: SAP FI, SAP CO, SAP MM, SAP SD, SAP ABAP, SAP Fiori, SAP IS-U.
Agic Technology, Gold Partner Microsoft, assume a Napoli laureati e diplomati per svolgere il ruolo di Microsoft Dynamics CRM Junior Developer
![]() Gino Visciano |
Skill Factory - 12/04/2019 10:12:46 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 12/04/2019 10:12:46 | in Formazione e lavoro
 Agic Technology per consolidare il gruppo di lavoro per la sede di Napoli, assume giovani laureati e diplomati per svolgere il ruolo di Microsoft Dynamics CRM Junior Developer.
Agic Technology per consolidare il gruppo di lavoro per la sede di Napoli, assume giovani laureati e diplomati per svolgere il ruolo di Microsoft Dynamics CRM Junior Developer.
Si tratta sicuramente di un'offerta di formazione e lavoro molto interessante perché, le risorse selezionate, oltre ad apprendere le conoscenze tecniche per lo sviluppo e la manutenzione di applicazioni Microsoft Dynamics CRM, acquisiranno anche le competenze di programmazione per lavorare con ASP.NET Core, il nuovo framework MIcrosoft, completamente Open Source, che permette di creare applicazioni C# trasportabili su qualunque sistema operativo.
Per le 12 risorse selezionate la formazione sarà gratuita, avrà una durata di 40 giorni e si svolgerà nelle aule della nostra sede di Napoli, presso il Centro Polifunzionale INAIL di via Nuova Poggioreale.
Se siete interessati a questa attività di formazione e lavoro clccate sul link seguente: come partecipare alle selezioni per svolgere il ruolo di Microsoft Dynamics CRM Junior Developer (Napoli).
 Per ulteriori informazioni di seguito pubblichiamo l'intervista fatta alla Dott.ssa Laura Petrini, responsabile Risorse Umane (HR) della società Agic Technology.
Per ulteriori informazioni di seguito pubblichiamo l'intervista fatta alla Dott.ssa Laura Petrini, responsabile Risorse Umane (HR) della società Agic Technology.
SF - Può descriverci brevemente la sua azienda?
LP - Agic Technology è uno dei principali partner di Microsoft in Italia, conosciuto per innovazione, competenze e servizi a valore aggiunto. Agic Technology implementa soluzioni e progetti al servizio delle Organizzazioni e degli Utenti Aziendali basati sulle tecnologie Microsoft. Business Applications (ERP e CRM), Data Analytics, Artificial Intelligence, Cloud Platform, IOT, Mobile, Machine Learning, Web, App, Portal & Collaboration sono soltanto alcune delle piattaforme sulle quali basiamo le nostre soluzioni. Professionisti esperti di Governance, Risk e Compliance intervengono a fianco degli specialisti di tecnologie per accompagnare il rilascio delle soluzioni nel rispetto della sicurezza e del nuovo GDPR.
Cinque sedi in Italia e un HUB di sviluppo a Tirana consentono una capacità di consulenza, supporto e sviluppo di progetti locali e internazionali, rilasciando soluzioni specializzate per i principali settori industriali e di servizi, quali: Finance, PA, Associazioni ed Enti, Professional Services, Manufacturing, Engineering & Construction, Telco, Media & Gaming, Pharma.
Con un parco clienti di oltre 400 aziende e un team di più di 200 professionisti, Agic Technology si propone come partner tecnologico specializzato sulle piattaforme Microsoft per le medie e grandi imprese.
SF - A breve quali sono i vostri obiettivi di crescita?
LP - Il nostro obiettivo è di crescere ulteriormente e di guardare sempre all’innovazione grazie alla nostra Partnership con Microsoft!
SF - Quante risorse intendete assumere a Napoli?
LP - Stiamo puntando sulla sede di Napoli, saranno almeno 20 gli ingressi programmati per il 2019.
SF - Che ruolo dovranno svolgere le risorse che state cercando?
LP - Conoscere tecnicamente e/o funzionalmente la tecnologia Microsoft Dynamics 365.
SF - Quali sono le caratteristiche peculiari dei vostri dipendenti?
LP - Aperti al cambiamento, devono codividere la propria esperienza con gli altri colleghi del team, essere concreti e sempre focalizzati sugli obiettivi da raggiungere.
SF - Qual è il candidato ideale per la vostra offerta di lavoro?
LP - Motivato ed appassionato, con voglia di intraprendere un percorso di crescita sfidante, predisposto all’innovazione!
SF - Per formare i candidati che non sono in possesso di tutte le competenze richieste, avete previsto un percorso di formazione?
LP - Certo! Il nostro intento è di formare le risorse con un academy di 8 settimane (5 devolute alla spiegazione del framework .net e 3 per la spiegazione del Dynamics 365).
SF - Dopo aver terminato il percorso di formazione, quali sono le modalità d'inserimento in azienda?
LP - Il nostro intento è di formare le risorse e arricchire il percorso con la formazione on the job.
SF - Coloro che sono interessati alla vostra offerta di lavoro, dove devono inviare il proprio cv?
LP - Possono inviarlo anche sul nostro sito: lavora con noi.
SF - Qual è il termine ultimo per inviare la propria candidatura e partecipare ai test di ammissione?
LP - Entro il 15 maggio.
SF - Grazie per il tempo concesso alla nostra intervista e per l'opportunità di formazione e lavoro offerta.
Big Data - Cosa sono e cosa cambia (terza parte)
![]() Gino Visciano |
Skill Factory - 05/04/2019 00:02:53 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 05/04/2019 00:02:53 | in Formazione e lavoro
La piattaforma che offre il maggior numero di strumenti per la gestione dei Big Data è Hadoop, un ecosistema open source sviluppato da Apache Software Foundation.
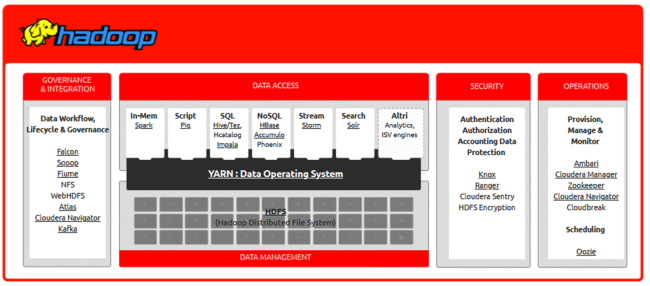
I motivi principali della diffusione di Hadoop sono i seguenti:
- per la sua flessibilità ad immagazzinare i dati indipendentemente dal fatto che siano strutturati o destrutturati;
- permette di processare i dati di natura complessa e di elevate dimensioni;
- è economico e scalabile rispetto ai sistemi di immagazzinamento dei dati tradizionali;
- è tollerante ai guasti (fault tolerant).
Hadoop offre strumenti per la gestione dei Big Data strutturati e destruturati permettendo la loro elaborazione sia in modalità batch, sia in modelità streaming (aggiornamento dei dati in tempo reale on line).
La caratteristica principale di questo framework è quella di essere scalabile orizzontalmente (MPP - Massively Parallel Processing), in pratica Hadoop sfrutta le potenzialità offerte da un cluster di computer, detti nodi, su cui vengono distribuiti dati e gestiti i processi di lavoro sincronizzati.
Ciascuno dei Computer che appartengono al Cluster è chiamato nodo, esistono due tipologie di nodi nell’architettura Hadoop: il nodo master ed il nodo slave.
Il nodo master (Namenode) controlla tutti i nodi slave (Datanode), è qui che le informazioni vengono immagazzinate in blocchi.
I blocchi sono gestiti direttamente dal nodo master ed hanno una dimensione minima di 128MB.
Hadoop per essere tollerante ai guasti, replica i blocchi su più nodi, in modo da poter essere recuperati in caso di errori.
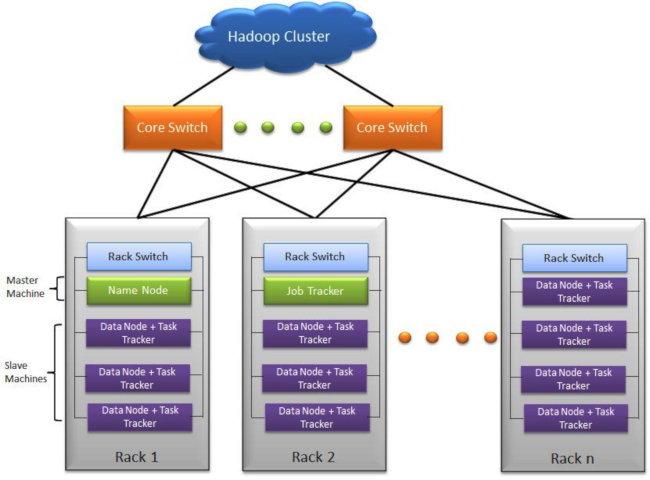
ARCHITETTURA DI HADOOP
L'architettura di Hadoop può essere divisa in quattro parti fondamentali:
1) HDFS
2) MAPREDUCE
3) YARN
4) STRUMENTI PER GESTIRE ED ANALIZZARE BIG DATA
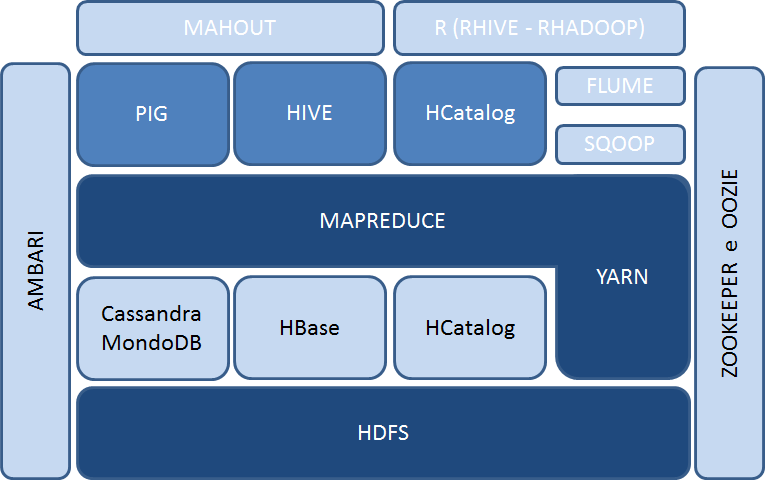
HDFS
L'HDFS è il File System distribuito di Hadoop, permette di distribuire file di grandi dimensioni in blocchi registrati sui DataNode associati ai nodi di tipo slave del Cluster, in pratica è un grande virtual storage, tollerante ai guasti, è lui che gestisce le repliche dei blocchi tra nodi per evitare la perdita di dati.
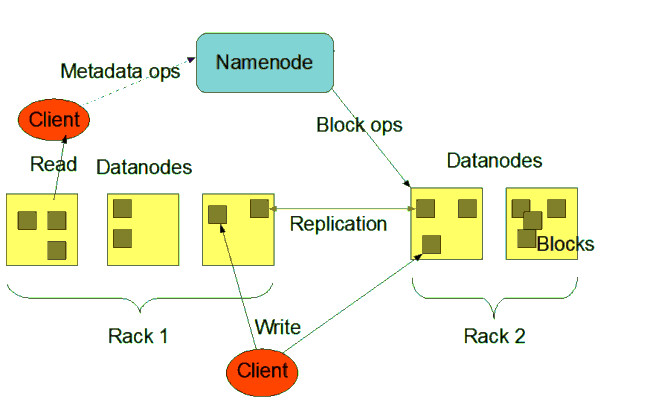
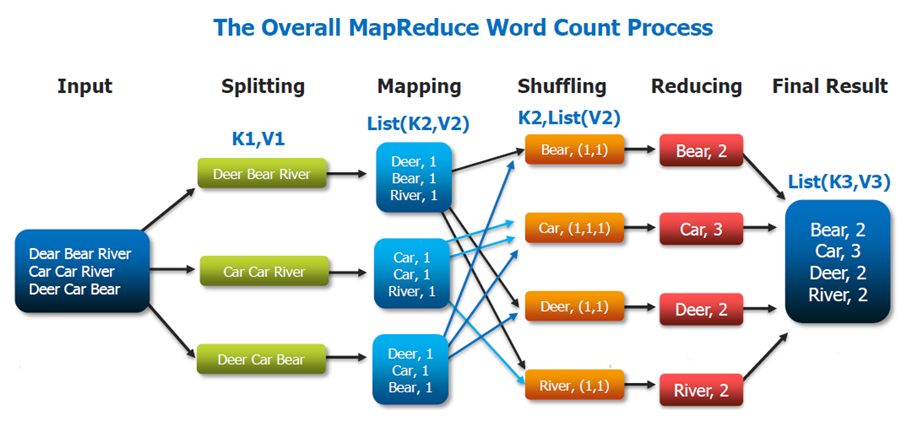
MAPREDUCE
MapReduce è popolare grazie a Google che lo utilizza per elaborare ogni giorno molti petabyte di dati. Il modello di MapReduce è costituito da due programmi scritti dall’utente, chiamati map e reduce e da un framework che abilita l’esecuzione di un grande numero di istanze di ciascun programma sui diversi nodi del cluster.
Il programma map legge un insieme di record da un file di input, svolge le operazioni di ETL, quindi produce una serie di record di output nella forma (chiave, dati).
Mentre il programma map produce questi record, una funzione separata li organizza in contenitori multipli e indipendenti, applicando una funzione alla chiave di ciascun record, questa funzione è tipicamente hash, sebbene sia sufficiente qualsiasi tipo di funzione deterministica. Una volta che il contenitore è pieno, il suo contenuto viene salvato sul disco.
Il programma map termina producendo una serie di file di output, uno per ciascun contenitore.
Dopo essere stati raccolti dal framework map-reduce i record di input vengono raggruppati per chiavi (attraverso operazioni di sorting o hashing) e sottoposti al programma reduce.
Il programma reduce esegue una elaborazione dei dati attraverso un linguaggio general purpose, come ad esempio Java, Scala oppure Python. Cascuna istanza reduce può scrivere record in un file di output e quest’ultimo rappresenta una parte della risposta elaborata da MapReduce.
La coppia chiave/valore prodotta dal programma map può contenere qualsiasi tipo di dati nel campo assegnato al valore del campo. Google, per esempio, utilizza questo approccio per indicizzare grandi volumi di dati non strutturati.
Le coppie chiave/valore utilizzate nell’elaborazione MapReduce possono essere archiviate in un file o in un database che sfruttano la logica di coppie chiave/valore.
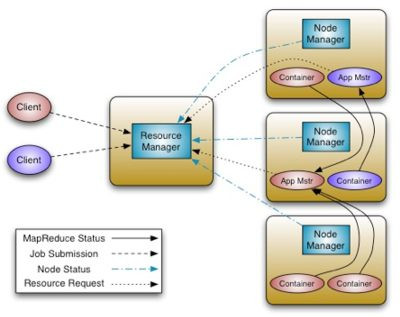
YARN
YARN (Yet Another Resource Negotiator) gestisce le risorse del Cluster, come ad esempio la memoria e la CPU, la larghezza di banda della rete e lo spazio di archiviazione disponibile e monitora l’esecuzione delle applicazioni. Rispetto alla prima versione di MapReduce è ora un sistema molto più generico, infatti la seconda versione di MapReduce è stata riscritta come applicazione YARN, con alcune sostanziali differenze.
YARN offre chiari vantaggi in termini di scalabilità, efficienza e flessibilità rispetto al classico motore MapReduce nella sua prima versione.
Le applicazioni da eseguire si chiamano Application Master, il Resource manager richiede la possibilità di installare l’application master sul cluster.
Il Resource manager richiede a un nodo del cluster la creazione di un container per eseguire l'applicazione. Al container è associato un determinato ammontare di risorse RAM e CPU, per evitare di bloccare il nodo.
Una volta in esecuzione, il master si moltiplica, richiedendo a sua volta al resource manager (tramite le apposite API di YARN) altri container su altri nodi su cui lanciare le varie copie dell’applicazione distribuita.
L’application master a sua volta manda segnali di heartbeat al resource manager per indicare di essere ancora vivo e funzionante.
Un esempio di una applicazione YARN è proprio MapReduce. In questo caso l’Application Master è il JobTracker mentre le varie repliche lanciate sui vari container sono i vari TaskTracker (mapper o reducer).
MapReduce è un Application Master già disponibile in YARN, in modo da mantenere un minimo di retro-compatibilità con Hadoop 1.0 (la retro compatibilità non è però garantita).
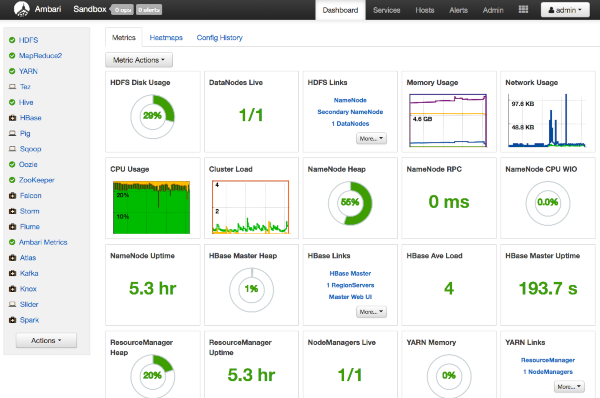
AMBARI
Ambari semplifica la gestione ed il monitoraggio di un cluster Apache Hadoop grazie ad un'interfaccia utente Web facile da usare. Ambari è usato per monitorare il cluster e modificare la configurazione di Hadoop.
HCATALOG
HCatalog presenta agli utenti una vista tabellare dei dati presenti in HDFS, indipendentemente dal formato di origine, rendendo più semplice la creazione e la modifica dei metadati.
PIG
È un linguaggio di scripting evoluto che consente di bypassare le difficoltà di approccio al framework MapReduce grazie a una sintassi semplice, ma al tempo stesso potente e efficace. Al momento dell’esecuzione lo script Pig viene automaticamente tradotto in uno o più job Tez o MapReduce2.
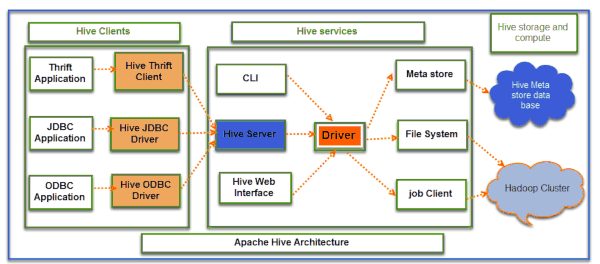
HIVE
Hive consente di creare l’infrastruttura necessaria a gestire un completo data warehouse on top of Hadoop. Hive si posiziona all’interno del batch layer di Hadoop e consente di gestire sia dati strutturati che destrutturati immagazzinati all’interno del Blob Storage. Utilizza un linguaggio SQL-like chiamato HiveQL. È ideale per qualsiasi tipo di analytics di tipo non transazionale.
HBASE
HBase è il database NoSQL di Hadoop: utilizza HDFS per immagazzinare i dati ed è totalmente scalabile su tutti i nodi del cluster stesso di Hadoop. Utilizza un modello key-value dove i dati sono distribuiti secondo una mappa key-value ordinati per key. Può contenere miliardi di righe e milioni di colonne.
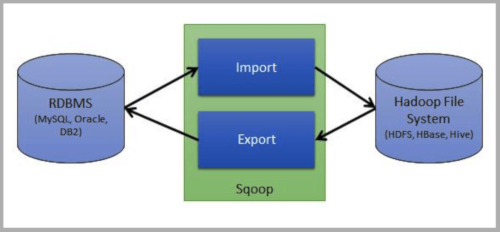
SQOOP
Sqoop è l’ETL nativo di Hadoop. Consente l’accesso a sistemi RDBMS esterni, la lettura automatica dello schema e l’ingestion dei dati all’interno di HDFS. Grazie all’utilizzo del framework MapReduce2 qualsiasi data ingestion basata su Sqoop è scalabile e altamente performante.
FLUME
Flume è uno dei principali tool di data ingestion dell’ecosistema Hadoop per la raccolta, l’aggregazione, il controllo e l’immagazzinamento di stream di dati (tipicamente machine data) all’interno di HDFS.
OOZIE
Oozie è uno schedulatore di workflow che risiede e opera all’interno di Hadoop: è in grado di gestire, controllare e concatenare job MapReduce2, Sqoop, Hive e Pig e può essere utilizzato sia all’interno di un batch layer che di uno speed layer.
ZOOKEEPER
È un servizio centralizzato per la gestione delle configurazioni, la creazione di ensemble per i servizi di naming e group e la sincronizzazione delle distribuzioni di informazioni (es: transazioni distribuite). Molti servizi dell’ecosistema di Hadoop dipendono da ZooKeeper (es: HBase e NameNode HA).
Big Data - Cosa sono e cosa cambia (seconda parte)
![]() Gino Visciano |
Skill Factory - 16/03/2019 00:16:42 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 16/03/2019 00:16:42 | in Formazione e lavoro
 Tutte le volte che interagiamo con un dispositivo connesso ad Internet, consapevolmente ed a volte anche inconsapevolmente, produciamo dati.
Tutte le volte che interagiamo con un dispositivo connesso ad Internet, consapevolmente ed a volte anche inconsapevolmente, produciamo dati.
Le aziende lavorano ed analizzano i nostri dati principalmente per ottenere un vantaggio competitivo.
Il mercato dei Big Data è in forte crescita perché le aziende, sempre di più, richiedono l'uso di questo strumento per i seguenti motivi:
- Aumentare il fatturato attraverso la crescita delle vendite;
- Rendere prevedibile lo sviluppo della domanda, basandosi sui comportamenti dei clienti;
- Dare più valore all’account management analizzando le operazioni tra venditori e clienti e prevedere ciò che è meglio fare per un qualsiasi cliente;
- Aprire nuove opportunità di business, per chi voglia allargare il mercato puntando su clienti relativamente nuovi.
Quando ai Big data si uniscono gli analytics è possibile:
- Determinare, quasi in tempo reale, le cause di guasti, avarie o difetti;
- Creare offerte nei punti vendita basate sulle abitudini dei clienti;
- Ricalcolare interi portafogli di rischio in pochi minuti;
- Individuare comportamenti fraudolenti prima che colpiscano la propria organizzazione.
Si usano quattro modelli di analytics:
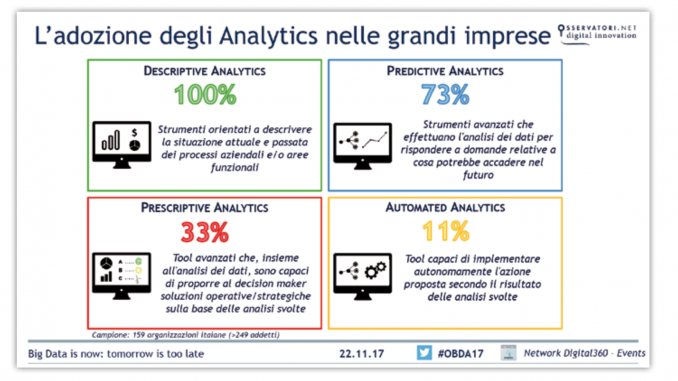
Descriptive Analytics: strumenti orientati a descrivere la situazione attuale e passata dei processi aziendali e/o aree funzionali. Tali strumenti permettono di accedere ai dati secondo viste logiche flessibili e di visualizzare in modo sintetico e grafico i principali indicatori di prestazione;
Predictive Analytics: strumenti avanzati che effettuano l’analisi dei dati per rispondere a domande relative a cosa potrebbe accadere nel futuro; sono caratterizzati da tecniche matematiche quali regressione, forecasting, modelli predittivi, ecc;
Prescriptive Analytics: applicazioni big data avanzate che, insieme all’analisi dei dati, sono capaci di ottenere soluzioni operative/strategiche sulla base delle analisi svolte;
Automated Analytics: capaci di implementare autonomamente l’azione proposta secondo il risultato delle analisi svolte (Machine Learning).
I Big Data possono essere analizzati in due modalità diverse:
1 - Batch: in questa modalità i dati da analizzare vengono aggiornati ad intervalli periodici, è una modalità tipica del Data warehouse
2 - Streaming: in questa modalità i dati da analizzare vengono aggiornati in tempo reale, modalità tipica dell'IoT.
Per individuare i modelli di utilizzo degli Analytics è necessaria anche definire le tipologie di dati da analizzare che possono essere principalmente di due tipi:
1 - dati strutturati: organizzati in tabelle o modellati in formati tipo XML, JSON, BSON e CSV.
2 - dati destrutturati.
I dati destrutturati sono tipicamente:
- testo;
- immagini;
- video;
- audio;
- elementi di calcolo.
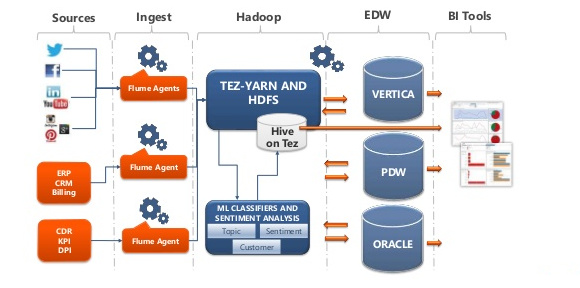
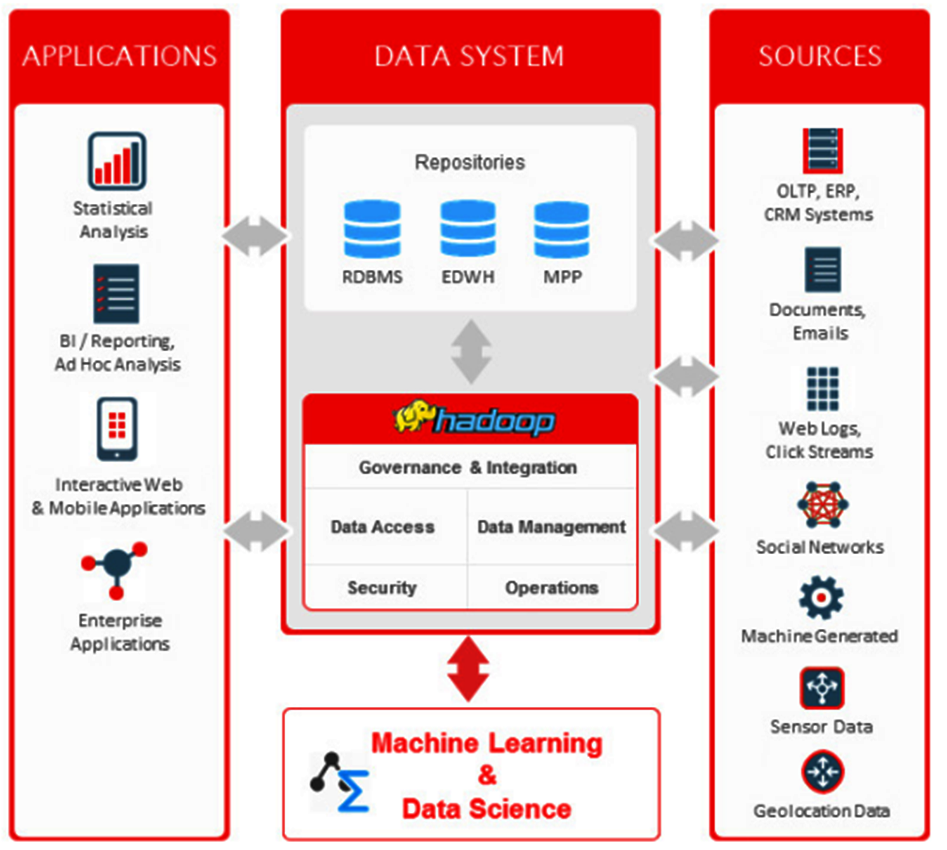
L'immagine seguente descrive l'ecosistema Hadoop, la piattaforma che offre tutti gli strumenti necessari per gestire grandi quantità di dati.
Lo schema mette in relazione tra loro tutti i livelli fondamentali per la lavorazione e l'analisi di Big Data.
I diversi tipi di repositories disponibili, possono essere alimentati da sorgenti di dati differenti attraverso processi di caricamento (ETL/ELT) di tipo batch o streaming.
La grande quantità di dati caricati, attraverso il filesystem distribuito HDFS, può essere immagazzinata sui nodi del cluster Hadoop, rappresentato da un insieme di computer, detti nodi, che condividono i propri dischi, creando un'unica grande memoria di massa.
Utilizzando strumenti come MapReduce, i Big Data possono essere mappati e ridotti, il risultato di questo lavoro potrà essere analizzato dalle diverse applicazioni diponibili oppure potrà essere interessato ad operazioni di Machine Learning.
La potenza di calcolo richiesta per l'esecuzione dei JOB di map reduce e di analasi viene fornita dalle CPU dei computer del cluster Hadoop, attraverso multiprocessi paralleli (MPP) gestiti da YARN di Hadoop.
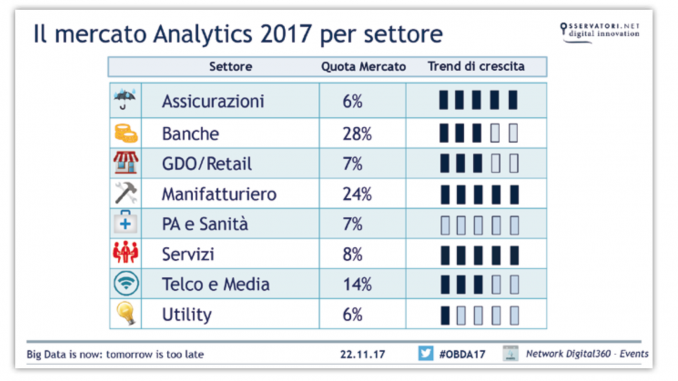
Attualmente esistono esperienze d'implementazione di progetti di Big Data Analytics in medie e grandi aziende dei seguenti settori:
La figura professionale che in azienda si occupa delle strategie per gestire grandi quantità di dati e della loro interpretazione è il Data Scientist.
Per svolgere questo ruolo bisogna avere competenze in ingegneria, informatica, statistica, economia e matematica, in particolare è richiesta la conoscenza dei seguenti linguaggi di programmazione:
- Java
- Scala
- R
- Python
e la capacità di sviluppare ed implementare algoritmi di Machine Learning.
In Italia un Data Scientist può guadagnare oltre €30.000,00 all'anno, in funzione del livello di seniority raggiunto.
DIFFERENZA TRA DATA ANALYST E DATA SCIENTIST
 Il Data Analyst è colui che esplora, analizza e interpreta i dati, con l’obiettivo di estrapolare informazioni utili al processo decisionale, da comunicare attraverso report e visualizzazioni ad hoc.
Il Data Analyst è colui che esplora, analizza e interpreta i dati, con l’obiettivo di estrapolare informazioni utili al processo decisionale, da comunicare attraverso report e visualizzazioni ad hoc.
Il Data Analyst parte dal lavoro svolto dal Data Scientist per trasmettere e interpretare le informazioni al fine di supportare gli utenti con cui collabora.
Questa figura professionale non proviene da un percorso estremamente tecnico, è preferibile anzi che abbia compiuto studi economico-manageriali, in modo da poter parlare lo stesso linguaggio delle figure di business con cui andrà ad interfacciarsi.
Lo stipendio medio di un Data Analyst in Italia è di circa €27.000 all'anno.
PRINCIPALI STRUMENTI PER L'ANALISI DEI DATI
Gli strumenti di analisi dei dati, anche detti di front-end, più richiesti dalle aziende sono: Tableau, Qlik e Power BI, cliccate sui loghi per accedere ai siti ufficiali.



 FILTRI
FILTRI


 Offerte di Lavoro
Offerte di Lavoro
 Post più recenti
Post più recenti
-

Full Stack Developer
07/05/2026
-
1° MAGGIO: FESTA DEL LAVORO E DELLA FORMAZIONE
01/05/2026
-
Operatore Amministrativo Contabile
09/04/2026
-
Tecnico Programmatore: Il Profilo più richiesto dai giovani che frequentano la nostra Academy
17/03/2026
-
6.L'Assicurazione della Qualità nell'IFP
24/01/2026
-
Skill Factory 2025: Un anno di formazione tra "Innovazione (AI), Qualità (EQAVET) e Politiche Attive del Lavoro (PAR GOL)"
30/12/2025
-
10.Intelligenza Artificiale: cosa cambia nel mondo del lavoro
21/12/2025
-
5.L’etica della formazione come responsabilità professionale
13/12/2025
-
4.Buona Formazione: "Come assicurare la Qualità della Formazione"
06/12/2025
-
Corso gratuito di 60 ore per creare le competenze digitali fondamentali (DIGCOMP2.2)
25/09/2025