





-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-





 Scheda Azienda
Scheda Azienda Eventi formazione
Eventi formazione Offerta formativa
Offerta formativa Lavora con noi
Lavora con noi
 Richiedi informazioni
Richiedi informazioni
Skill Factory
Categoria: Formazione e lavoro
Diventa DevOps, la figura IT che integra e distribuisce i componenti software ed inizia al lavorare nel mondo dell'Information Technology
![]() Gino Visciano |
Skill Factory - 22/06/2022 08:48:10 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 22/06/2022 08:48:10 | in Formazione e lavoro
 Il passaggio dal paradigma procedurale a quello ad oggetti ha rivoluzionato completamente il modo di progettare, sviluppare e distribuire le applicazioni software.
Il passaggio dal paradigma procedurale a quello ad oggetti ha rivoluzionato completamente il modo di progettare, sviluppare e distribuire le applicazioni software.
Le aziende IT che producono software sono diventate delle industrie che creano a cicli continui i componenti che servono per costruire le applicazioni software che hanno trasformato sia il nostro modo di lavorare, sia il modo in cui gestiamo le nostre attività quotidiane.
Questa rivoluzione tecnologica ha avuto un impatto positivo sull mondo del lavoro, facendo crescere la richiesta di:
- programmatori
- tester
- devops
Oggi le aziende che producono software utlizzano una metodologia agile che consente di far crescere la applicazioni software in modo iterativo ad incrementi successivi.
In questo scenario diventa fondamentale il ruolo dei DevOps (dalla contrazione inglese di development, "sviluppo" e operations, "messa in produzione" o "deployment"), la figura emergente che si occupa di automatizzare il rilascio del software rispetto alla sua catena di produzione, garantendo un software di qualità superiore e sicuro in modo estremamente più rapido.
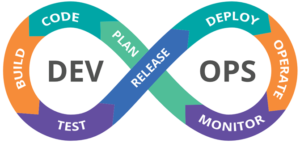
I DevOps devono avere la cultura della collaborazione e devono sapre utilizzare tutti gli strumenti che permettono di gestire i processi di continuous integration e continuous delivery,in particolare devono avere le seguenti competenze tecniche:
1) Amministrazione Linux;
2) Sviluppo script bash Linux;
3) Reti di computer;
4) Sicurezza Informatica;
5) Metodologie di sviluppo software;
6) Architetture software;
7) Cloud computing;
8) Docker;
9) kubernetes.
Per diventare DevOps e lavorare peresso una nostra azienda IT partner di Napoli, leader nel settore dello sviluppo software, potete parteciapre al percorso di specializzazione Skill Factory in partenza il 4 luglio 2022.
Il percorso è gratuito per tutti coloro che hanno completato gli studi, sono diplomati o laureati in discipline tecniche o stem e alla fine percorso sono disponibili a partecipare al stage aziendale retribuito che, in caso di successo, prevede l'assunzione con contratto a tempo indeterminato presso l'azienda IT partner.
Per partecipare al percorso di formazione per "DevOps", che prevede sia lo stage retribuito, sia l'opportunità di ottenere in caso di successo, un contratto a tempo indeterminato presso la nostra azienda IT partner, clicca qui e compila il modulo "Invia i tuoi dati", altrimenti invia una mail all'indirizzo recruiting@skillfactory.it, indicando nell'oggetto "sono interessato a partecipare al percorso di formazione per DevOps".

Laboratorio estivo di programmazione "Java"
![]() Gino Visciano |
Skill Factory - 29/05/2022 12:56:35 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 29/05/2022 12:56:35 | in Formazione e lavoro
 Com'è nostra consuetudine, anche quest'anno abbiamo organizzato il laboratorio estivo di programmazione "Java", finanziato dai nostri Job Partner IT per dare l'opportunità ai giovani che vorrebbero lavorare nel settore informatico, di frequentare la nostra scuola di alta formazione informatica gratuitamente.
Com'è nostra consuetudine, anche quest'anno abbiamo organizzato il laboratorio estivo di programmazione "Java", finanziato dai nostri Job Partner IT per dare l'opportunità ai giovani che vorrebbero lavorare nel settore informatico, di frequentare la nostra scuola di alta formazione informatica gratuitamente.
Le attività didattiche iniziano il 20 giugno 2022, è prevista una pausa durante il mese di agosto e termina il 16 settembre 2022.
Il laboratorio teorico/pratico, svolto in modalità blended (apprendimento misto: teoria a distanza e pratica in presenza), ti permetterà di acquisire le competenze che ti servono per svolgere il ruolo di "Java Full Stack Developer". Questa figura professionale oltre a dimostrare di avere competenze di programmazione lato back-end, deve dimostrare di avere competenze di sviluppo anche lato front-end.
Alla fine del laboratorio sarai capace di sviluppare applicazioni Business to Business (B2B), utilizzando i framework seguenti:
1) Java EE;
2) Spring;
3) Angular.
Durante il laboratorio, i nostri Job Partner IT, che lo hanno finanziato, interverranno per presentarti la loro azienda e le potenzialità di crescita che potrebbero offrirti.
 Per partecipare ai colloqui conoscitivi di ammissione al laboratorio estivo di programmazione "Java", invia il tuo cv, anche se sei semplicemente diplomato con un indirizzo tecnico/scientifico all'indirizzo recruiting@skillfactory.it indicando nell'oggetto: Candidatura per il colloquio conoscitivo per partecipare al laboratorio estivo di programmazione "Java".
Per partecipare ai colloqui conoscitivi di ammissione al laboratorio estivo di programmazione "Java", invia il tuo cv, anche se sei semplicemente diplomato con un indirizzo tecnico/scientifico all'indirizzo recruiting@skillfactory.it indicando nell'oggetto: Candidatura per il colloquio conoscitivo per partecipare al laboratorio estivo di programmazione "Java".
In alternativa, clicca qui e compila il modulo alla fine della pagina di presentazione del percorso di formazione "Java Full Stack Developer".
 Naturalmente il laboratorio verrà coordinato da me e dai mie collaboratori, che da oltre 10 anni hanno scelto di fare i formatori presso la nostra scuola di alta formazione "Skill Factory", permettendo ad oltre 2000 giovani di entrare nel mondo del lavoro IT.
Naturalmente il laboratorio verrà coordinato da me e dai mie collaboratori, che da oltre 10 anni hanno scelto di fare i formatori presso la nostra scuola di alta formazione "Skill Factory", permettendo ad oltre 2000 giovani di entrare nel mondo del lavoro IT.
Per saperne di più sul mio conto clicca qui, altrimenti per conoscere l'offerta formativa completa della nostra scuola di alta formazione informatica, visita il nostro sito www.skillfactory.it.
Se vuoi partecipare con successo al nostro laboratorio, ti suggerisco di seguire prima le nostre PlayList sul canale YouTube "Skill Factory Channel":
PlayList
1) Competenze per programmare con Python e Javascript
2) Progettazione e sviluppo database con MySQL
3) Java Object Oriented
4) HTML/CSS
Prima di inziare a seguire le videolezioni non dimenticare d'iscriverti al canale, in questo modo potremo certificare le ore che hai dedicato allo studio online.
Per vedere il video promozionale del laboratorio estivo di programmazione Java 2022 clicca qui.
Guida alla PlayList "Progettazione e sviluppo database con MySQL"
![]() Gino Visciano |
Skill Factory - 08/11/2021 17:35:03 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 08/11/2021 17:35:03 | in Formazione e lavoro
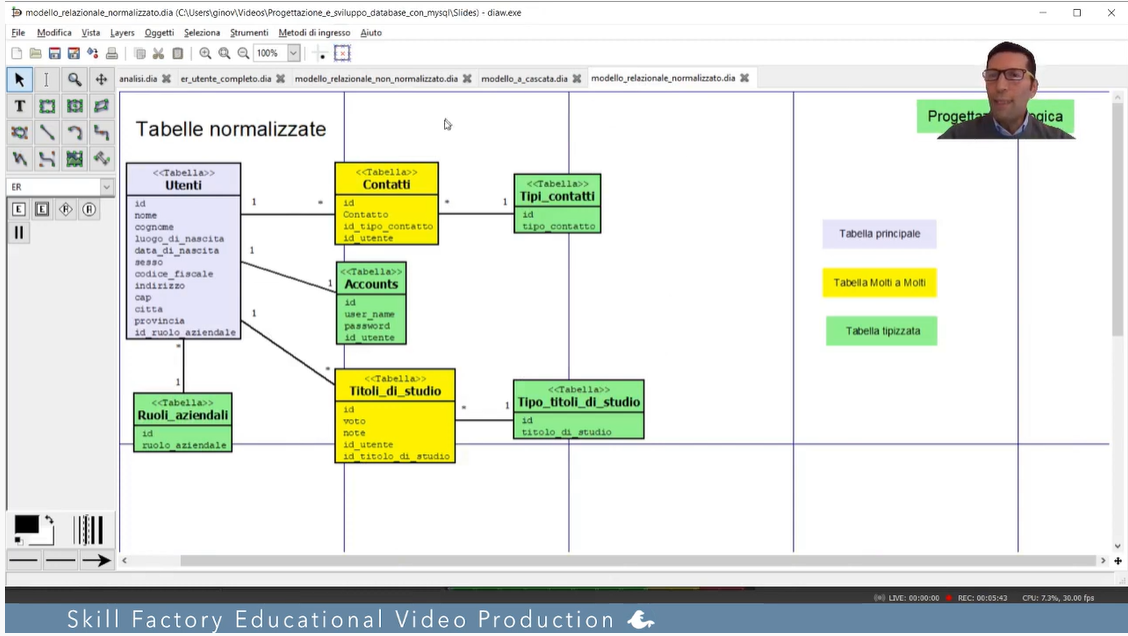 La PlayList "Progettazione e sviluppo database con MySQL", pubblicata su Skill Factory Channel, contiene le lezioni per imparare a progettare e sviluppare un database con il linguaggio SQL.
La PlayList "Progettazione e sviluppo database con MySQL", pubblicata su Skill Factory Channel, contiene le lezioni per imparare a progettare e sviluppare un database con il linguaggio SQL.
Come DBMS (Database Management System) abbiamo scelto MySQL, sia per la semplicità d'installazione e configurazione, sià per le caratteristiche che lo rendono molto simile a DBMS più professionali.
Gli obiettivi delle lezioni sono quelli di apprendere le competenze sia teoriche, sia pratiche per:
1 - progettare un database relazionale;
2 - disegnare i seguenti diagrammi: Entità Relazione, Modello Relazionale, Schema Fisico;
3 - applicare i comandi SQL: Data Definition Language, per creare e gestire la struttura di un database;
4 - applicare i comandi SQL: Data Manipulation Language, per gestire il contenuto delle tabelle;
5 - applicare i comandi SQL: Data Query Language, per interrogare le tabelle )(query) o creare report professionali (view);
6 - applicare i comandi SQL:Data Control Language, per gestire le autorizzazioni ed i permessi degli utenti.
Destinatari:
Studenti;
Giovani che vogliono lavorare in un'azienda IT;
Insegnanti d'istituti superiori ad indirizzo informatico;
Dipendenti di aziende IT che vogliono riqualificarsi.
Per accedere alla PlayList per seguire le lezioni clicca qui.
RISORSE
- -- ARTEFATTI- --
Modello Relazionale normalizzato (Utenti)
Schema Fisico (Utenti)
Creazione Database (Utenti)
Creazione indici (Utenti)
Creazione vincoli d'integrità referenziale
- -- SCRIPT- --
Per svolgere i laboratori proposti dal docente Gino Visciano, clicca qui per scaricare lo script da eseguire per creare il database db_rubrica.
 Se hai completato gli studi, sei inoccupato e vuoi lavorare in un'azienda IT, per partecipare ad un percorso di accompagnamento al lavoro con la Skill Factory, invia il tuo curriculum a recruiting@skillfactory.it, verrai contattato da un nostro recruiter che risponderà alle tue domande e valutarà l'idoneità di partecipazione.
Se hai completato gli studi, sei inoccupato e vuoi lavorare in un'azienda IT, per partecipare ad un percorso di accompagnamento al lavoro con la Skill Factory, invia il tuo curriculum a recruiting@skillfactory.it, verrai contattato da un nostro recruiter che risponderà alle tue domande e valutarà l'idoneità di partecipazione.
Per i giovani in cerca di lavoro crescono le opportunità d'impiego nel settore del Software Testing
![]() Gino Visciano |
Skill Factory - 16/06/2021 09:55:04 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 16/06/2021 09:55:04 | in Formazione e lavoro
 L'evoluzione digitale inevitabilmente sta favorendo il settore dello sviluppo software, questo oltre ad aumentare la domanda di programmatori, sta facendo crescere anche la richiesta di Software Tester.
L'evoluzione digitale inevitabilmente sta favorendo il settore dello sviluppo software, questo oltre ad aumentare la domanda di programmatori, sta facendo crescere anche la richiesta di Software Tester.
Il software, prima di essere immesso sul mercato, deve essere collaudato e testato, questa fase viene definita Software Testing ed è fondamentale per garantire la qualità del prodotto, la sua completezza ed affidabilità.
Il ruolo del Software Tester per un'azienda IT è molto importante, il team di testing è complementare al team dei programmatori e deve garntire che vengano rispettate le specifiche funzionali e non funzionali dei prodotti sviluppati.
Il Software Tester riveste un ruolo importante nel ciclo di vita di un software ed è fondamentale per l’immagine dell’azienda, perché il suo lavoro evita le cattive prestazioni del prodotto software e di conseguenza scongiura ricadute negative sul mercato, favorendo il business aziendale.
I compiti che un Software Tester svolge, sono principalemente questi:
- Pianifica e implementa strategie di testing;
- Disegna casi di test;
- Individua i malfunzionamenti del prodotto e le relative cause attraverso attività di debugging ed error fixing;
- Collabora con il team di sviluppo per correggere o migliorare il software;
- Scrive programmi di test per verificare la presenza di anomalie nel software;
- Utilizza strumenti software per automatizzare le procedure di testing.
Per svolgere il proprio lavoro il Software Tester deve avere le seguenti competenze tecniche:
- Conoscenza fondamentali dei linguaggi di programmazione utilizzati lato front-end e back-end, come ad esempio: C++, C#, Java, Python, PHP, Javascript, HTML/CSS;
- Conoscenza delle principali metodologie e paradigmi di sviluppo software;
- Esperienza con Linux e Windows, nonché con i principali strumenti di scripting;
- Conoscenza dei principali prodotti di Office Automation con la capacità di creare documentazione, report e collaborare in rete;
- Esperienza nell'analisi dei dati;
- Conoscenza del linguggio SQL e del funzionamento dei più importanti DBMS;
- Conoscenza del linguaggio UML;
- Conoscenza ed esperienza pratica con uno o più strumenti di gestione dei test (per esempio JIRA);
- Esperienza di test automation con JUnit e/o NUnit, Jenkins, Jmeter, SoapUI e/o Postman;
- Esperianza Selenium WebDriver & Cucumber.

COME DIVENTARE SOFTWARE TESTER
Se sei un giovane in cerca di lavoro, con conoscenze di base d'informatica, per diventare Software Tester è sufficiente partecipare alla prossima Skill Factory in modalità FAD, in partenza a luglio.
 L'obiettivo di questa Skill Factory è quello di formare gratuitamente Software Tester durante il mese di luglio ed inserirli presso un nostro partener IT di Napoli a settembre.
L'obiettivo di questa Skill Factory è quello di formare gratuitamente Software Tester durante il mese di luglio ed inserirli presso un nostro partener IT di Napoli a settembre.
Dopo aver frequentato la Skill Factory per Software Tester, potrai sostenere l'esame per acquisire la certificazione ISTQB, che certifica che hai le competenze per lavorare nell’ambito del Software Testing.
Per maggiori informazioni sulla certificazione ISTQB clicca qui.
Per partecipare gratuitamente alla Skill Fcatory di luglio, per Software Tester e lavorare presso un nostro partner IT di Napoli, invia il tuo curriculum all'indirizzo mail: recruiting@skillfactory.it
Buon primo maggio, con l'obiettivo d'impegnarci sempre di più per favorire l'inserimento dei giovani nel mondo del lavoro...
![]() Gino Visciano |
Skill Factory - 01/05/2021 15:13:29 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 01/05/2021 15:13:29 | in Formazione e lavoro
![]() Per chi come noi è impegnato quotidianamente a trasmettere competenze per creare posti di lavoro, la festa del primo maggio assume un'importanza particolare, perché sappiamo che il lavoro non si crea semplicemente con gli annunci e le buone intenzioni, ma per creare lavoro serve l'impegno e la sinergia di tutti gli attori che operano nel settore dell'istruzione, della formazione e delle politiche attive del lavoro.
Per chi come noi è impegnato quotidianamente a trasmettere competenze per creare posti di lavoro, la festa del primo maggio assume un'importanza particolare, perché sappiamo che il lavoro non si crea semplicemente con gli annunci e le buone intenzioni, ma per creare lavoro serve l'impegno e la sinergia di tutti gli attori che operano nel settore dell'istruzione, della formazione e delle politiche attive del lavoro.
Qualunque profilo professionale non nasce per caso, ma è il risultato di un percorso di crescita e sacrificio, che inizia con la scuola superiore e potrebbe anche non finire mai, perché come accade per tutte le cose, il cambiamento ci impone di acquisire continuamente nuove competenze per rimanere aggiornati ed essere al passo coi tempi.
Quando nel 2011 ho fondato la Skill Factory, avevo già un'esperienza di 25 anni nel settore della formazione IT, lavoravo come formatore per l'Olivetti, l'Elea, l'IBM, la Microsoft, la Sun Microsystem e la Oracle.
Ho deciso di abbandonare la mia attività professionale, per dedicarmi alla Skill Factory, perché ho capito che la formazione, se finalizzata all'inserimento dei giovani nel mondo del lavoro, è più gratificante.
Grazie alla scelta di fare formazione solo se finalizzata alla creazione di posti di lavoro, oggi tantissmi giovani possono acquisire gratuitamente le competenze che servono per entrare nel mondo del lavoro ed iniziare la loro carriera professionale presso uno dei nostri partner IT.
Chiudo questo articolo con un suggerimento per chi può assumere decisioni nell'ambito delle politiche attive del lavoro...
Il tirocinio extracurriculare è lo strumento più utilizzato dalle aziende per offrire ai giovani diplomati o laureati l'opportunità di apprendere direttamente in azienda le competenze pratiche necessarie per svolgere il proprio ruolo professionale e non solo! Naturalmente esiste una regolamentazione che definisce i limiti del numero di tirocinanti per azienda.
Almeno per questo periodo di difficoltà, eliminate il limite del numero dei tirocinanti che un'azienda può prendere in stage, offrendo una premialità alle aziende che trasformano i contratti di tirocinio in contratti di apprendistato e delle penalizzazioni a quelle che non lo fanno.
Buon primo maggio a tutti!!!
 FILTRI
FILTRI


 Offerte di Lavoro
Offerte di Lavoro
 Post più recenti
Post più recenti
-

Full Stack Developer
07/05/2026
-
1° MAGGIO: FESTA DEL LAVORO E DELLA FORMAZIONE
01/05/2026
-
Operatore Amministrativo Contabile
09/04/2026
-
Tecnico Programmatore: Il Profilo più richiesto dai giovani che frequentano la nostra Academy
17/03/2026
-
6.L'Assicurazione della Qualità nell'IFP
24/01/2026
-
Skill Factory 2025: Un anno di formazione tra "Innovazione (AI), Qualità (EQAVET) e Politiche Attive del Lavoro (PAR GOL)"
30/12/2025
-
10.Intelligenza Artificiale: cosa cambia nel mondo del lavoro
21/12/2025
-
5.L’etica della formazione come responsabilità professionale
13/12/2025
-
4.Buona Formazione: "Come assicurare la Qualità della Formazione"
06/12/2025
-
Corso gratuito di 60 ore per creare le competenze digitali fondamentali (DIGCOMP2.2)
25/09/2025