





-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-





 Scheda Azienda
Scheda Azienda Blog
Blog Eventi formazione
Eventi formazione Offerta formativa
Offerta formativa Offerte di lavoro
Offerte di lavoro Lavora con noi
Lavora con noi
 Richiedi informazioni
Richiedi informazioni
Skill Factory
Lista post > 5.Intelligenza Artificiale: IA Generativa
5.Intelligenza Artificiale: IA Generativa
![]() Gino Visciano |
Skill Factory - 01/12/2024 20:42:49 | in Home
Gino Visciano |
Skill Factory - 01/12/2024 20:42:49 | in Home
L'Intelligenza Artificiale generativa rappresenta una rivoluzione tecnologica che permette di aumentare le capacità intellettuali degli uomini; un grande passo avanti per migliorare la qualità delle attività che svolgiamo in ogni settore, perché ci permette di ridurre i tempi e i costi per gestirle.
 Oggi, gli LLM, oltre a comprendere il linguaggio naturale, possono anche creare contenuti di qualunque tipo, raggiungendo livelli di qualità molto realistici.
Oggi, gli LLM, oltre a comprendere il linguaggio naturale, possono anche creare contenuti di qualunque tipo, raggiungendo livelli di qualità molto realistici.
Questi modelli matematici sono capaci di gestire conversazioni complesse, possono supportaci durante le attività di brainstorming, ci aiutano a prendere decisioni, riescono a sintetizzare documenti, producono relazioni, fogli di calcolo e mail, scrivono codice con qualunque linguaggio di programmazione, generano contenuti artistici e di fantasia, possono interpretare il contenuto delle immagini e descriverlo in linguaggio naturale o da una descrizione sono capaci di generare un'immagine. Ad esempio, tutte le immagini di questo articolo sono state generate - attraverso una mia descrizione - dall'assistente virtuale COPILOT, che usa il modello DALL-E di OpenAI, specializzato nella generazione d'immagini.
I modelli linguistici di grandi dimensioni (LLM) hanno sviluppato queste capacità apprendendo enormi quantità dati. Praticamente riescono ad acquisire qualunque tipo d'informazioni digitale che trovano in Internet oppure che gli viene somministrata attraverso le attività di "Fine Tuning".
Più si addestrano sui dati e più diventano bravi, al punto che oggi alcuni modelli sono anche capci di superare il "Test di Turing".
Quello che è davvero sorprendente è che questi strumenti d'intelligenza artificiale, possono comprendere il sentiment espresso in un testo e capire se è positivo, negativo o neutro.
Ad esempio, guardate cosa riesce a fare l'assistente virtuale Perplexity con il testo seguente:
"Ieri Marco e Paola sono andati al supermercato e hanno comprato molti prodotti, alcuni a prezzi molto convenienti, altri un po' meno convenienti. Hanno acquistato 5 confezioni di affettati a 2 euro ciascuna, il presso è risultato conveniente, poi hanno acquistato 3 confezioni di pesto a 1 euro ciascuna, sempre al solito prezzo, quelle che sono risultate un po' care sono state le passate di pomodoro, ne prese 10 a 1,80 ciascuna.
Le cassiere sono state molto cortesi, un po' meno l'addetta alla salumeria, perché non gli ha dedicato la giusta attenzione. Il giudizio di Marco e Paola sul supermercato è buono."
Prompt 1


Prompt 2

Prompt 3

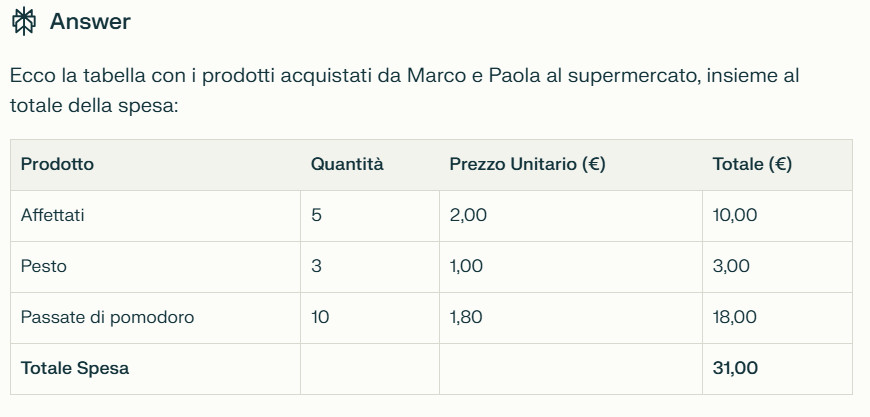
Prompt 4


Prompt 5

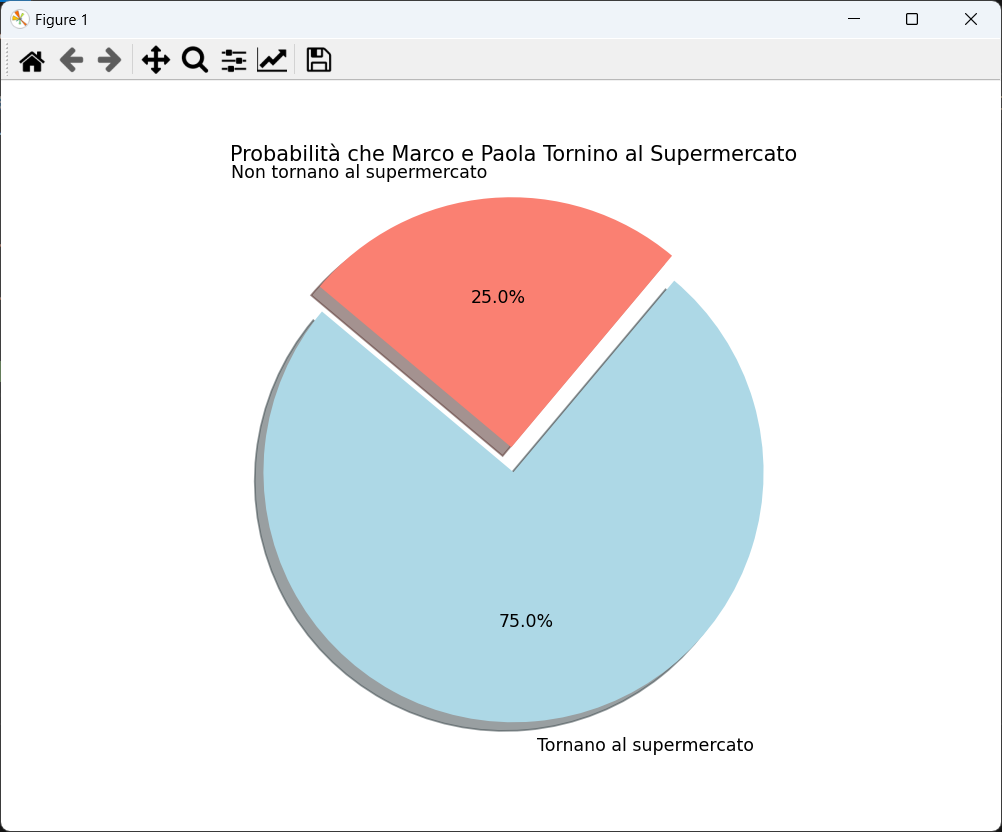
Dopo la richiesta, Perplexity ha generato il programma Python seguente:
import matplotlib.pyplot as plt
# Dati
labels = ['Tornano al supermercato', 'Non tornano al supermercato']
sizes = [75, 25] # Percentuali
colors = ['lightblue', 'salmon']
explode = (0.1, 0) # Esplodi il primo segmento
# Creazione del grafico a torta
plt.figure(figsize=(8, 6))
plt.pie(sizes, explode=explode, labels=labels, colors=colors,
autopct='%1.1f%%', shadow=True, startangle=140)
# Titolo del grafico
plt.title('Probabilità che Marco e Paola Tornino al Supermercato')
plt.axis('equal') # Assicura che il grafico sia un cerchio
# Mostrare il grafico
plt.show()
Questo è il grafico che ho ottenuto dopo l'esecuzione del codice Python:
ATTENTI AI BIAS

I dati utilizzati per addestrare gli LLM possono contenere pregiudizi questo potrebbe creare il problema dei bias.
A causa di questo problema, gli LLM potrebbero prendere decisioni discriminatorie o dare risposte che contengono pregiudizi, contribuendo a rafforzare stereotipi esistenti e creare disuguaglianze.
Anche gli algoritmi stessi possono introdurre bias, ad esempio se favoriscono determinate categorie di dati oppure le persone che progettano e utilizzano gli LLM possono introdurre i propri pregiudizi nelle fasi di sviluppo e utilizzo.
Il problema dei bias, può creare problemi etici e morali e rendere rischioso l'uso degli LLM.
Per mitigare il problema dei bias si devono utilizzare dati di addestramento diversificati e rappresentativi. Bisogna sviluppare algoritmi che siano meno suscettibili al problema e si devono valutare costantemente i modelli per individuare e mitigare i bias. Inoltre, bisogna rendere trasparenti i processi di sviluppo e di utilizzo degli LLM.
Quando usate gli LLM dovete essere consapevoli dell'esistenza dei bias e delle loro potenziali conseguenze. Chi usa un LLM deve sempre pensare in modo critico e a valutare le informazioni generate.
Conoscere il problema dei bias, significa diventare cittadini informati e consapevoli dei vantaggi e dei rischi dell'intelligenza artificiale.
LE ALLUCINAZIONI

Quando si parla di "allucinazioni" in riferimento agli LLM, non stiamo parlando di visioni o sensazioni simili a quelle umane. In questo contesto, un'allucinazione si verifica quando un LLM genera un testo che è:
Falso: Non corrisponde a fatti reali o a informazioni esistenti.
Incoerente: Non ha senso logico o contraddice informazioni precedentemente fornite.
Fuorviante: Può portare l'utente a credere in qualcosa di falso.
Le allucinazioni sono un fenomeno comune negli LLM e rappresentano una sfida importante per il campo dell'intelligenza artificiale. Tuttavia, grazie agli sforzi dei ricercatori, stiamo sviluppando sempre nuovi strumenti e tecniche per mitigare questo problema e rendere gli LLM più affidabili e utili.
Ci sono diverse ragioni per cui un LLM può generare allucinazioni:
Mancanza di conoscenza: L'LLM potrebbe non avere accesso a informazioni sufficienti per rispondere a una domanda in modo accurato.
Sovra-ottimizzazione: L'addestramento su grandi quantità di dati può portare l'LLM a "memorizzare" pattern e correlazioni che non sono necessariamente significative, generando risposte che sembrano plausibili ma sono in realtà errate.
Ambiguità: Il linguaggio naturale è intrinsecamente ambiguo e un LLM potrebbe interpretare una domanda in modo diverso da quello inteso dall'utente.
Limitazioni del modello: L'architettura stessa dell'LLM può introdurre dei bias che lo portano a generare risposte non accurate.
Addestramento su dati di alta qualità: Utilizzare dati accurati e diversificati per addestrare l'LLM.
Valutazione continua: Monitorare costantemente l'output dell'LLM e correggere eventuali errori.
Miglioramento dell'architettura: Sviluppare modelli più robusti e meno inclini alle allucinazioni.
Trasparenza: Rendere chiaro all'utente che l'LLM può generare risposte false e incoraggiarlo a verificare le informazioni.
I principali modelli utilizzati dai chatbot e dagli assistenti virtuali, sono quelli di tipo GPT, DALL-E e BERT oppure hanno le caratteristiche simili come ad esempio LLaMA.
Questi modelli d'intelligenza artificiale sono molto potenti e possono avere applicazioni diverse. La scelta del modello dipende dalle specifiche esigenze del tuo progetto.
MODELLI GPT

I modelli GPT (Generative Pre-trained Transformer) sono una delle tecnologie più avanzate nel campo dell'intelligenza artificiale generativa. Sono in grado di generare testi sorprendentemente coerenti e creativi, aprendo nuove frontiere in molti settori. Si basano sull'architettura Transformer, che è particolarmente efficace nel gestire sequenze di dati, come il linguaggio naturale.
Vengono addestrati su enormi quantità di testo, apprendendo le relazioni tra le parole e le strutture del linguaggio. Una volta addestrati, possono generare nuovi testi, traducendo, riassumendo, rispondendo a domande e molto altro.
Ad esempio, possono scrivere articoli di giornale, poesie, canzoni, script e codice sorgente e riescono a tradurre testi da una lingua all'altra con un alto grado di accuratezza. Sono capaci di riassumere lunghi documenti in pochi paragrafi, mantenendo le informazioni più importanti. Completano frasi o paragrafi iniziati dall'utente, generando testi coerenti e pertinenti.
I modelli GPT più conosciuti sono: GPT-4, sviluppato da OpenAI e Jurassic-1 Jumbo: sviluppato da AI21 Labs.
MODELLO DALL-E
OpenAi ha sviluppato anche DALL-E un modello di intelligenza artificiale che ha rivoluzionato il modo in cui pensiamo alla generazione di immagini.
DALL-E è un modello di deep learning che è stato addestrato su un enorme dataset di immagini abbinate a descrizioni testuali. Grazie a questo addestramento, è in grado di generare immagini originali e creative a partire da semplici descrizioni testuali. Puoi praticamente descrivere qualsiasi cosa tu possa immaginare, e DALL-E cercherà di tradurla visivamente.
Questo potente modello d'intelligenza artificiale può creare immagini estremamente realistiche, come fotografie di persone, animali, oggetti e scene ed è capace di generare anche immagini in stili artistici specifici, come impressionismo, cubismo, o anche stili inventati.
DALL-E è in grado di combinare concetti apparentemente non correlati, creando immagini uniche e sorprendenti.
Ad esempio, puoi chiedergli di creare un'immagine di "un gatto astronauta che guida una macchina volante":

DI seguito alcuni esempi di attività che si possono svolgere con DALL-E:
- Creare illustrazioni per libri e articoli;
- Progettare loghi e marchi;
- Generare concept art per film e videogiochi;
- Creare arte digitale unica;
- Assistere i designer nella creazione di nuovi prodotti.
MODELLI BERT

I modelli BERT (Bidirectional Encoder Representations from Transformers) sono un'altra pietra miliare nel campo dell'elaborazione del linguaggio naturale e dell'intelligenza artificiale generativa, sebbene si concentrino maggiormente sulla comprensione del linguaggio piuttosto che sulla generazione.
Come i GPT, utilizzano l'architettura Transformer, ma con un focus diverso; la caratteristica distintiva di BERT è la sua capacità di processare il testo in modo bidirezionale, considerando sia il contesto precedente che successivo di una parola. Questo gli permette di comprendere meglio il significato delle parole all'interno di una frase.
Anche BERT viene pre-addestrato su enormi quantità di testo, ma con un obiettivo diverso: comprendere il significato delle parole nel loro contesto.
Mentre i GPT sono eccellenti nella generazione di testo, le capacità generative di BERT sono più limitate e si concentrano principalmente sul significato di un testo, l'analisi del sentiment o classificazione di documenti.
Nel prossimo articolo vi parlerò dei modelli d'Intelligenza Artificiale locali e di come si possono addestrare.
1.Intelligenza Artificiale: se la conosci non la temi
2.Intelligenza Artificiale: i modelli linguistici di grandi dimensioni
3.Intelligenza Artificiale: le reti neurali artificiali
4.Intelligenza Artificiale: tipi di reti neurali artificiali
6.Intelligenza Artificiale: modelli pre-addestrati di IA locali
7.Intelligenza Artificiale: come creare una chatbot per conversare con Llama3
8.Intelligenza Artificiale: come addestrare LLAMA3 attraverso un Fine-Tuning di tipo no coding
9.Intelligenza Artificiale: cosa dobbiamo sapere su ai act e deepfake
10.Intelligenza Artificiale: Cosa cambia nel mondo del lavoro
