 Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy
Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy





Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy


-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-




 Scheda Azienda
Scheda Azienda Blog
Blog Eventi formazione
Eventi formazione Offerta formativa
Offerta formativa Offerte di lavoro
Offerte di lavoro Lavora con noi
Lavora con noi
 Richiedi informazioni
Richiedi informazioni
Skill Factory
Lista post > Big Data - Cosa sono e cosa cambia (terza parte)
Big Data - Cosa sono e cosa cambia (terza parte)
![]() Gino Visciano |
Skill Factory - 05/04/2019 00:02:53 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 05/04/2019 00:02:53 | in Formazione e lavoro
La piattaforma che offre il maggior numero di strumenti per la gestione dei Big Data è Hadoop, un ecosistema open source sviluppato da Apache Software Foundation.
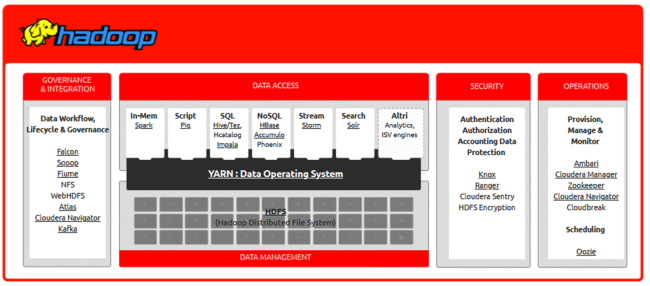
I motivi principali della diffusione di Hadoop sono i seguenti:
- per la sua flessibilità ad immagazzinare i dati indipendentemente dal fatto che siano strutturati o destrutturati;
- permette di processare i dati di natura complessa e di elevate dimensioni;
- è economico e scalabile rispetto ai sistemi di immagazzinamento dei dati tradizionali;
- è tollerante ai guasti (fault tolerant).
Hadoop offre strumenti per la gestione dei Big Data strutturati e destruturati permettendo la loro elaborazione sia in modalità batch, sia in modelità streaming (aggiornamento dei dati in tempo reale on line).
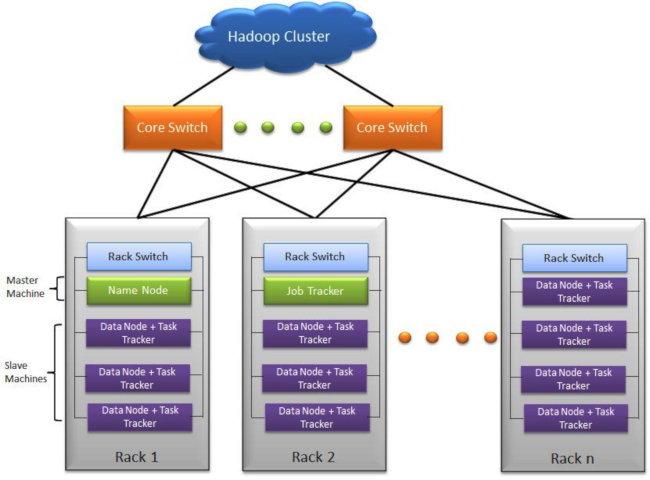
La caratteristica principale di questo framework è quella di essere scalabile orizzontalmente (MPP - Massively Parallel Processing), in pratica Hadoop sfrutta le potenzialità offerte da un cluster di computer, detti nodi, su cui vengono distribuiti dati e gestiti i processi di lavoro sincronizzati.
Ciascuno dei Computer che appartengono al Cluster è chiamato nodo, esistono due tipologie di nodi nell’architettura Hadoop: il nodo master ed il nodo slave.
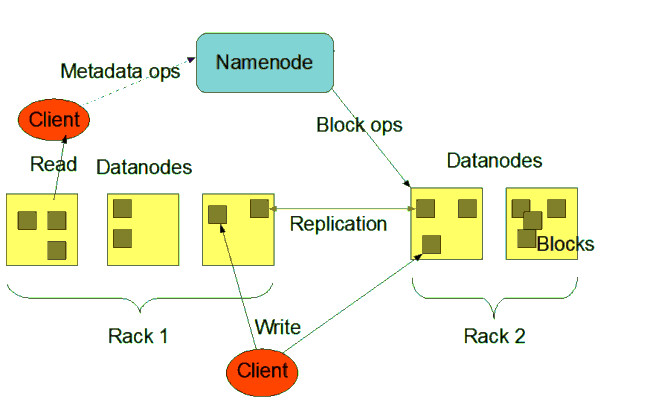
Il nodo master (Namenode) controlla tutti i nodi slave (Datanode), è qui che le informazioni vengono immagazzinate in blocchi.
I blocchi sono gestiti direttamente dal nodo master ed hanno una dimensione minima di 128MB.
Hadoop per essere tollerante ai guasti, replica i blocchi su più nodi, in modo da poter essere recuperati in caso di errori.
ARCHITETTURA DI HADOOP
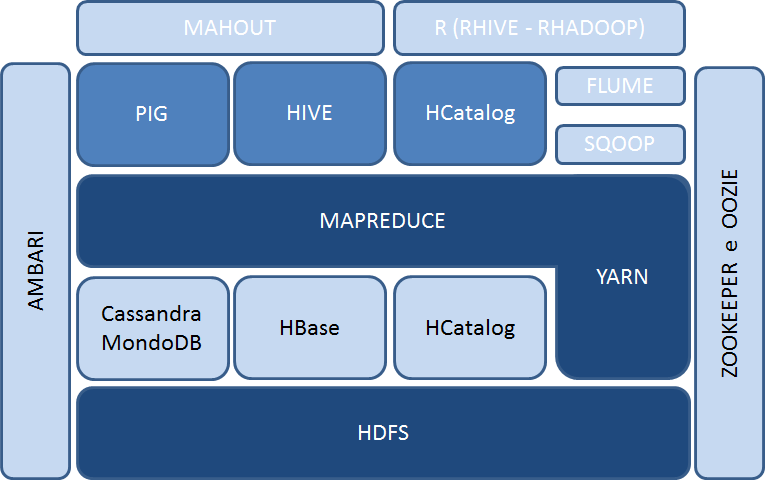
L'architettura di Hadoop può essere divisa in quattro parti fondamentali:
1) HDFS
2) MAPREDUCE
3) YARN
4) STRUMENTI PER GESTIRE ED ANALIZZARE BIG DATA
HDFS
L'HDFS è il File System distribuito di Hadoop, permette di distribuire file di grandi dimensioni in blocchi registrati sui DataNode associati ai nodi di tipo slave del Cluster, in pratica è un grande virtual storage, tollerante ai guasti, è lui che gestisce le repliche dei blocchi tra nodi per evitare la perdita di dati.
MAPREDUCE
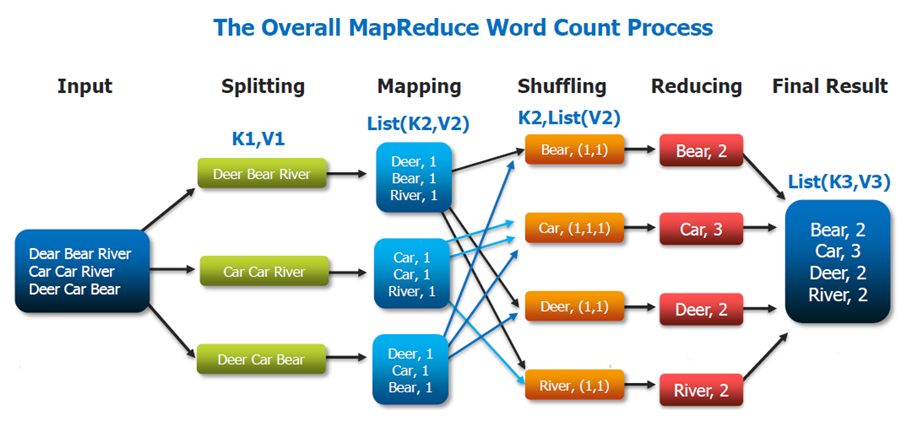
MapReduce è popolare grazie a Google che lo utilizza per elaborare ogni giorno molti petabyte di dati. Il modello di MapReduce è costituito da due programmi scritti dall’utente, chiamati map e reduce e da un framework che abilita l’esecuzione di un grande numero di istanze di ciascun programma sui diversi nodi del cluster.
Il programma map legge un insieme di record da un file di input, svolge le operazioni di ETL, quindi produce una serie di record di output nella forma (chiave, dati).
Mentre il programma map produce questi record, una funzione separata li organizza in contenitori multipli e indipendenti, applicando una funzione alla chiave di ciascun record, questa funzione è tipicamente hash, sebbene sia sufficiente qualsiasi tipo di funzione deterministica. Una volta che il contenitore è pieno, il suo contenuto viene salvato sul disco.
Il programma map termina producendo una serie di file di output, uno per ciascun contenitore.
Dopo essere stati raccolti dal framework map-reduce i record di input vengono raggruppati per chiavi (attraverso operazioni di sorting o hashing) e sottoposti al programma reduce.
Il programma reduce esegue una elaborazione dei dati attraverso un linguaggio general purpose, come ad esempio Java, Scala oppure Python. Cascuna istanza reduce può scrivere record in un file di output e quest’ultimo rappresenta una parte della risposta elaborata da MapReduce.
La coppia chiave/valore prodotta dal programma map può contenere qualsiasi tipo di dati nel campo assegnato al valore del campo. Google, per esempio, utilizza questo approccio per indicizzare grandi volumi di dati non strutturati.
Le coppie chiave/valore utilizzate nell’elaborazione MapReduce possono essere archiviate in un file o in un database che sfruttano la logica di coppie chiave/valore.
YARN
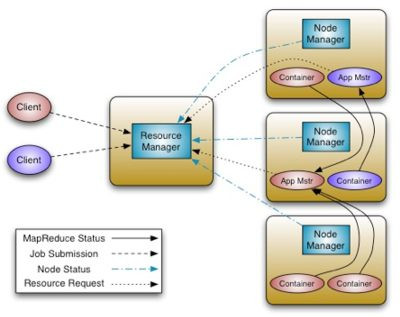
YARN (Yet Another Resource Negotiator) gestisce le risorse del Cluster, come ad esempio la memoria e la CPU, la larghezza di banda della rete e lo spazio di archiviazione disponibile e monitora l’esecuzione delle applicazioni. Rispetto alla prima versione di MapReduce è ora un sistema molto più generico, infatti la seconda versione di MapReduce è stata riscritta come applicazione YARN, con alcune sostanziali differenze.
YARN offre chiari vantaggi in termini di scalabilità, efficienza e flessibilità rispetto al classico motore MapReduce nella sua prima versione.
Le applicazioni da eseguire si chiamano Application Master, il Resource manager richiede la possibilità di installare l’application master sul cluster.
Il Resource manager richiede a un nodo del cluster la creazione di un container per eseguire l'applicazione. Al container è associato un determinato ammontare di risorse RAM e CPU, per evitare di bloccare il nodo.
Una volta in esecuzione, il master si moltiplica, richiedendo a sua volta al resource manager (tramite le apposite API di YARN) altri container su altri nodi su cui lanciare le varie copie dell’applicazione distribuita.
L’application master a sua volta manda segnali di heartbeat al resource manager per indicare di essere ancora vivo e funzionante.
Un esempio di una applicazione YARN è proprio MapReduce. In questo caso l’Application Master è il JobTracker mentre le varie repliche lanciate sui vari container sono i vari TaskTracker (mapper o reducer).
MapReduce è un Application Master già disponibile in YARN, in modo da mantenere un minimo di retro-compatibilità con Hadoop 1.0 (la retro compatibilità non è però garantita).
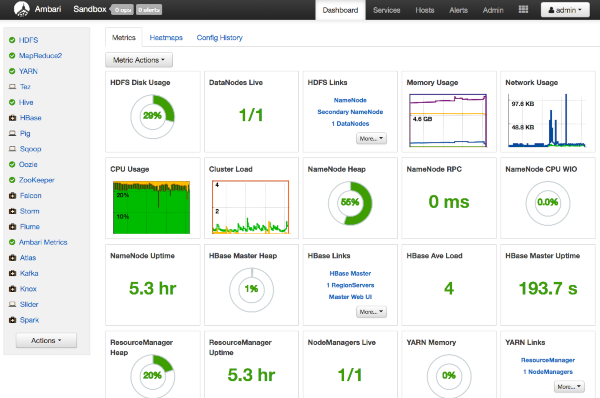
AMBARI
Ambari semplifica la gestione ed il monitoraggio di un cluster Apache Hadoop grazie ad un'interfaccia utente Web facile da usare. Ambari è usato per monitorare il cluster e modificare la configurazione di Hadoop.
HCATALOG
HCatalog presenta agli utenti una vista tabellare dei dati presenti in HDFS, indipendentemente dal formato di origine, rendendo più semplice la creazione e la modifica dei metadati.
PIG
È un linguaggio di scripting evoluto che consente di bypassare le difficoltà di approccio al framework MapReduce grazie a una sintassi semplice, ma al tempo stesso potente e efficace. Al momento dell’esecuzione lo script Pig viene automaticamente tradotto in uno o più job Tez o MapReduce2.
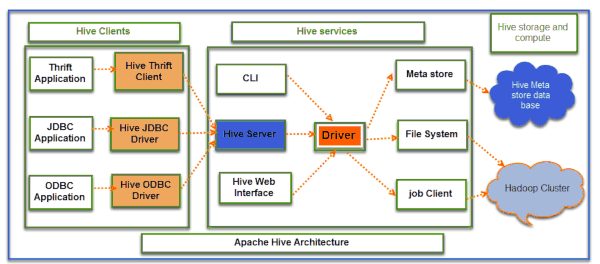
HIVE
Hive consente di creare l’infrastruttura necessaria a gestire un completo data warehouse on top of Hadoop. Hive si posiziona all’interno del batch layer di Hadoop e consente di gestire sia dati strutturati che destrutturati immagazzinati all’interno del Blob Storage. Utilizza un linguaggio SQL-like chiamato HiveQL. È ideale per qualsiasi tipo di analytics di tipo non transazionale.
HBASE
HBase è il database NoSQL di Hadoop: utilizza HDFS per immagazzinare i dati ed è totalmente scalabile su tutti i nodi del cluster stesso di Hadoop. Utilizza un modello key-value dove i dati sono distribuiti secondo una mappa key-value ordinati per key. Può contenere miliardi di righe e milioni di colonne.
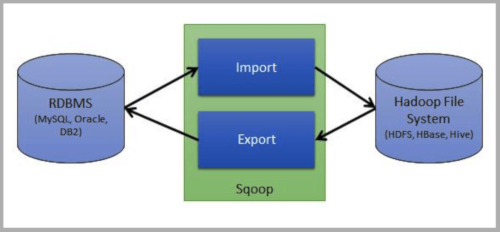
SQOOP
Sqoop è l’ETL nativo di Hadoop. Consente l’accesso a sistemi RDBMS esterni, la lettura automatica dello schema e l’ingestion dei dati all’interno di HDFS. Grazie all’utilizzo del framework MapReduce2 qualsiasi data ingestion basata su Sqoop è scalabile e altamente performante.
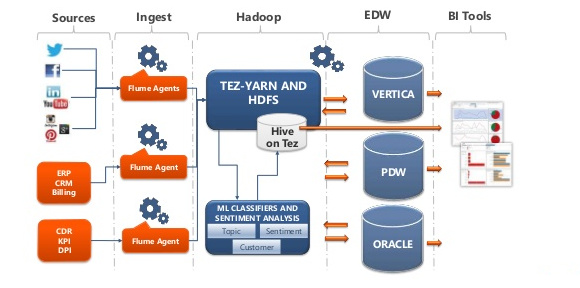
FLUME
Flume è uno dei principali tool di data ingestion dell’ecosistema Hadoop per la raccolta, l’aggregazione, il controllo e l’immagazzinamento di stream di dati (tipicamente machine data) all’interno di HDFS.
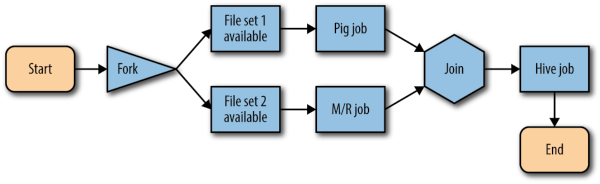
OOZIE
Oozie è uno schedulatore di workflow che risiede e opera all’interno di Hadoop: è in grado di gestire, controllare e concatenare job MapReduce2, Sqoop, Hive e Pig e può essere utilizzato sia all’interno di un batch layer che di uno speed layer.
ZOOKEEPER
È un servizio centralizzato per la gestione delle configurazioni, la creazione di ensemble per i servizi di naming e group e la sincronizzazione delle distribuzioni di informazioni (es: transazioni distribuite). Molti servizi dell’ecosistema di Hadoop dipendono da ZooKeeper (es: HBase e NameNode HA).
