 Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy
Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy





Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy


-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-




 Scheda Azienda
Scheda Azienda Blog
Blog Eventi formazione
Eventi formazione Offerta formativa
Offerta formativa Offerte di lavoro
Offerte di lavoro Lavora con noi
Lavora con noi
 Richiedi informazioni
Richiedi informazioni
Skill Factory
Lista post > Big Data - Cosa sono e cosa cambia (seconda parte)
Big Data - Cosa sono e cosa cambia (seconda parte)
![]() Gino Visciano |
Skill Factory - 16/03/2019 00:16:42 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 16/03/2019 00:16:42 | in Formazione e lavoro
 Tutte le volte che interagiamo con un dispositivo connesso ad Internet, consapevolmente ed a volte anche inconsapevolmente, produciamo dati.
Tutte le volte che interagiamo con un dispositivo connesso ad Internet, consapevolmente ed a volte anche inconsapevolmente, produciamo dati.
Le aziende lavorano ed analizzano i nostri dati principalmente per ottenere un vantaggio competitivo.
Il mercato dei Big Data è in forte crescita perché le aziende, sempre di più, richiedono l'uso di questo strumento per i seguenti motivi:
- Aumentare il fatturato attraverso la crescita delle vendite;
- Rendere prevedibile lo sviluppo della domanda, basandosi sui comportamenti dei clienti;
- Dare più valore all’account management analizzando le operazioni tra venditori e clienti e prevedere ciò che è meglio fare per un qualsiasi cliente;
- Aprire nuove opportunità di business, per chi voglia allargare il mercato puntando su clienti relativamente nuovi.
Quando ai Big data si uniscono gli analytics è possibile:
- Determinare, quasi in tempo reale, le cause di guasti, avarie o difetti;
- Creare offerte nei punti vendita basate sulle abitudini dei clienti;
- Ricalcolare interi portafogli di rischio in pochi minuti;
- Individuare comportamenti fraudolenti prima che colpiscano la propria organizzazione.
Si usano quattro modelli di analytics:
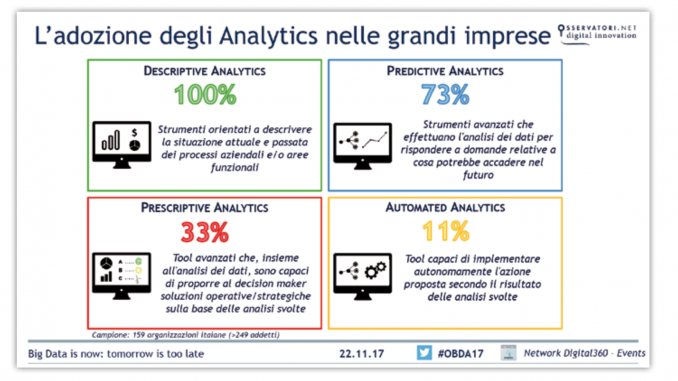
Descriptive Analytics: strumenti orientati a descrivere la situazione attuale e passata dei processi aziendali e/o aree funzionali. Tali strumenti permettono di accedere ai dati secondo viste logiche flessibili e di visualizzare in modo sintetico e grafico i principali indicatori di prestazione;
Predictive Analytics: strumenti avanzati che effettuano l’analisi dei dati per rispondere a domande relative a cosa potrebbe accadere nel futuro; sono caratterizzati da tecniche matematiche quali regressione, forecasting, modelli predittivi, ecc;
Prescriptive Analytics: applicazioni big data avanzate che, insieme all’analisi dei dati, sono capaci di ottenere soluzioni operative/strategiche sulla base delle analisi svolte;
Automated Analytics: capaci di implementare autonomamente l’azione proposta secondo il risultato delle analisi svolte (Machine Learning).
I Big Data possono essere analizzati in due modalità diverse:
1 - Batch: in questa modalità i dati da analizzare vengono aggiornati ad intervalli periodici, è una modalità tipica del Data warehouse
2 - Streaming: in questa modalità i dati da analizzare vengono aggiornati in tempo reale, modalità tipica dell'IoT.
Per individuare i modelli di utilizzo degli Analytics è necessaria anche definire le tipologie di dati da analizzare che possono essere principalmente di due tipi:
1 - dati strutturati: organizzati in tabelle o modellati in formati tipo XML, JSON, BSON e CSV.
2 - dati destrutturati.
I dati destrutturati sono tipicamente:
- testo;
- immagini;
- video;
- audio;
- elementi di calcolo.
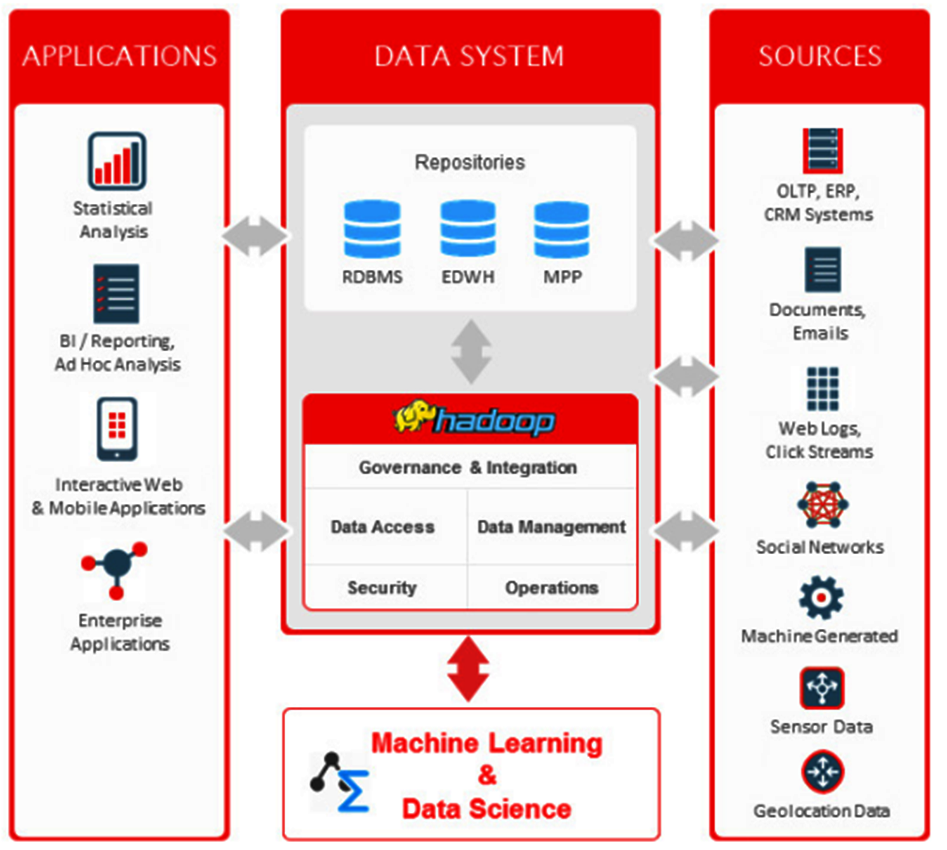
L'immagine seguente descrive l'ecosistema Hadoop, la piattaforma che offre tutti gli strumenti necessari per gestire grandi quantità di dati.
Lo schema mette in relazione tra loro tutti i livelli fondamentali per la lavorazione e l'analisi di Big Data.
I diversi tipi di repositories disponibili, possono essere alimentati da sorgenti di dati differenti attraverso processi di caricamento (ETL/ELT) di tipo batch o streaming.
La grande quantità di dati caricati, attraverso il filesystem distribuito HDFS, può essere immagazzinata sui nodi del cluster Hadoop, rappresentato da un insieme di computer, detti nodi, che condividono i propri dischi, creando un'unica grande memoria di massa.
Utilizzando strumenti come MapReduce, i Big Data possono essere mappati e ridotti, il risultato di questo lavoro potrà essere analizzato dalle diverse applicazioni diponibili oppure potrà essere interessato ad operazioni di Machine Learning.
La potenza di calcolo richiesta per l'esecuzione dei JOB di map reduce e di analasi viene fornita dalle CPU dei computer del cluster Hadoop, attraverso multiprocessi paralleli (MPP) gestiti da YARN di Hadoop.
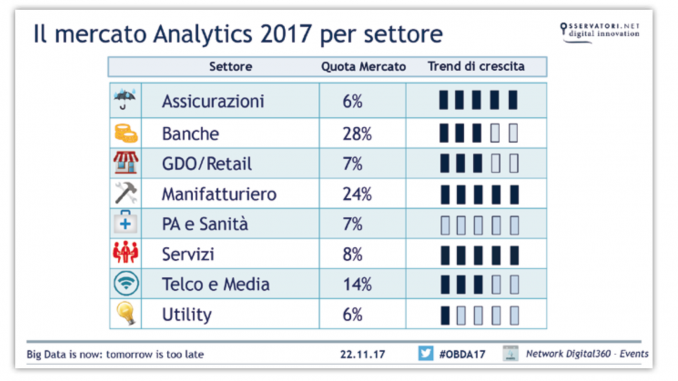
Attualmente esistono esperienze d'implementazione di progetti di Big Data Analytics in medie e grandi aziende dei seguenti settori:
La figura professionale che in azienda si occupa delle strategie per gestire grandi quantità di dati e della loro interpretazione è il Data Scientist.
Per svolgere questo ruolo bisogna avere competenze in ingegneria, informatica, statistica, economia e matematica, in particolare è richiesta la conoscenza dei seguenti linguaggi di programmazione:
- Java
- Scala
- R
- Python
e la capacità di sviluppare ed implementare algoritmi di Machine Learning.
In Italia un Data Scientist può guadagnare oltre €30.000,00 all'anno, in funzione del livello di seniority raggiunto.
DIFFERENZA TRA DATA ANALYST E DATA SCIENTIST
 Il Data Analyst è colui che esplora, analizza e interpreta i dati, con l’obiettivo di estrapolare informazioni utili al processo decisionale, da comunicare attraverso report e visualizzazioni ad hoc.
Il Data Analyst è colui che esplora, analizza e interpreta i dati, con l’obiettivo di estrapolare informazioni utili al processo decisionale, da comunicare attraverso report e visualizzazioni ad hoc.
Il Data Analyst parte dal lavoro svolto dal Data Scientist per trasmettere e interpretare le informazioni al fine di supportare gli utenti con cui collabora.
Questa figura professionale non proviene da un percorso estremamente tecnico, è preferibile anzi che abbia compiuto studi economico-manageriali, in modo da poter parlare lo stesso linguaggio delle figure di business con cui andrà ad interfacciarsi.
Lo stipendio medio di un Data Analyst in Italia è di circa €27.000 all'anno.
PRINCIPALI STRUMENTI PER L'ANALISI DEI DATI
Gli strumenti di analisi dei dati, anche detti di front-end, più richiesti dalle aziende sono: Tableau, Qlik e Power BI, cliccate sui loghi per accedere ai siti ufficiali.



