Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy
Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy





Utilizziamo i cookie per assicurarti la migliore esperienza nel nostro sito. Questo sito utilizza cookie anche di terze parti.
Cookie policy


-

-

- AULE GRUPPI
-
 Le Tue Aule
Le Tue Aule
-
 I Tuoi Gruppi
I Tuoi Gruppi
-
 Le Tue Selezioni
Le Tue Selezioni
-




 Scheda Azienda
Scheda Azienda Blog
Blog Eventi formazione
Eventi formazione Offerta formativa
Offerta formativa Offerte di lavoro
Offerte di lavoro Lavora con noi
Lavora con noi
 Richiedi informazioni
Richiedi informazioni
Skill Factory
Lista post > Big Data - Cosa sono e cosa cambia (prima parte)
Big Data - Cosa sono e cosa cambia (prima parte)
![]() Gino Visciano |
Skill Factory - 09/02/2019 10:06:22 | in Formazione e lavoro
Gino Visciano |
Skill Factory - 09/02/2019 10:06:22 | in Formazione e lavoro
 Le nuove tecnologie, come ci insegna la storia, inevitabilmente impattano sulle nostre abitudini e finiscono per modificare i nostri comportamenti sociali, culturali e commerciali.
Le nuove tecnologie, come ci insegna la storia, inevitabilmente impattano sulle nostre abitudini e finiscono per modificare i nostri comportamenti sociali, culturali e commerciali.
Da quando abbiamo iniziato ad utilizzare i Personal Computer, le reti ed Internet, i nostri ritmi di vita sono cambiati radicalmente, soprattutto dopo la diffusione dei dispositivi mobile e dell'IoT (Internet of things - Internet delle cose), sono aumentate le interazioni tra le macchine e le persone e la quantità di dati prodotti.
Questa grossa quantità di dati creati dalla Rete presenta il problema dell'archiviazione e della gestione per ricavarne informazioni utili.
Dagli anni '50 in poi, i supporti di archiviazione dati, sono diventati sempre più capienti. Nel 1956 fece la sua comparsa il primo disco rigido della storia, ideato dalla IBM, conteneva appena 5 megabyte di dati. Negli anni '80, sono nati i CD-ROM che potevano contenere fino a 700 megabyte, sostituiti negli anni '90 dai DVD che avevano una capacità di circa 5 gigabyte e successivamente dalle chiavette USB con una capacità di 125 gigabyte.
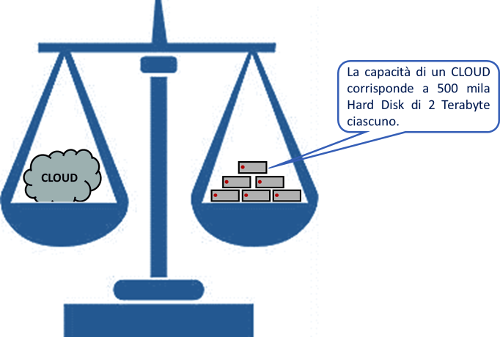
L'esigenza di memorizzare sempre maggiori quantità di dati, ha favorito la nascita di servizi Cloud Storage, che offrono la possibilità agli utenti di salvare i propri dati online ed accedervi da qualunque luogo dotato di una connessione al web.
Secondo alcuni calcoli, nel cloud risiederebbero sino a 1 exabyte di dati, più o meno come 500 mila hard disk da 2 terabyte.
DA QUALE LIMITE IN POI SI PUO' INIZIARE A PARALRE DI BIG DATA?
Per Big Data s'intende un'elevatissima quantità di dati non strutturati, provenienti da oggetti differenti che registrano i comportamenti delle persone e delle macchine. Si inizia a parlare di Big Data quando si raggiungo unità di misura dell'ordine di petabyte oppure exabyte.
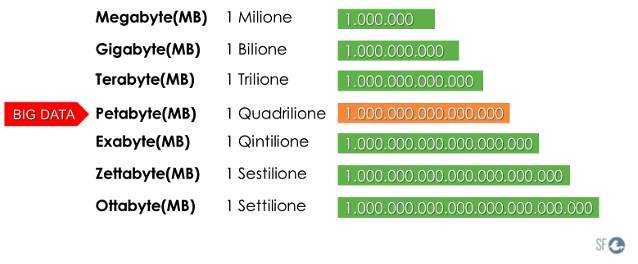
I Petabyte e gli exabyte sono unità di misura grandissime, che richiedo spazi di archiviazione molto capienti, per questo motivo chi gestisce i Big Data deve utilizzare servizi di Cloud Storage.
Naturalmente di fronte a questi ordini di grandezze, non solo occorrono storage con grosse capacità di archiviazione, ma servono anche sistemi in grado di distribuire i processi di calcolo per gestire ed analizzare le grosse quantità di dati archiviate. L'analisi di questi dati presuppone quindi l'impiego di una piattaforma software che consente di distribuire complessi compiti di computing su una grande quantità di nodi.
I Big Data sono diversi dai normali dataset raccolti nei database tradizionali, perché devono avere caratteristiche particolari che si possono riassumere con "5 V":
1-Volume
Grossa quantità di dati
2-Varietà
Fonti differenti non strutturati
3-Velocità
Tempi brevi di analisi
4-Validazione (Veracità)
I dati devono essere affidabili
5-Valore (Supporto decisionale)
Devono servire per comprendere o analizzare
In quest’ambito Apache Hadoop, un framework che si presenta come la base di molte distribuzioni e applicazioni per i Big Data, rientra tra le soluzioni più conosciute.

DIFFERENZA TRA DATI STRUTTURATI E NON STRUTTURATI
I modelli di dati tradizionali si basano soprattutto sull'organizzazione dei dati in tabelle formate da righe e colonne, relazionate tra loro, che possono essere gestite ed interrogate con il linguaggio SQL, utilizzando i classici RDBMS come MySQL, PostgreSQL, Oracle e SQL Server.
I modelli non strutturati si basano su una rappresentazione di dati schemaless, non definita e possono cambiare nel tempo, quindi non possono essere gestiti con i normali RDBMS ed il linguaggio SQL.
I database NoSQL si differenziano da quelli SQL per il modo in cui immagazzinano i dati e, conseguentemente, come li presentano all’utente.

I tipi più comuni di NoSQL sono sostanzialmente 4:
- Orientati alle colonne (column-oriented)
- Orientati ai documenti (Document Store)
- A coppie chiave-valore (Key Value Store)
- A grafo (Graph)
DATABASE NOSQL ORIENTATI ALLE COLONNE
La differenza tra classici database relazionali, e questo tipo di database è quella che le informazioni sono salvate per colonna.
Prendiamo come esempio la tabella seguente:
| PersonaID | Nome | Cognome | Eta |
| 1 | Mario | Rossi | 30 |
| 2 | Ugo | Verdi | 35 |
| 3 | Franco | Bianchi | 40 |
In un classico database relazionale i dati verrebbero serializzati nel modo seguente:
1, Mario, Rossi, 30, 2, Ugo, Verdi, 35, 3, Franco, Bianchi, 40
Nei database orientati alle colonne invece si avrebbe:
1, 2, 3, Mario, Ugo, Franco, Rossi, Verdi, Bianchi
Se i dati sono immagazzinati per colonne, in caso di analisi dei dati (OLAP) l’aumento di performance è notevole.
I Databse NoSQL orientati alle colonne più usati sono i seguenti:
- Apache Cassandra
- Apache HBase
- Google BigTable
DATABASE NOSQL ORIENTATI AI DOCUMENTI
In questa categoria rientrano i database che permettono la manipolazione dei dati semi-strutturati. In genere questi database usano una rappresentazione interna che può variare tra XML, JSON, BSON o YAML e in genere forniscono un accesso tramite REST API.
Volendo fare un confronto con i database relazionali, possiamo affermare che un documento corrisponde ad una riga; tuttavia questo documento, a differenza della riga, può non avere uno schema preciso.
Riprendendo l’esempio precedente, potremmo avere una situazione del genere:
{
id: 1,
nome: "Mario",
cognome: "Rossi",
eta:30,
Laureato: true
},
{
id: 2,
nome: "Ugo",
cognome: "Verdi",
eta:35
}
{
id: 3,
nome: "Franco",
cognome: "Bianchi"
}
I Databse NoSQL orientati ai documenti più usati sono i seguenti:
-BaseX
-MongoDB
-CouchDB
DATABASE NOSQL DI TIPO CHIAVE-VALORE
I database di tipo chiave-valore sono simili a quelli orientati ai documenti, perché non richiedono l’esistenza di uno schema e allo stesso modo, si associa a una data chiave, un determinato valore.
La differenza sostanziale tra i database chiave-valore e quelli orientati ai documenti risiede nel modo in cui le chiavi vengono gestite, infatti si hanno due punti in cui le due soluzioni divergono:
La chiave deve sempre essere specificata
I valori associati ad una chiave non possono essere indicizzati né è possibile interrogarli.
Volendo fare un paragone con le strutture dati tipiche di un qualsiasi linguaggio di programmazione, si potrebbe dire che i database di tipo chiave-valore sono equivalenti ad una Hash Table.
Questi database tendono ad essere in-memory per avere le migliori performance possibili esono in grado di rispondere a decine di migliaia di richieste al secondo.
I Databse NoSQL di tipo chiave-valore più usati sono i seguenti:
-Redis
-Memcached
-Voldemort
DATABASE NOSQL A GRAFO
Nei database a grafo le entità sono rappresentate dai nodi di un grafo, collegati tra loro tramite relazioni. Questi tipi di database trovano piena utilità in quei contesti in cui la relazione tra le entità è il dato importante e porta con sé informazioni, come ad esempio relazioni sociali tra persone, trasporti o topologie di rete.
Questi tipi di database hanno un contesto applicativo piuttosto ristretto e facilmente identificabile in fase di design, non è tuttavia raro che i dati di per sé vengano memorizzati in un database orientato ai documenti, utilizzando il grafo solo per rappresentare le relazioni.
I Databse NoSQL a grafo più usati sono i seguenti:
-Neo4j
-FlockDB
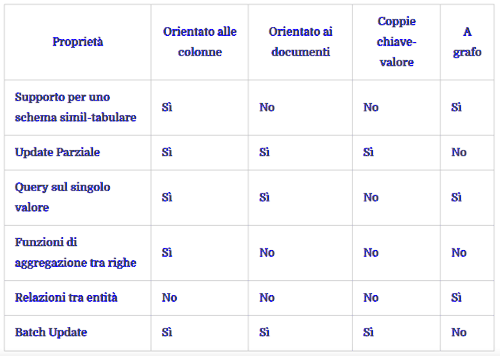
La tabella seguente riassume le caratteristiche dei database NoSQL e ne favorisce la scelta: